最近,DeepSeek可以说是火遍大江南北,其强大的推理能力,无疑是我们工作生活的好帮手。但超高的热度也带来了甜蜜的烦恼,它的官网经常出现“服务器繁忙”的提示,原因是承载能力有限。
那怎么样把不卡顿,不繁忙的DeepSeek“种”在自己的电脑或者手机里呢?今天就给大家分享两种方法。
1、硅基流动API调用法
这种方法的优势:不挑配置,网页、手机端都能用,响应速度也比较快,能用满血版模型(671B的DeepSeek)
这种方式的不足:需要联网,极少数时候响应偏慢(也是因为用的人太多了),要付费(不多)。
硅基流动是一个AI云技术平台,你可以理解为,它在云端部署了诸如DeepSeek、Stable Diffusion这样的模型,开发者和个人用户可以通过调用它的api,来使用这些模型。
首先,打开硅基流动官网:
https://cloud.siliconflow.cn/i/vaWtvcpf
这是我的邀请链接(没收它家的钱),可以用它注册一个账号(我的邀请码:vaWtvcpf)
如果首次注册忘记输入邀请码了,第二次登录前再输出邀请码,也是可以享受2000万Tokens的!
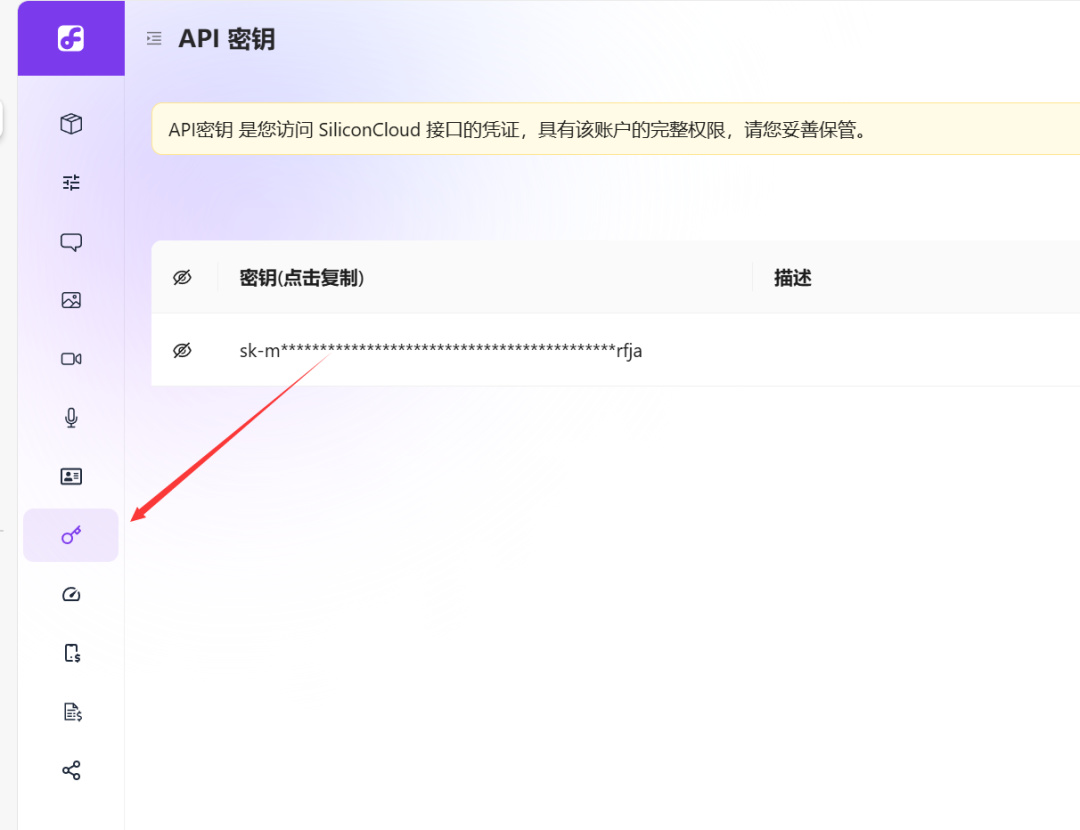
注册完成之后,来到“模型广场官网”,点击左下角“小钥匙”这里:
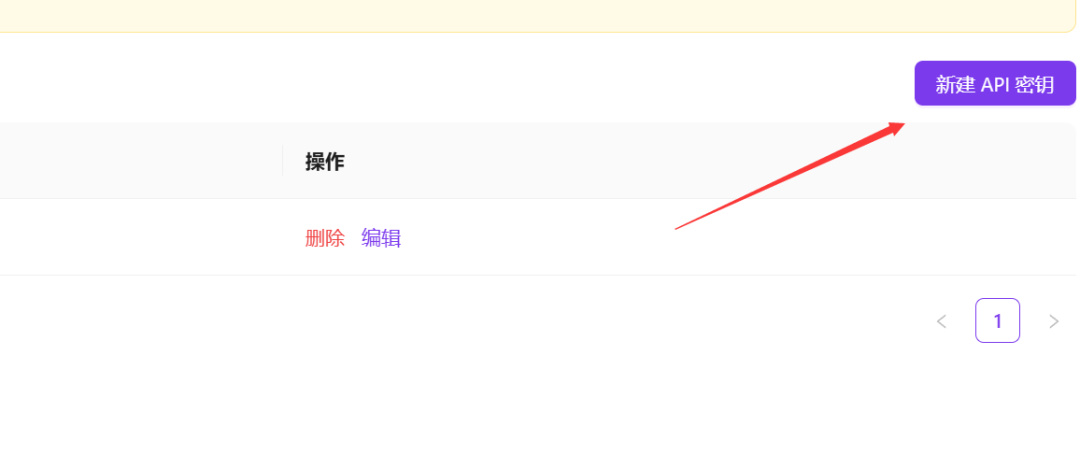
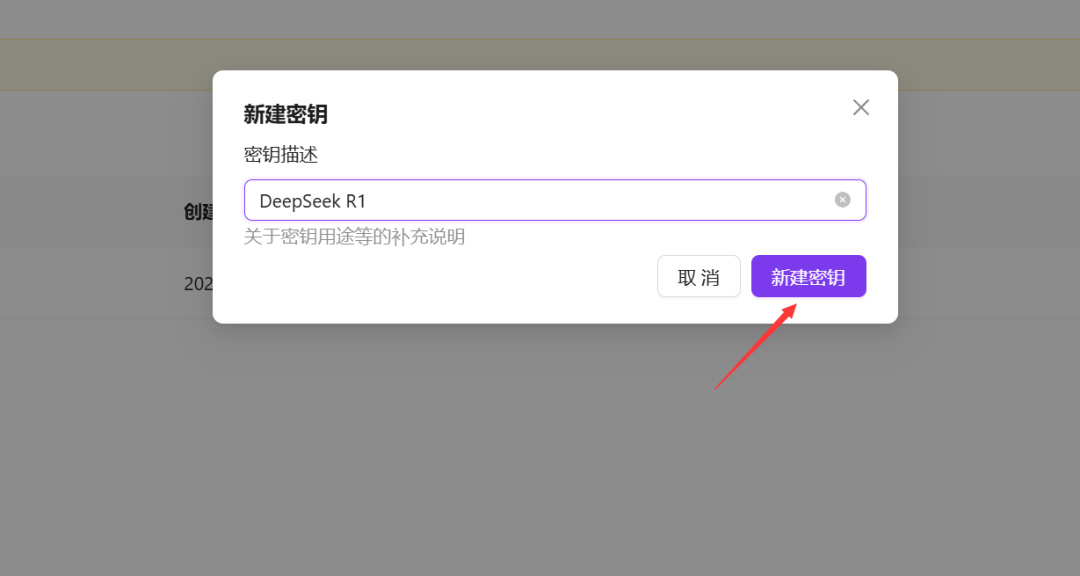
再点击右上角“新建API密钥”,新建一个API密钥,名字随意。
注册好了之后,如果是网页端,可以使用ChatBox:
https://chatboxai.app/zh#download
直接进入网页端,点击左下角“设置”按钮:
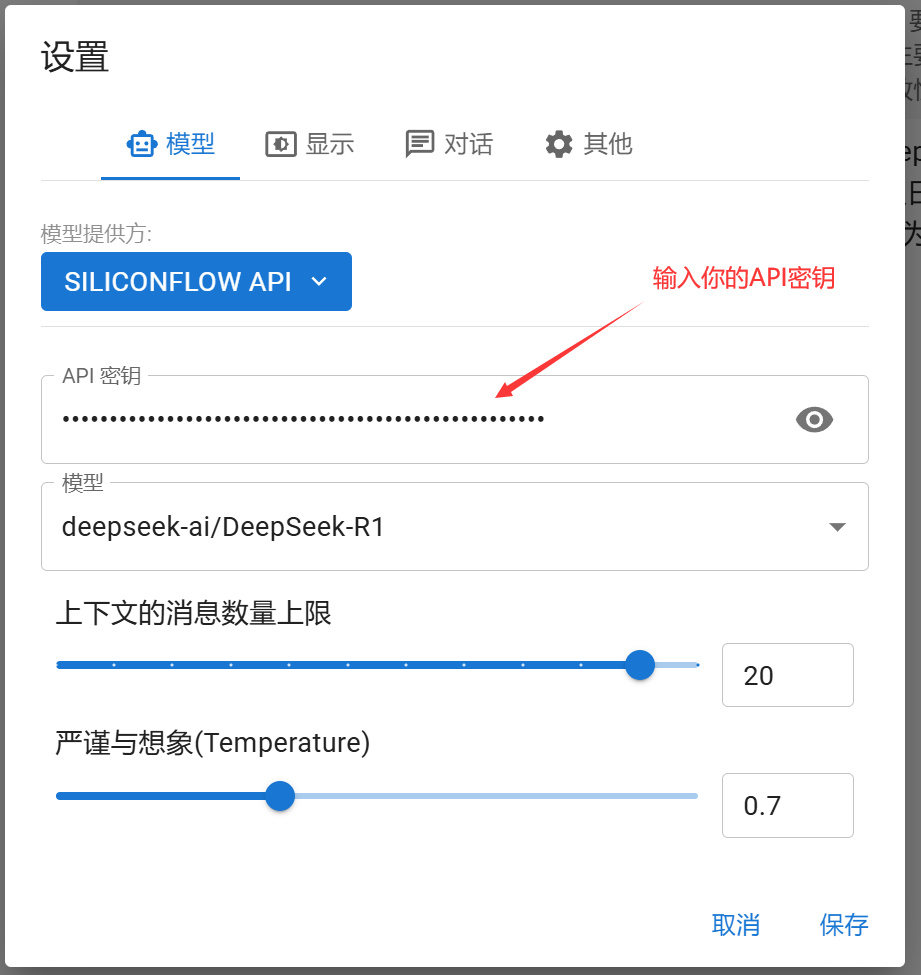
模型选“DeepSeek-R1”,不要选Pro开头那个:
然后返回对话页面,就能开始用了:

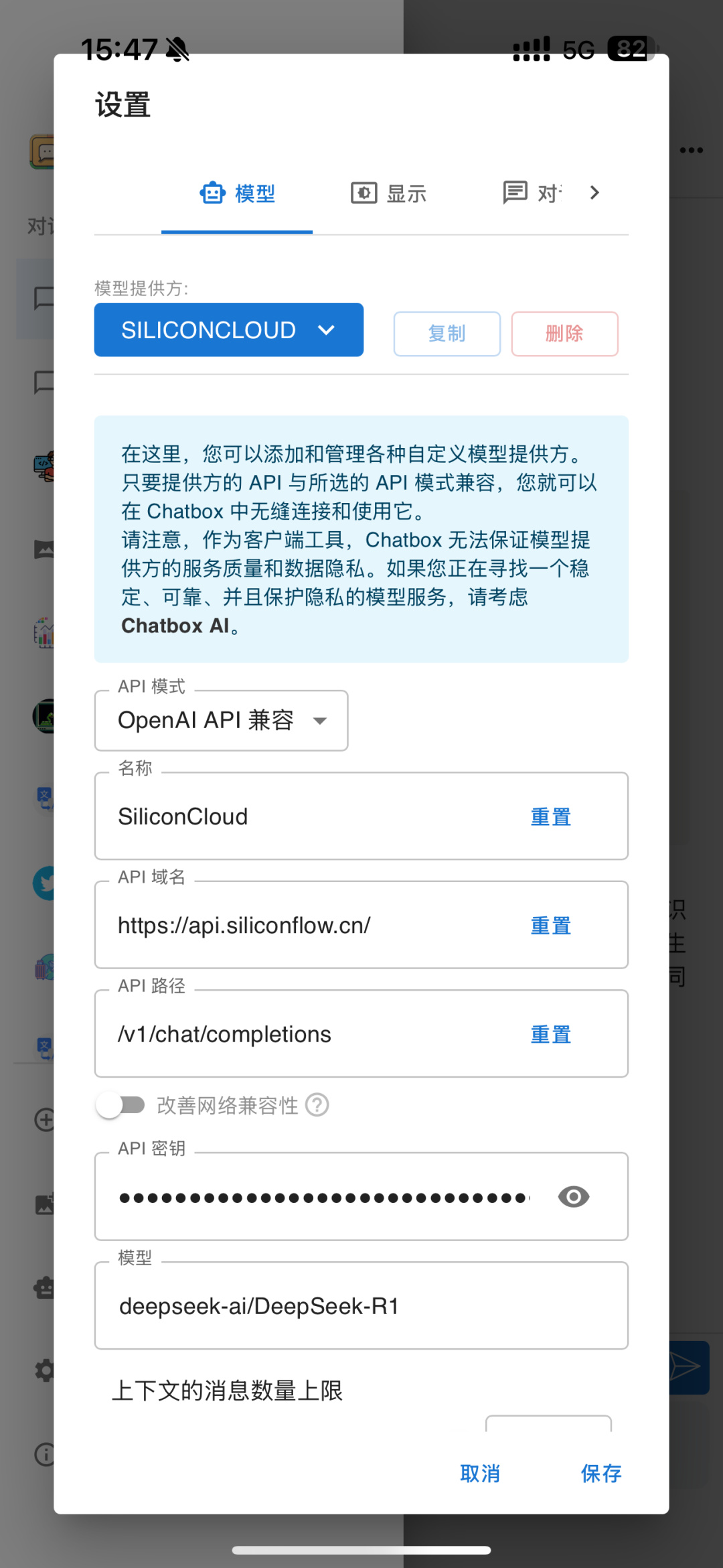
app端也是一样的,下载并安装ChatBox APP,进入“设置”,按照下图输入密钥和API域名、路径。
api域名:https://api.siliconflow.cn/
api路径:/v1/chat/completions
如果你是桌面端使用的话,我个人推荐用Cherry Studio,下载地址:
https://www.cherry-ai.com/
下载安装之后,同样打开设置:
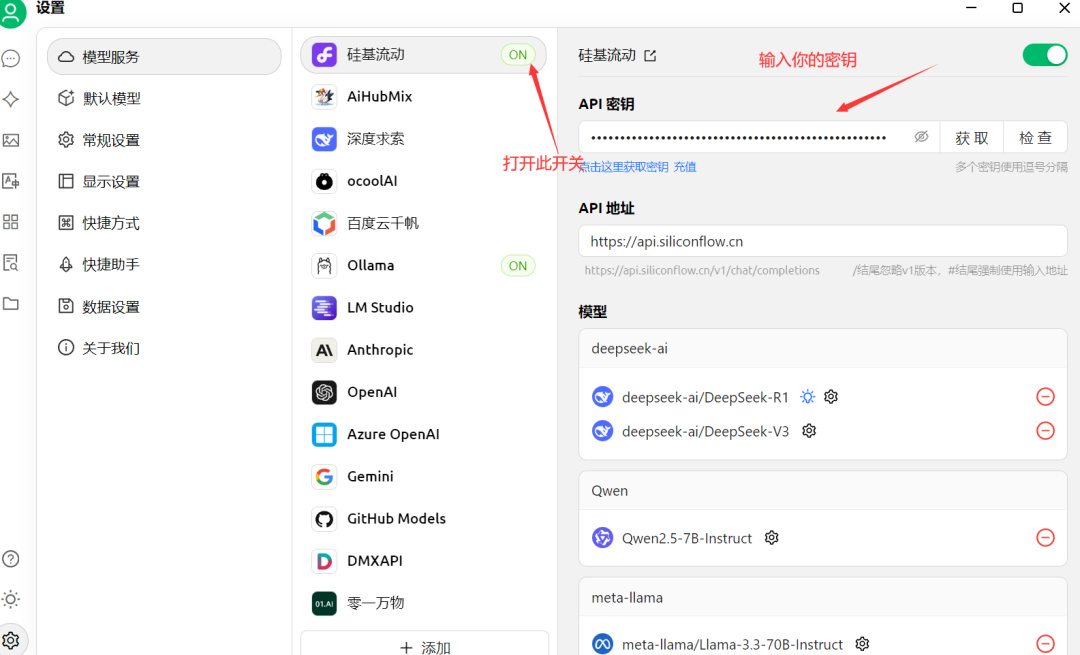
然后点击这里,选择带“硅基流动”的DeepSeek R1,就可以了。
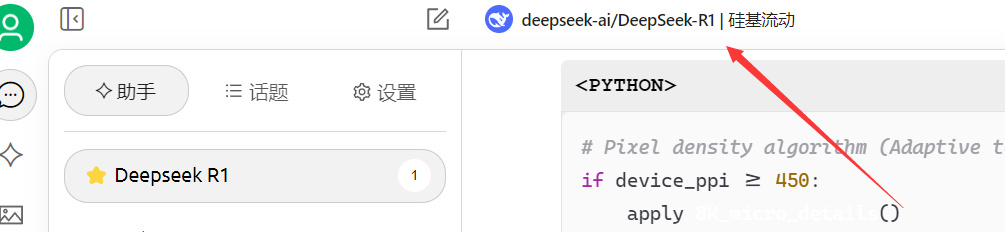
怎么样,是不是超级简单!凭借着超简单的使用,硅基流动也是一炮而红,成为了现在使用DeepSeek的好伙伴。除了硅基流动之外,纳米搜索,腾讯元宝等多款AI工具,也都接入了满血的DeepSeek,大家可以都下载来试用一下,看看哪个好用。
2、Ollama本地部署法
这种方法的优势:真本地部署,无需联网,没有任何信息安全隐患
这种方式的不足:对配置要求非常高(主要是显卡显存),且只能部署“蒸馏版”(也就是残血版)模型。
这种方法很吃显存,看看七彩虹官方给出的参考吧:

哪怕是现在最强大的消费级显卡,RTX5090D,拥有32G显存,也只能部署32B的模型。我自己实测,12G显存的RTX4070Ti,部署32B明显吃力,14B流畅度OK,也基本上能满足需求。
*这个“B”通常代表“Billion”,即“十亿”。它用于表示模型参数的数量。B前面的数字越大,代表模型参数越多,模型的理论能力和表现潜力通常也越高,表现为给出的结果越精准,越专业,但同时也需要更多的计算资源和数据来训练和运行。
显存8G以下推荐部署1.5B的;显存8G推荐部署7B/8B的;显存12-16G可以考虑部署14B的;显存20G以上,可以部署32B的,再往上就不是我们一般用户考虑的事情了。
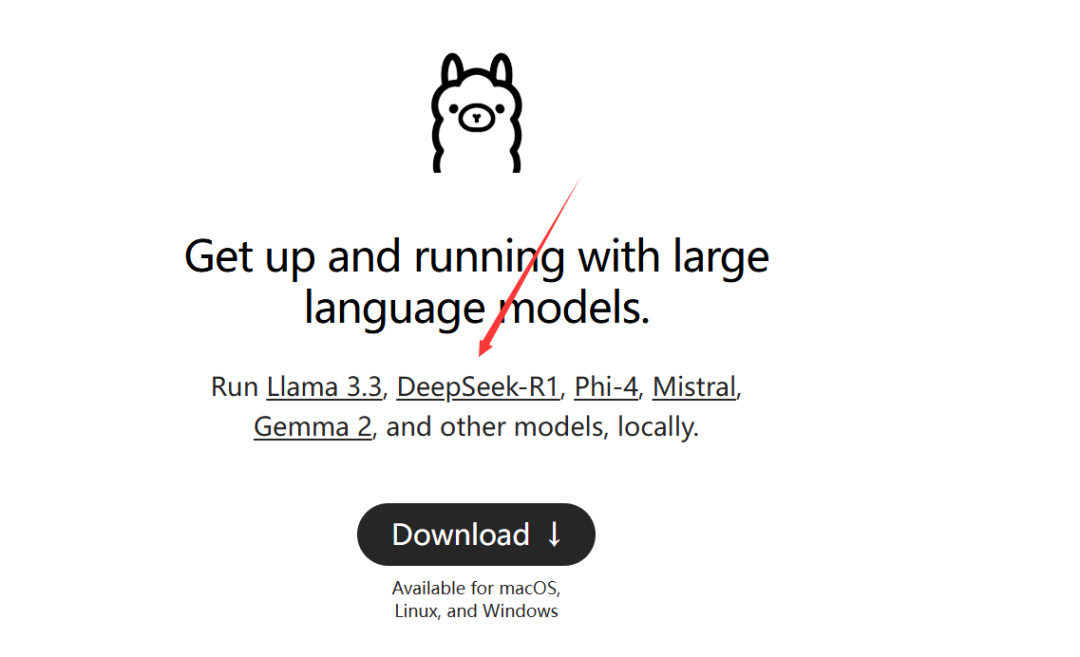
本地部署DeepSeek通过Ollama进行,先下载一个Ollama:
默认安装在C盘,最好不要更改安装盘符,否则要重新配置环境变量。
下载安装完成之后,按win+R,输入“cmd”进入命令提示行,如果出现下面的文字,说明已经安装成功了,可以进入下一步。
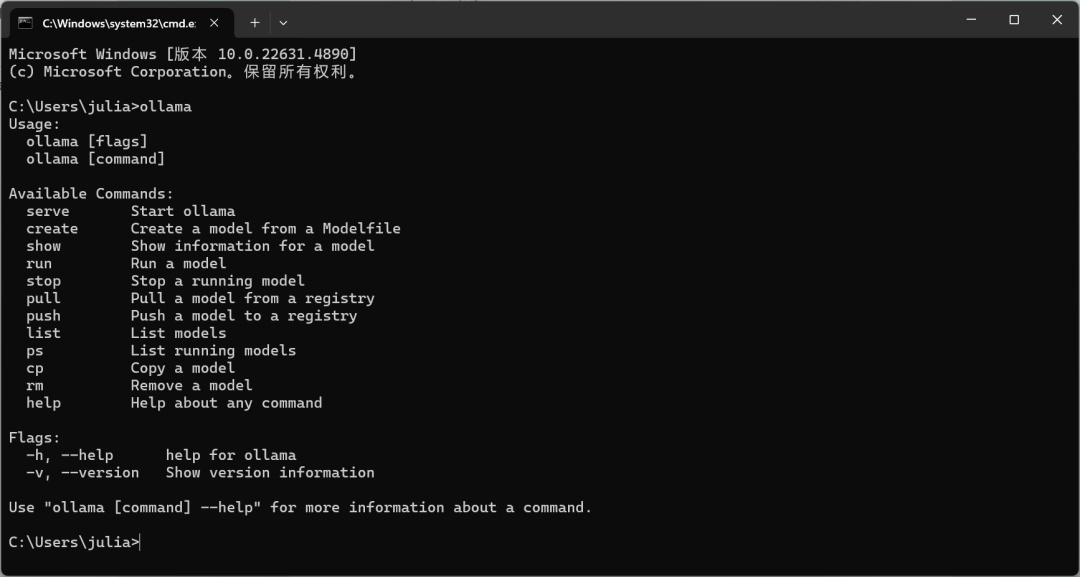
如果提示安装失败的话,可能需要配置一下环境变量:
点击系统设置-系统-系统信息,进入“高级系统设置”:
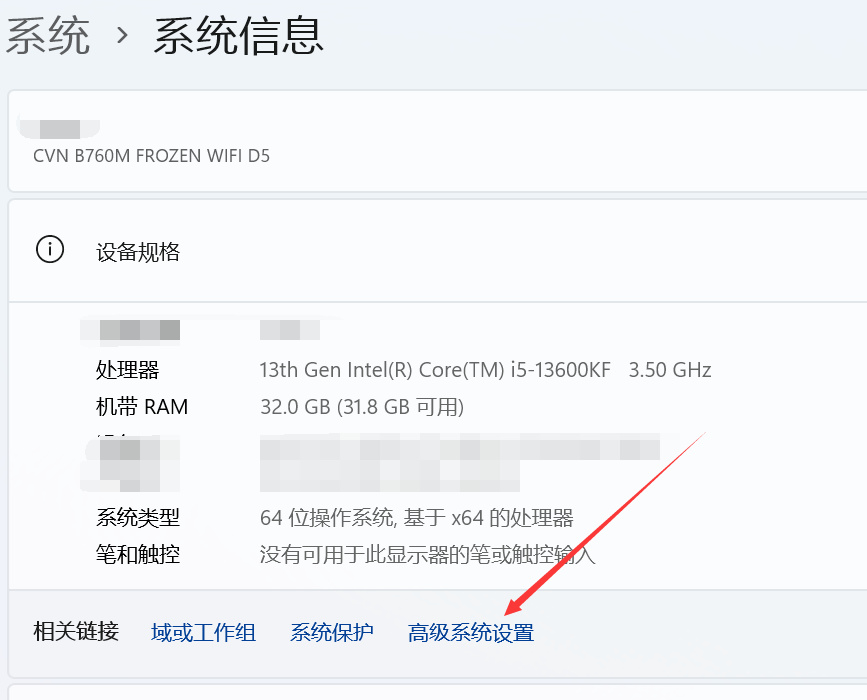
点击“环境变量”:
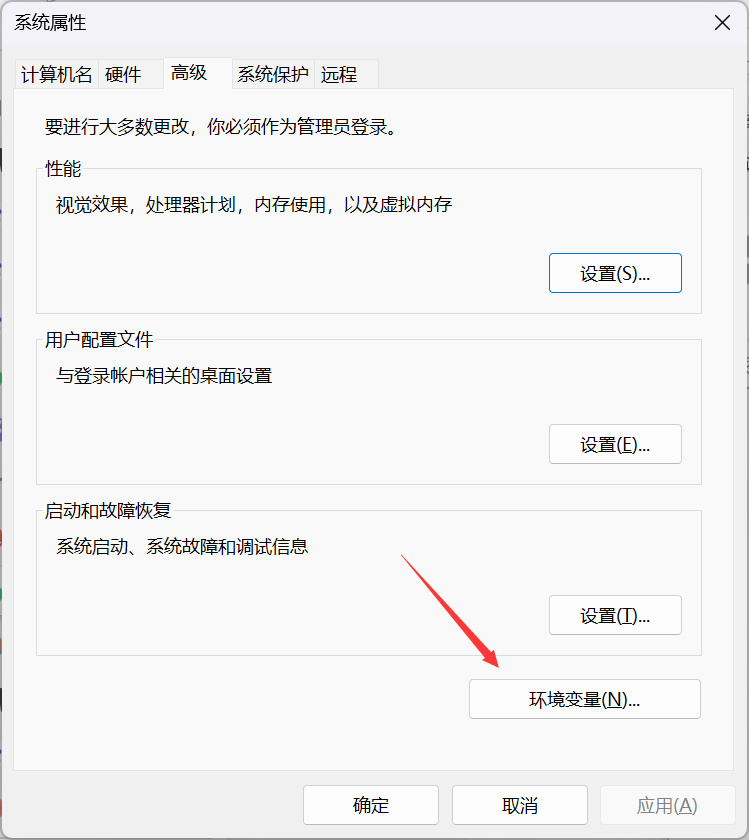
如果没有Ollama的环境变量,可以自己新增一个,变量名字随意,变量值定位到Ollama的安装目录即可:
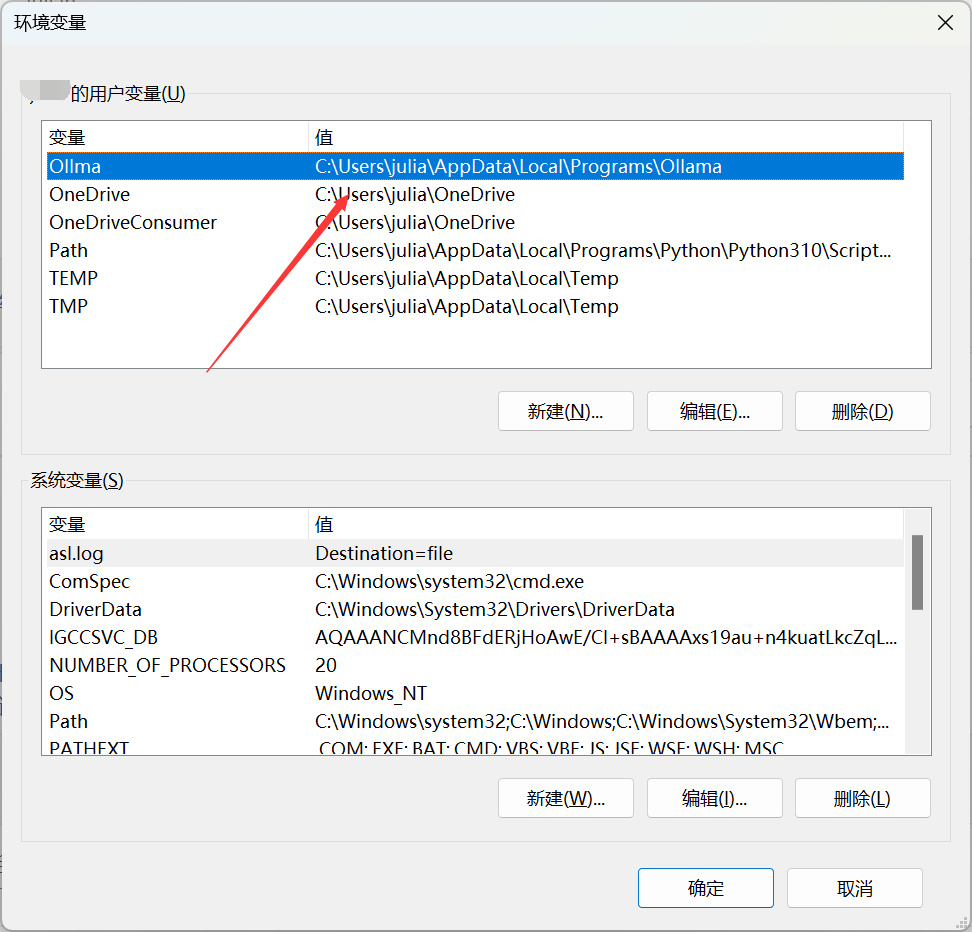
新增完环境变量之后,如果还是有问题的话,重启下电脑,应该就可以了。
成功安装好Ollama之后,win+R,输出“cmd”,再输入“Ollama”命令,启动Ollama。这个时候我们再回到官网找模型,点击这个链接:
点开之后往下滑,来到“Models”这里:

找到自己想要的那个模型(根据自己的电脑显存选),然后复制这个链接,来到命令提示行,粘贴:

按下回车,会自动下载,下载完即可在命令提示行里直接对话了。
但总不可能每次都用命令提示行吧,有没有类似于官网的界面呢?当然有,就是我前面提到的Cherry Studio:
https://www.cherry-ai.com/
下载安装完成之后,打开软件,进入设置打开Ollama的开关,再进入“管理”界面:
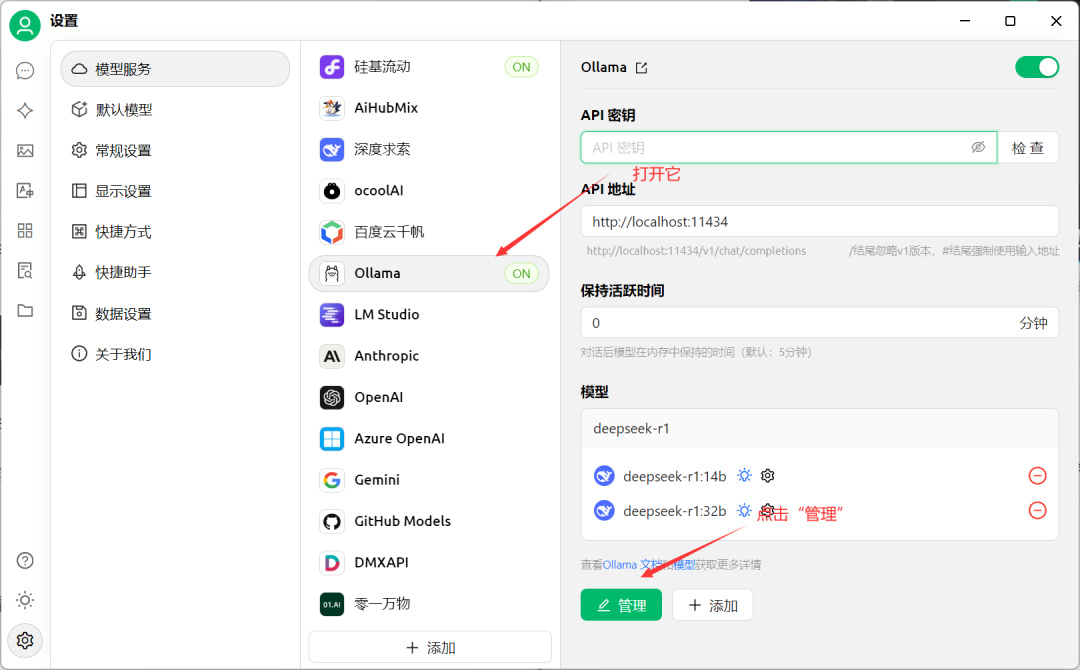
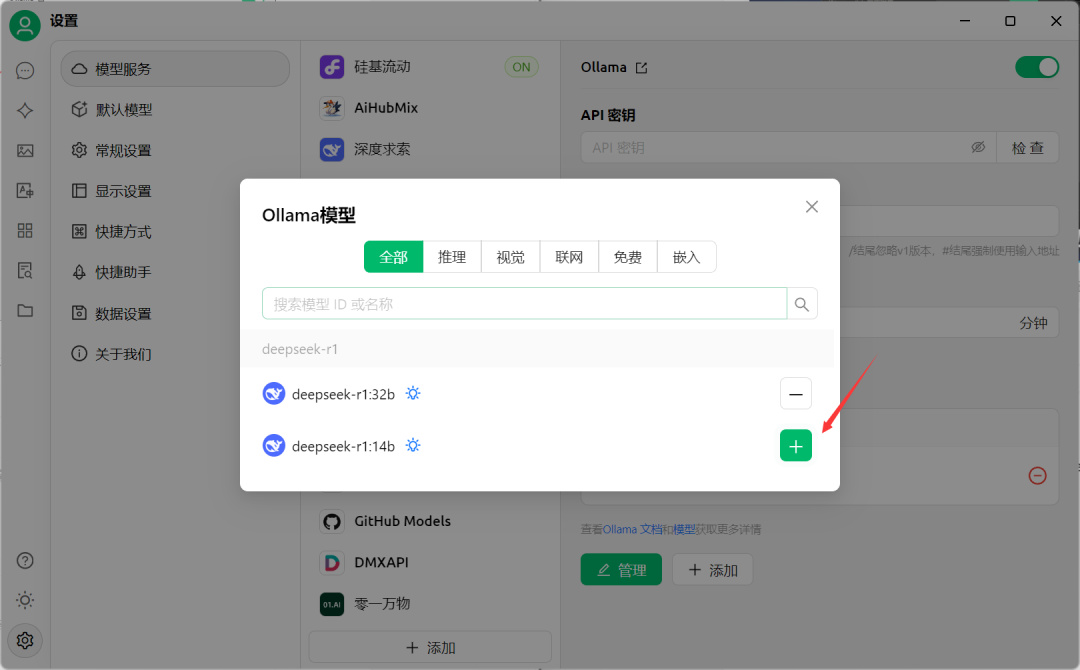
Cherry Studio能直接识别到Ollama里安装的模型,点击“+”号就可以了:
然后回到主界面对话框,把模型选择为Ollama的DeepSeek模型:
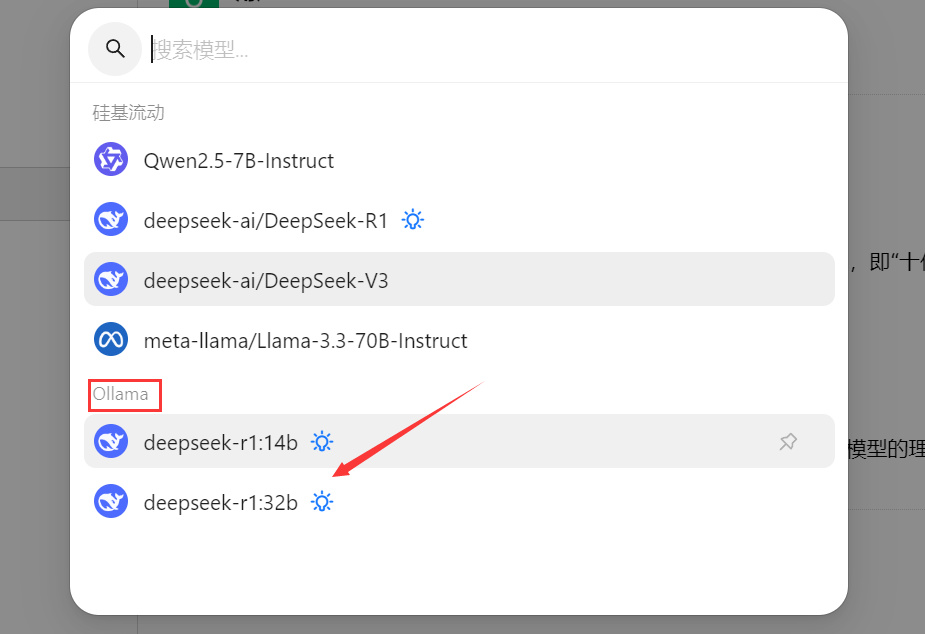
如果你同时部署了硅基流动和Ollama的话,可以在这里切换使用,一般我处理比较复杂的任务,就会用硅基流动那个671B的模型,而如果只是简单的任务,用本地的14B模型足矣,不用钱,而且无需联网,更稳定。
切换完之后,回到主界面开始对话,完成!
显存吃得很满,明显是本地在运行的:
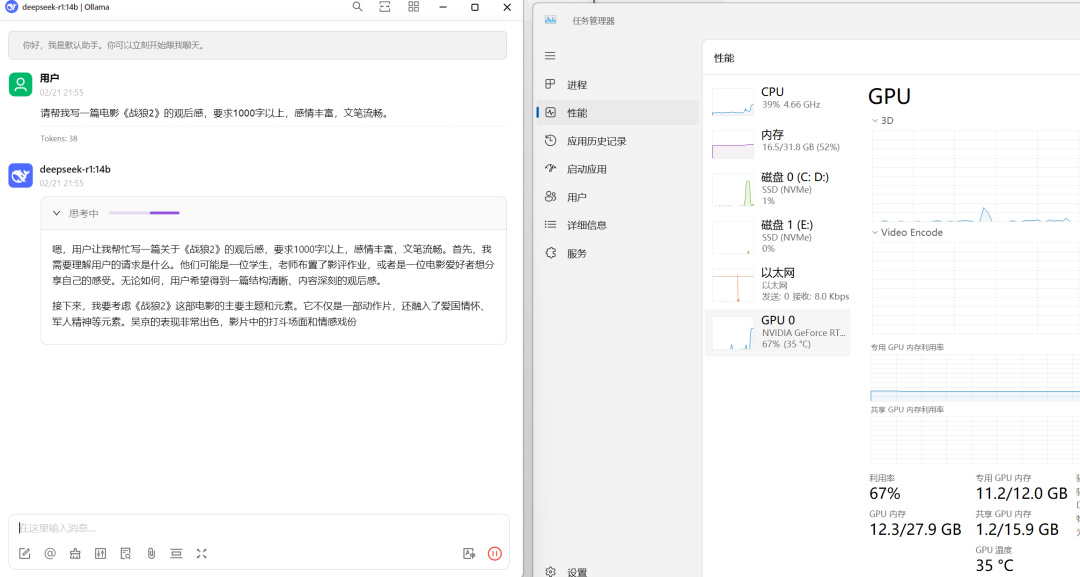
其实14B已经很够用了,看看它生成的《战狼2》电影观后感吧:

好了,今天给大家分享了我自己部署DeepSeek的方案,大家可以参考一下。DeepSeek要想用好,核心就是Prompt(提示词),这个网站是官方的Prompt库,大家可以先看看:
https://api-docs.deepseek.com/zh-cn/prompt-library/
最后,赠送大家一份长达104页,实用的DeepSeek使用指南,来自清华的,后台私信输入“deepseek”获取下载链接(这类材料网上免费的非常多,关于DeepSeek的教程也有一堆,没必要被那些卖课的割韭菜!)

AI毫无疑问是这个时代,人人都要会的实用工具,后续我也会在这里,给大家分享一些我的使用心得
我们下期见,拜拜!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com















