前言
如今,各類AI項目遍地開花,但無論是繪畫模型還是大語言模型基本都離不開pytorch運算框架,而NVIDIA的CUDA封閉生態使得要通過GPU加速pytorch往往需要一張NVIDIA的顯卡。但是衆所周知,同性能的A卡價格遠低於N卡,爲了讓A卡能加速pytorch,AMD推出了ROCm做爲深度學習領域CUDA的替代品,pytorch官方也提供了ROCm的支持,但這一切都需要在Ubuntu物理機上完成,對於我們這類不想頻繁重啓電腦的遊戲玩家很不方便。直到今年前不久,AMD推出了WSL的顯卡驅動和ROCm支持,這使得A卡用戶在不關閉Windows的情況下得以方便地運行各類AI程序。與此同時,Windows下HIP SDK也已經發布了一段時間,儘管pytorch尚未進行支持,一些別的從基礎構建而非使用pytorch的AI項目依然能從中得到支持。除此之外,做爲轉譯運行CUDA的工具,儘管Zluda的主要分支已被叫停並重新編寫(目前來看較長時間內不會有對pytorch的支持),但依然還存在其他分支在不斷更新以支持pytorch。
我將發佈一系列的教程,針對A卡用戶從基礎環境搭建到本地配置包括圖片生成模型(Stable Diffusion、FLUX.1)、大語言模型(可基於llama.cpp運行量化後的較大的模型,同時在顯存充足的情況下可使用LLaMA Factory微調一些4B及以內的較小的模型)、語音轉換模型(GPT-SoVITS、Fish-Speech)和目標檢測模型(YOLO)在內的一系列模型,乃至基於此使用本地算力運行Open-LLM-VTuber,打造完全免費的屬於自己的AI虛擬主播,而這將是這一系列教程的第一篇,做爲基礎環境的搭建部分。
本教程有較多需要複製的地址和指令,建議在電腦上的瀏覽器一邊閱讀一邊操作,手機點擊右上角的分享後複製鏈接發送到電腦即可。
獲取鏈接
本篇教程主要分爲兩個部分,其一是基於WSL通過ROCm運行pytorch做爲運行AI的平臺,其二是基於HIP SDK和Zluda運行pytorch及其他程序做爲運行AI的平臺。我推薦顯卡達到下面的要求的讀者朋友進行閱讀第一部分,而所有的讀者(即使你顯卡達標已經閱讀了第一部分)都應閱讀第二部分。
首先爲避免浪費時間,如果你的顯卡不在下面這個列表當中,說明AMD目前還沒有爲你的顯卡做WSL的支持,無法在WSL中運行ROCm。但你依然能用你的顯卡實現我上面說的那些操作,只不過部分應用相對於WSL上的ROCm會損失部分性能,請跳過本文的WSL部分,直接閱讀本文的HIP SDK和Zluda部分。
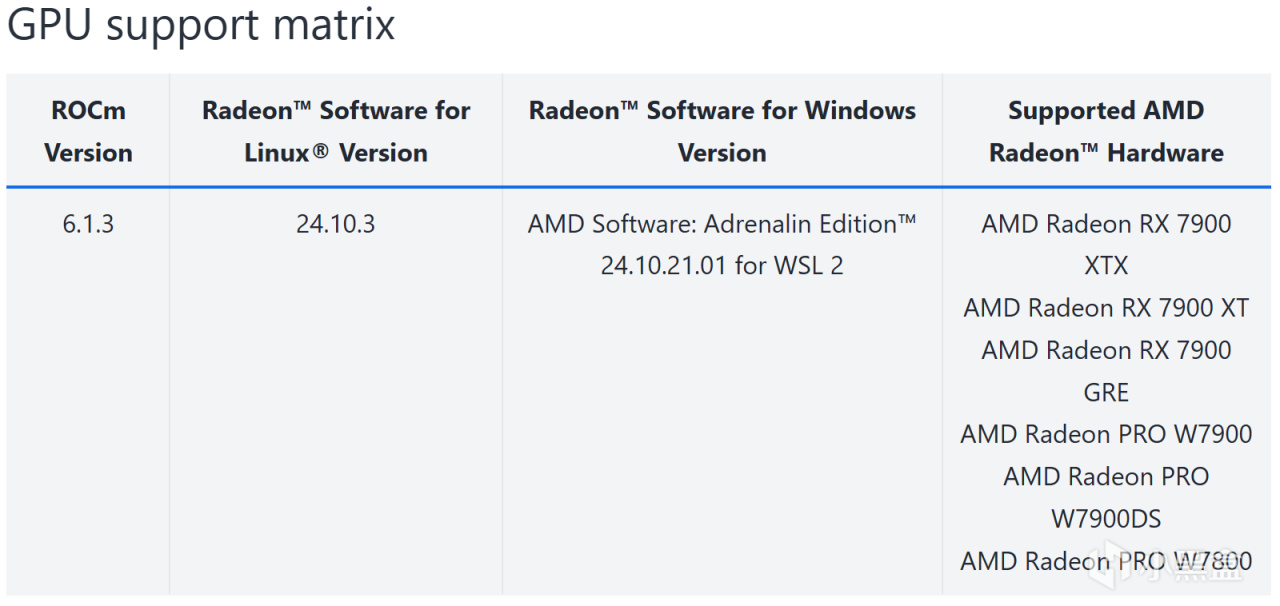
WSL的顯卡支持矩陣
而如果你的顯卡在上面的列表當中,比如和我一樣7900XT,那麼請繼續閱讀以下內容,請注意,對於顯卡達標的讀者而言,爲了更快的運行速度,第一部分也是有必要閱讀的,因爲對於一些模型而言,ROCm和Zluda在相同設備下具有肉眼可見的效率差異(但仍處於同一數量級)。
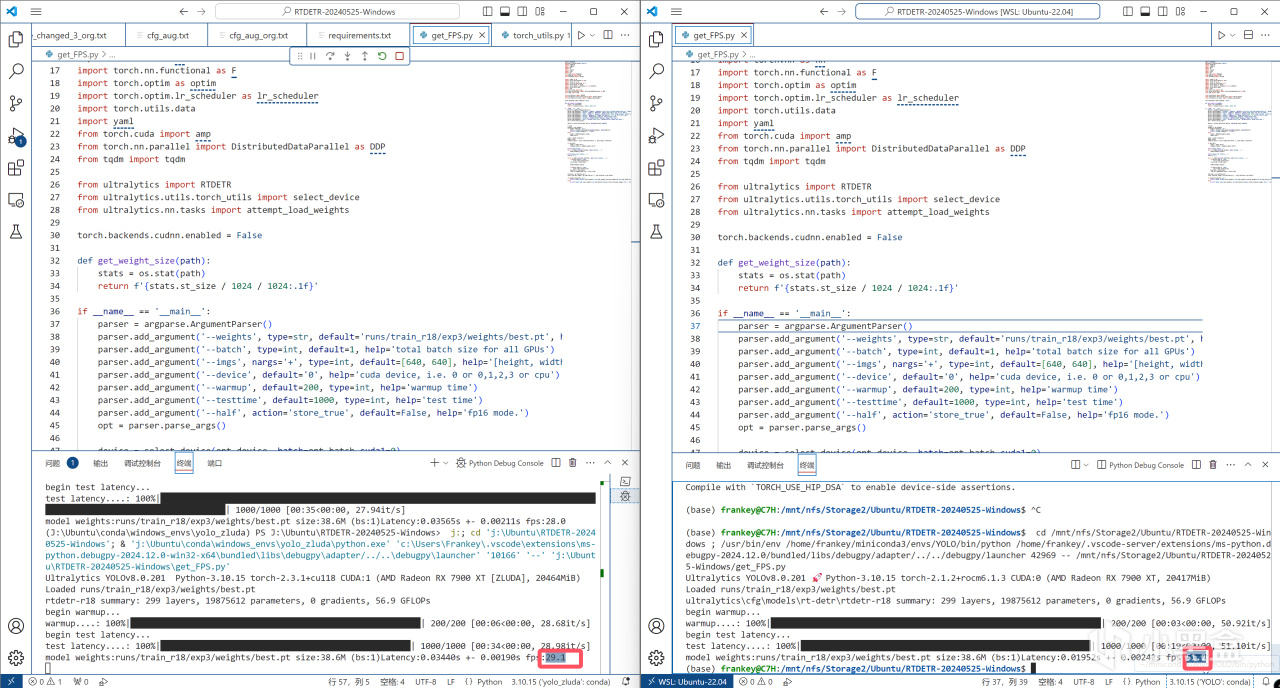
ROCm和Zluda的FPS差異
基於WSL通過ROCm運行pytorch
此部分內容的主要方面基於AMD的官方文檔,若具有一定的英文能力和基礎的朋友可自行閱讀:
https://rocm.docs.amd.com/projects/radeon/en/latest/docs/install/wsl/install-radeon.html
https://rocm.docs.amd.com/projects/radeon/en/latest/docs/install/wsl/install-pytorch.html
首先搜索並打開“啓用或關閉Windows功能”,勾選上“適用於Linux的Windows子系統”和"Hyper-V"
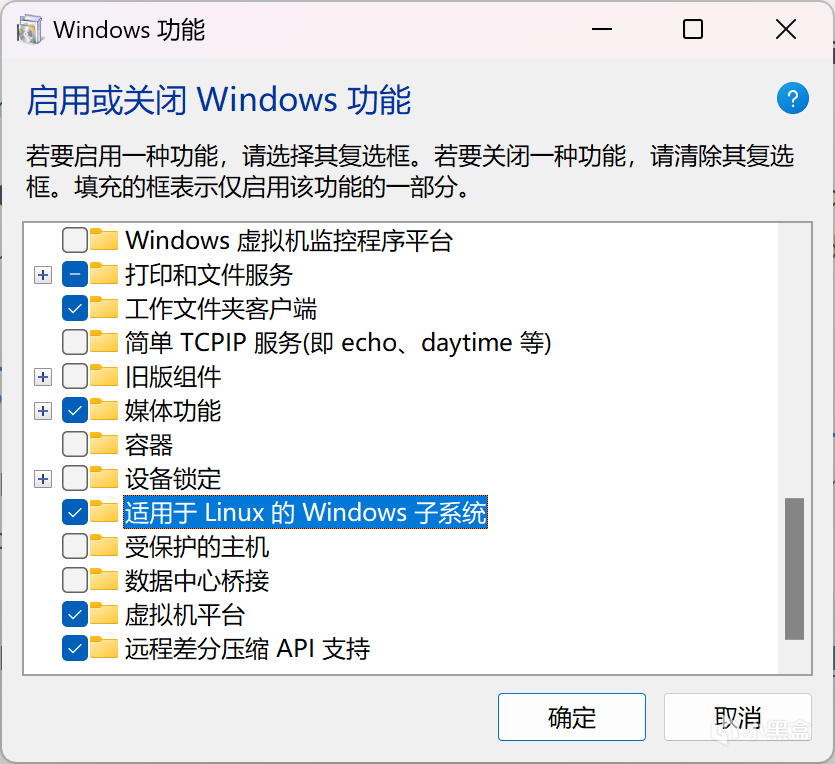
勾選“適用於Linux的Windows子系統”
勾選"Hyper-V"
需要注意的是,Hyper-V僅用於重新壓縮虛擬硬盤文件的大小,可以不啓用,但之後若在WSL中下載了大量文件再刪除後,刪除後空出的那部分空間依舊會佔用虛擬硬盤文件的大小。
勾選完成後點擊確定並重啓電腦,之後進入微軟商店安裝Ubuntu 22.04,注意,一定要有22.04的版本號,不能是其他版本,也不能僅有一個"Ubuntu"但是沒有版本號,目前只有22.04是受AMD支持的WSL版本,其他版本無法正常安裝GPU驅動和ROCm。
安裝Ubuntu 22.04
安裝完成後,在PowerShell中輸入指令:
wsl
進入子系統。
之後運行如下命令下載驅動安裝腳本:
sudo apt update
wget https://repo.radeon.com/amdgpu-install/6.1.3/ubuntu/jammy/amdgpu-install_6.1.60103-1_all.deb
sudo apt install ./amdgpu-install_6.1.60103-1_all.deb
完成後運行如下命令正式安裝驅動:
amdgpu-install -y --usecase=wsl,rocm --no-dkms
驅動安裝需要一定時間,請耐心等待。
安裝完畢後輸入rocminfo,應打印出類似的信息:
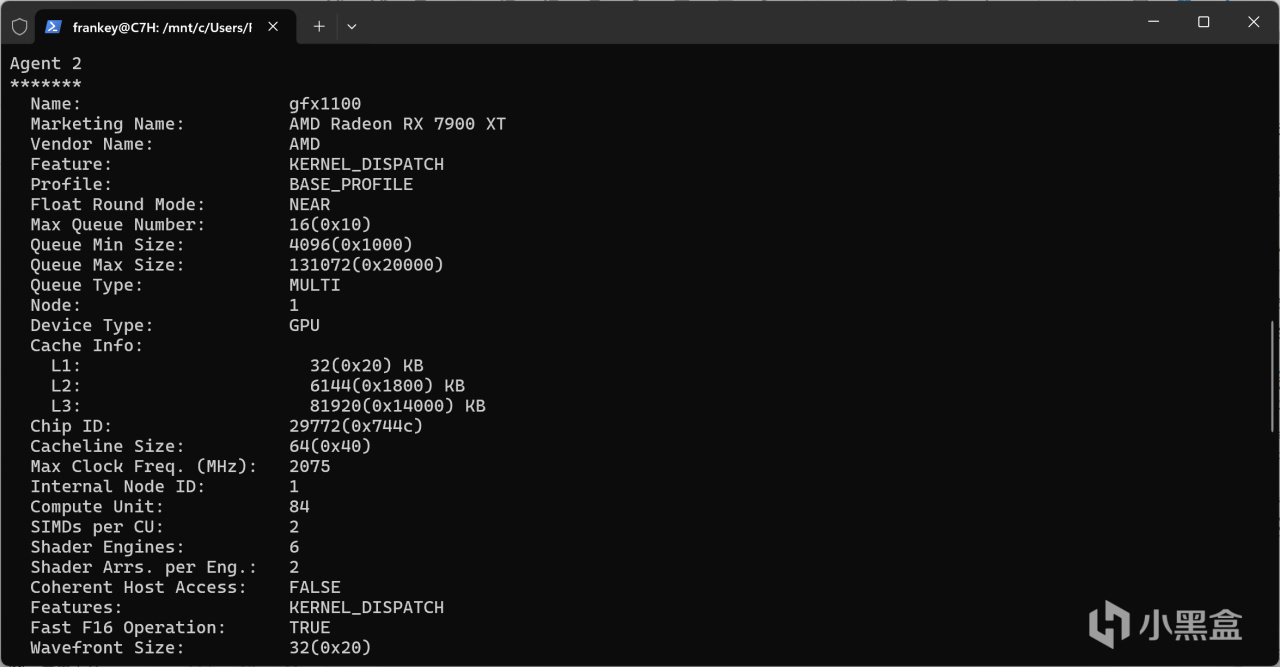
設備信息
此時驅動的安裝已經完成,接下來需要安裝pytorch。
這裏有兩種方法,一種是通過全局的python,一種是通過Anaconda的虛擬環境,我這裏推薦Anaconda的方法,因爲不同的程序會需要不同的環境,如果全部使用同一個環境的話會導致包的管理非常混亂。
首先是全局的python:
sudo apt install python3-pip -y
pip3 install --upgrade pip wheel
再者是Anaconda虛擬環境:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
使用上述指令下載並安裝miniconda,爲防止安裝的最後詢問是否自動激活環境時手滑輸入了no(直接回車默認就是no,需要手動輸入yes),之後手動激活conda環境:
sudo nano ~/.bashrc
在最後一行添加:
export PATH=$PATH:~/miniconda3
按Ctrl+X保存並退出,執行以下命令:
source ~/.bashrc
此時新開一個控制檯進入WSL,那麼用戶名左邊應該有一個(base)字樣表示你正在conda的base環境中。

(base)
爲保持base環境的乾淨,使用如下命令新建一個虛擬環境,注意,WSL的pytorch僅支持python 3.10版本,所以一定要使用3.10版本的python:
conda create -n torch_rocm python=3.10
等待創建完畢後激活環境:
conda activate torch_rocm
至此python的安裝結束,接下來就是核心部分,即pytorch的安裝,首先需要下載由AMD預編譯的pytorch相關包:
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-6.1.3/torch-2.1.2%2Brocm6.1.3-cp310-cp310-linux_x86_64.whl
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-6.1.3/torchvision-0.16.1%2Brocm6.1.3-cp310-cp310-linux_x86_64.whl
wget https://repo.radeon.com/rocm/manylinux/rocm-rel-6.1.3/pytorch_triton_rocm-2.1.0%2Brocm6.1.3.4d510c3a44-cp310-cp310-linux_x86_64.whl
之後以防萬一卸載現有的pytorch相關包:
pip3 uninstall torch torchvision pytorch-triton-rocm numpy
最後就是正式安裝了:
pip3 install torch-2.1.2+rocm6.1.3-cp310-cp310-linux_x86_64.whl torchvision-0.16.1+rocm6.1.3-cp310-cp310-linux_x86_64.whl pytorch_triton_rocm-2.1.0+rocm6.1.3.4d510c3a44-cp310-cp310-linux_x86_64.whl
此時包的安裝已經結束,但是整個過程還沒完,因爲這個時候如果你執行torch.cuda.is_available()會發現其返回的是False,也就是說此時pytorch依然只能使用CPU來計算,那麼就需要下面的操作了:
location=`pip show torch | grep Location | awk -F ": " '{print $2}'`
cd ${location}/torch/lib/
rm libhsa-runtime64.so*
cp /opt/rocm/lib/libhsa-runtime64.so.1.2 libhsa-runtime64.so
那麼到此爲止,AMD的教程就結束了,但是如果此時你import torch,還會出現類似於下面的錯誤:
ImportError: /home/cedric/anaconda3/envs/decdiff_env/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /lib/x86_64-linux-gnu/libLLVM-15.so.1)
但是沒關係,請繼續如下操作:
location=`pip show torch | grep Location | awk -F ": " '{print $2}'`
cd ${location}/torch/lib/
mv libstdc++.so.6 libstdc++.so.6.old
ln -s /usr/lib/x86_64-linux-gnu/libstdc++.so.6 libstdc++.so.6
此時再進行測試,就不應出現任何問題了。
python
import torch
torch.cuda.is_available()
此時出現的就應該是True,說明pytorch可以使用你的GPU進行運算了。
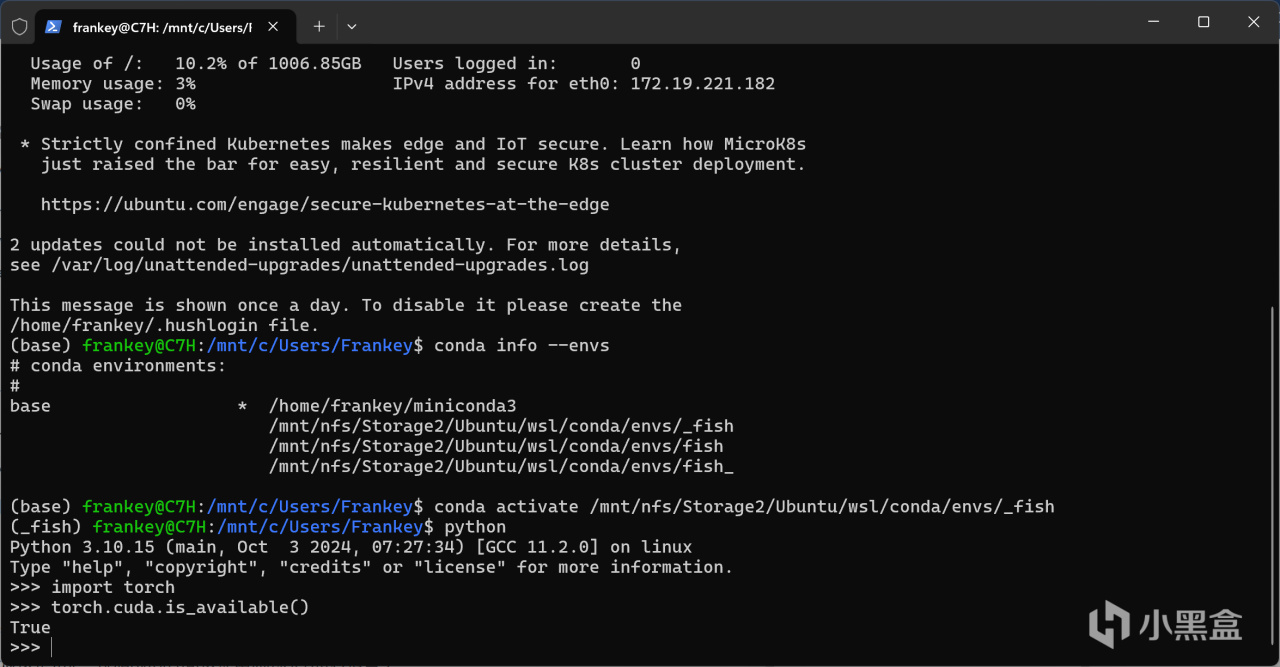
torch.cuda.is_available()
輸入以下指令退出python(按Ctrl+C是沒用的):
exit()
到此爲止你已經成功得到了一個可以使用A卡的pytorch,本篇教程WSL的部分已經結束,但是我推薦你繼續閱讀並安裝Zluda,因爲AI繪畫方面已經有秋葉大佬https://space.bilibili.com/12566101 的整合包。秉着不重複造輪子的原則,我不會重新去配置一個新的環境,而是僅對一些使用上的方法進行說明(主要是針對低顯存的顯卡如何通過量化來運行百億級別參數的繪畫大模型),而秋葉大佬的整合針對A卡使用的是Zluda(DirectML遠比Zluda要慢)的方式來運行,所以接下來的內容對於運行AI繪畫而言是有用的。
再次強調,目前僅RX 7900 (XTX/XT/GRE)和部分專業卡可在WSL上運行ROCm:
https://rocm.docs.amd.com/projects/radeon/en/latest/docs/compatibility/wsl/wsl_compatibility.html
WSL的顯卡支持矩陣
不過根據ROCm開發者的回覆,將來WSL下的ROCm將支持更多的顯卡:
https://github.com/ROCm/ROCm/issues/3402#issuecomment-2218312649
目前經本人測試,WSL下RX 7900 XT可正常運行ROCm,而RX 6750 GRE 12G無法正常運行ROCm,而如果不想等待的話,一方面可直接在Ubuntu物理機上安裝ROCm並通過"export HSA_OVERRIDE_GFX_VERSION=1030"運行(經本人測試即使在Ubuntu物理機下ROCm 6.0以上也並不支持6750GRE(gfx1031),請使用ROCm5.6版本):
https://www.reddit.com/r/LocalLLaMA/comments/18ourt4/my_setup_for_using_rocm_with_rx_6700xt_gpu_on/
另一方面則是下文要講的內容,使用Zluda運行絕大多數基於pytorch的程序,同時自行編譯llama.cpp來適配自己的顯卡以運行量化後的大語言模型(這一部分直接基於HIP SDK,不通過Zluda)。並且,考慮到大夥有6750GRE的比較多,儘管官方沒有相關版本,我本人也預編譯了支持gfx1031(6750、6700等顯卡)的llama.cpp程序,我會在之後llama.cpp的文章中放出,有6750GRE的朋友可以直接下載。
而做爲基礎環境的一部分,本文僅介紹到Zluda下pytorch的使用爲止:
基於Windows通過HIP SDK和Zluda運行pytorch
首先AMD官網下載HIP SDK for Windows(再次說明llama.cpp直接依靠HIP SDK,即使你不打算安裝Zluda你也應該安裝HIP SDK,而Zluda同樣依靠HIP SDK運行,所以這應該是必裝的):
https://www.amd.com/en/developer/resources/rocm-hub/hip-sdk.html
關於版本,如果你要自己編譯llama.cpp,我推薦同時下載5.7.1和6.1.2的版本,如果你只是單純運行程序,那我推薦只下載5.7.1的版本(主要由於本人編譯的llama.cpp在6.1.2版本下的HIP SDK下會報內存錯誤無法運行,具體原因未知)。
下載好後直接運行安裝,默認裝在C盤,也可以手動指定到其他盤,整個流程和安裝顯卡驅動一樣簡單。
需要注意的是,Pro版本的顯卡驅動是並不需要安裝的,用已有的遊戲驅動也可正常運行一切功能。
安裝完成後,搜索並打開"編輯系統環境變量",選擇"環境變量"
打開系統屬性
環境變量
如果你同時安裝了6.1.2版本和5.7.1版本的HIP SDK,那麼需要編輯HIP_PATH_57、HIP_PATH_61、HIP_PATH共3個變量,分別設置爲你各個版本的HIP SDK的安裝位置,就和我圖中的一樣。如果只安裝了一個版本,那就少設置一個即可。
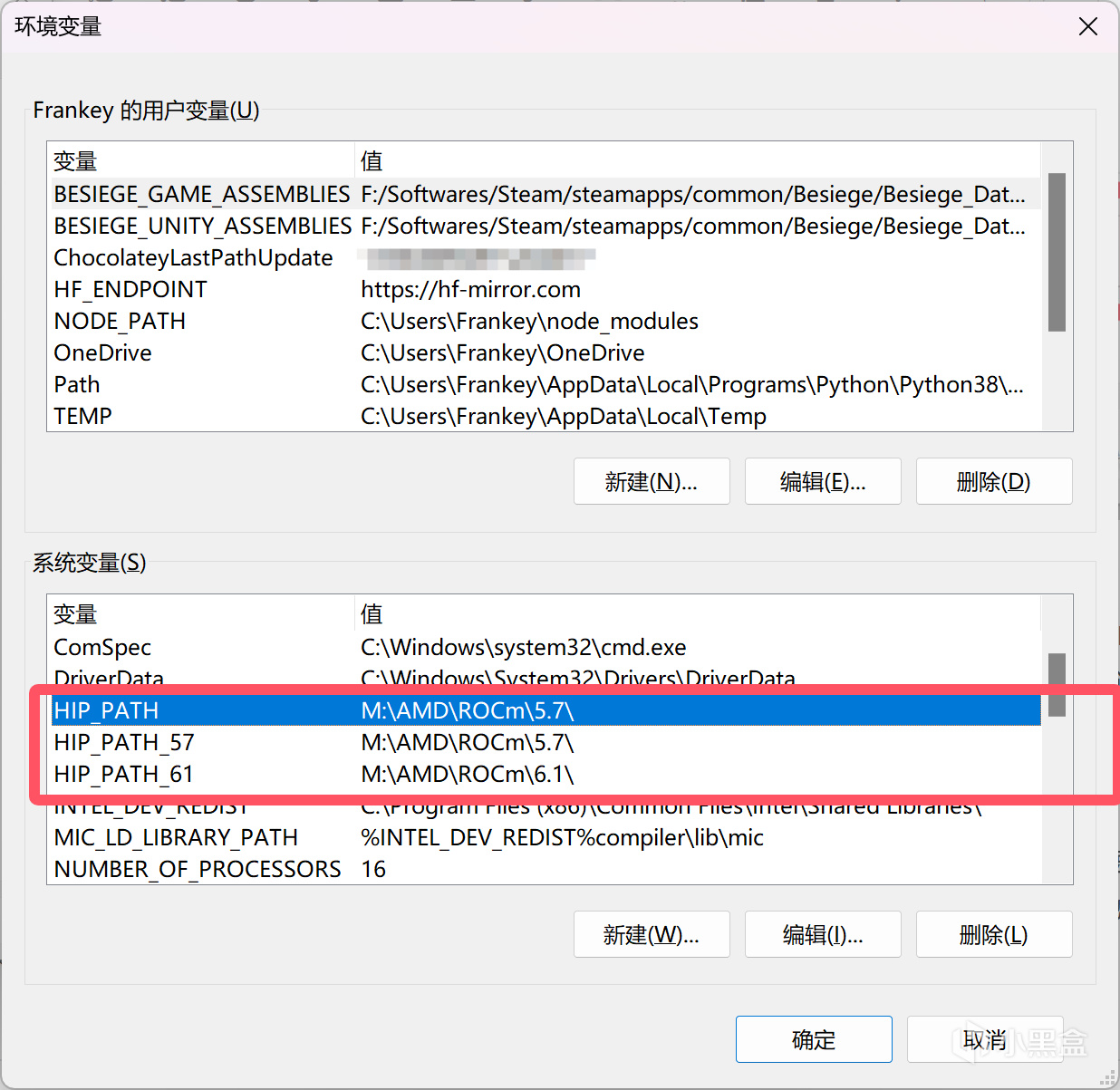
HIP_PATH
之後往下滑,找到"Path"變量,雙擊編輯,將"%HIP_PATH%\bin"添加進去,如圖所示。
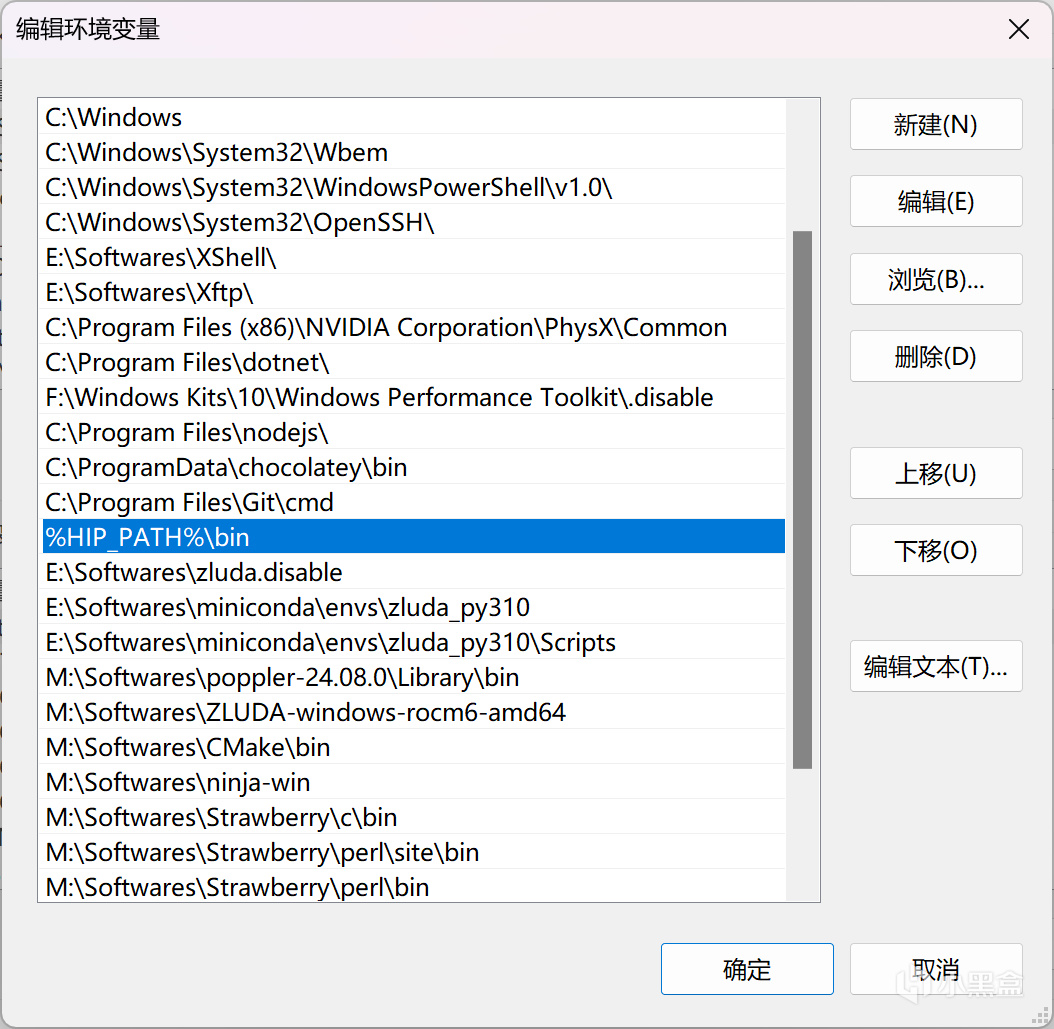
Path
如果你的顯卡可以在WSL上使用ROCm,或者你只需要運行AI繪畫和大語言模型,那麼本篇教程到這裏也就結束了,因爲秋葉大佬的整合會爲你自動完成後面的部分,而如果你的顯卡不受WSL支持並且你還想運行其他程序(如語音克隆),請繼續閱讀下面的內容。
首先,HIP SDK的支持範圍又要比WSL的ROCm要大一些,如果你的顯卡在下圖中的支持矩陣中有兩個√,那麼可跳過下面一步,直接轉到Zluda的正式安裝部分。
https://rocm.docs.amd.com/projects/install-on-windows/en/develop/reference/system-requirements.html
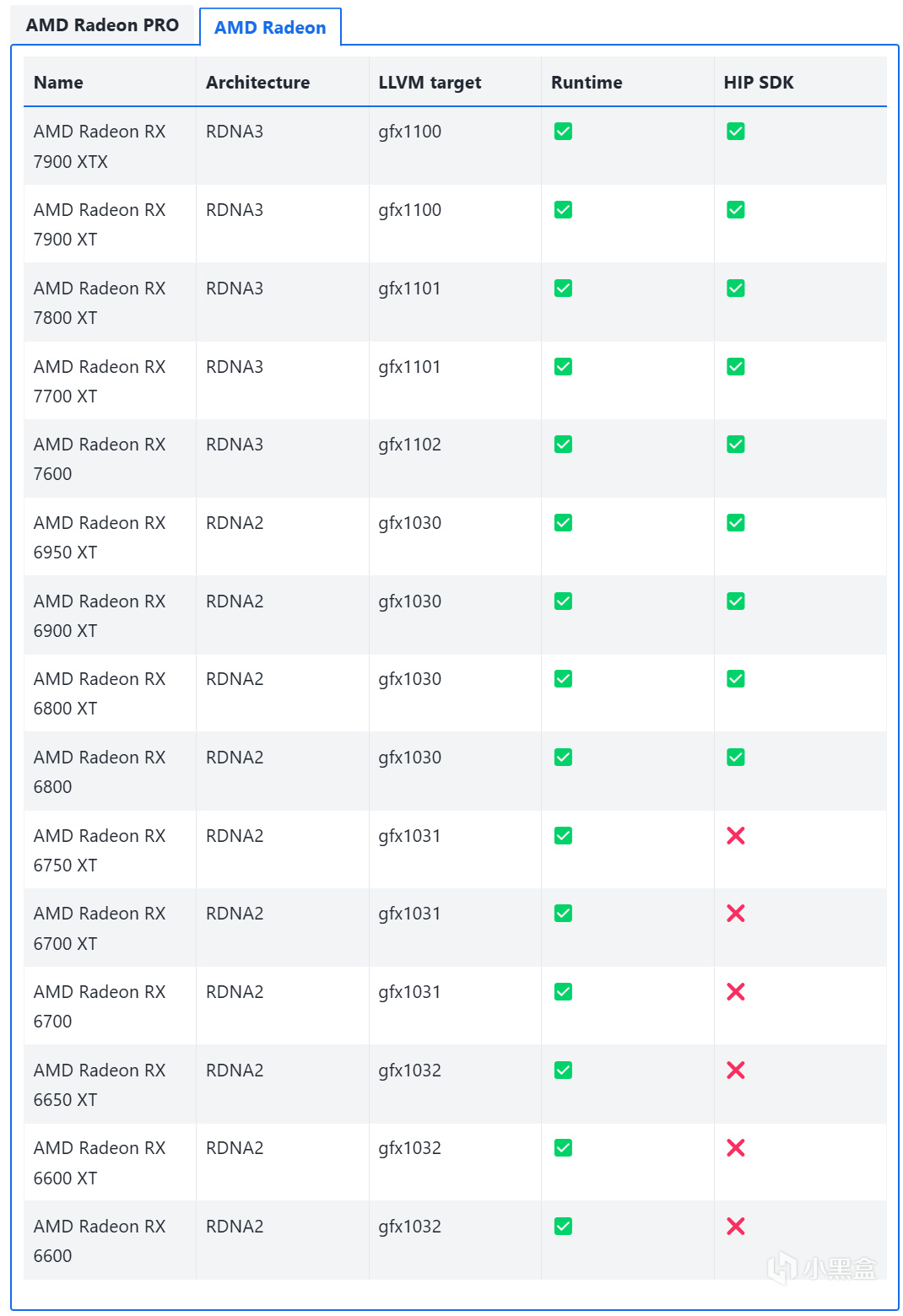
HIP SDK的GPU支持矩陣
請進入https://github.com/brknsoul/ROCmLibs 項目中
對於5.7.1版本的HIP SDK,如果你是gfx1031系列的顯卡(包括6750GRE),請下載Optimised_ROCmLibs_gfx1031.7z,如果你是gfx1032系列的顯卡(主要是6600系列),對於其他顯卡,請下載ROCmLibs.7z。
對於6.1.2版本的HIP SDK,目前僅支持gfx1031系列的顯卡,請下載rocm gfx1031 for hip sdk 6.1.2 optimized.7z。
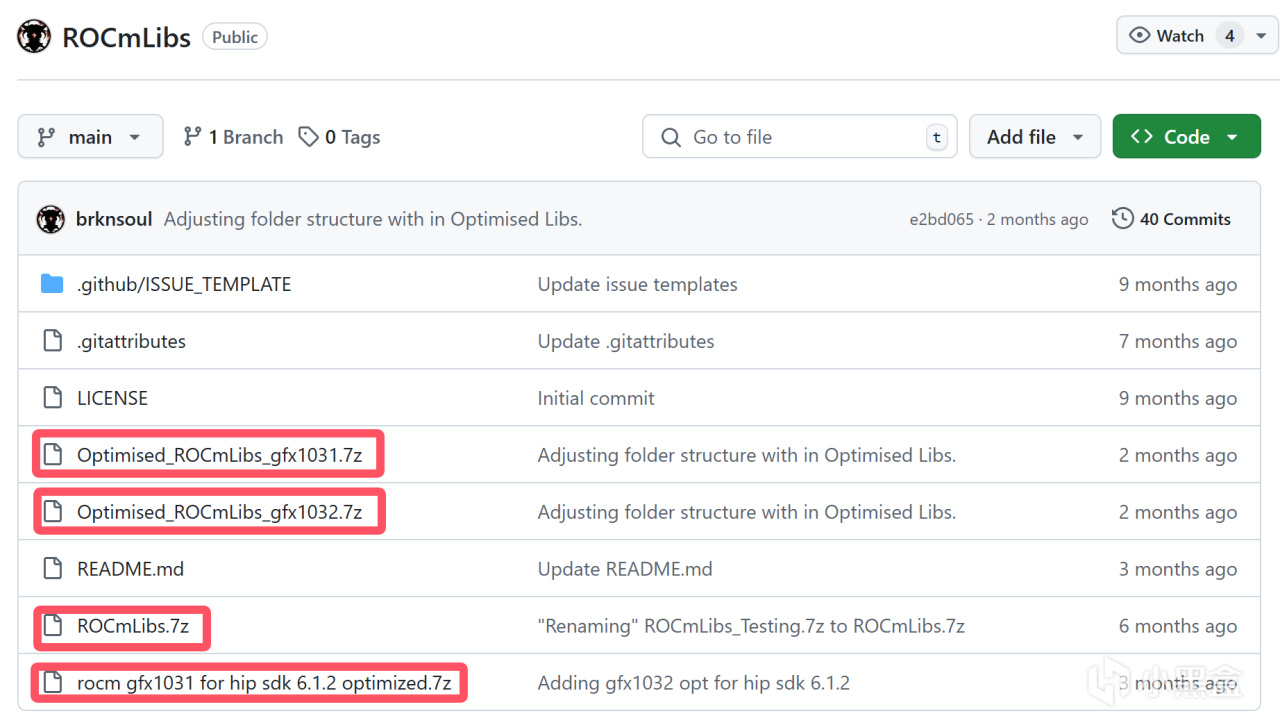
ROCmLibs
將其中的文件解壓後,複製到%HIP_PATH%\bin\rocblas\中,對於我而言是M:\AMD\ROCm\5.7\bin\rocblas\,若有覆蓋提示直接確認即可。
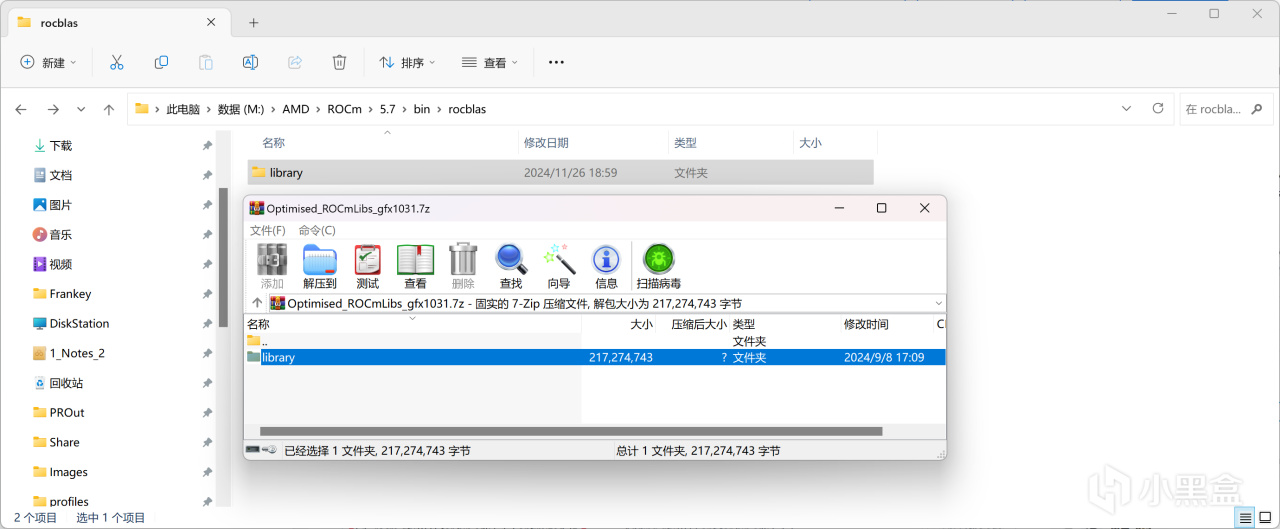
覆蓋ROCm library
HIP SDK的安裝到此完全結束,下面開始Zluda的安裝。
用於運行pytorch的Zluda的分支地址如下:
https://github.com/lshqqytiger/ZLUDA
請自行在Releases中根據你使用的ROCm的版本下載對應的版本:

Zluda
將其隨便解壓到一個地方,然後用與上文相同的操作打開環境變量編輯,將你解壓Zluda的路徑添加到"Path"變量中。
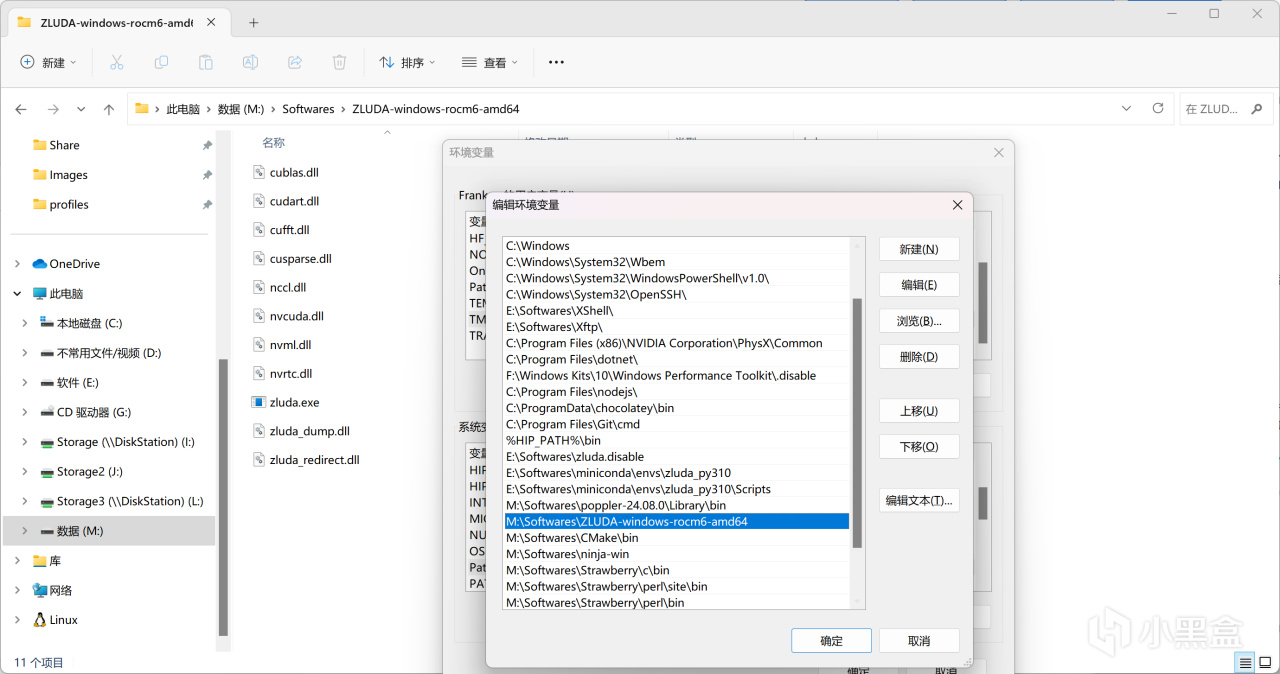
解壓Zluda並添加到環境變量
此時Zluda的安裝結束,非常簡單,但是要想使pytorch運行在Zluda上面,還需要一些操作。
在這裏再爲Windows安裝一個miniconda來運行虛擬python環境,其可通過此鏈接進行下載:
https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe
安裝完成後搜索"Anaconda Prompt (miniconda)"並打開。
Anaconda Prompt (miniconda)
可以看到此時已經進入了"base"環境:
"base"環境
之後創建環境的操作和上文中WSL的部分一樣:
conda create -n torch_zluda python=3.10
conda activate torch_zluda
然後使用pytorch官網中的指令直接安裝CUDA版本的pytorch:
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
需要注意的是,Zluda並不支持最新版本的pytorch,會報CUDA錯誤,本人已經驗證2.5.1版本的pytorch是無法運行的,而2.3.1版本的pytorch是可以運行的,所以上面的指令是2.3.1版本,其他版本請自行驗證。
CUDA版本的pytorch安裝完成後,需要對其進行一些修改,首先輸入以下指令列出你所有的環境的位置,並找到你剛剛安裝pytorch的那個環境,將其路徑複製下來:
conda info --envs
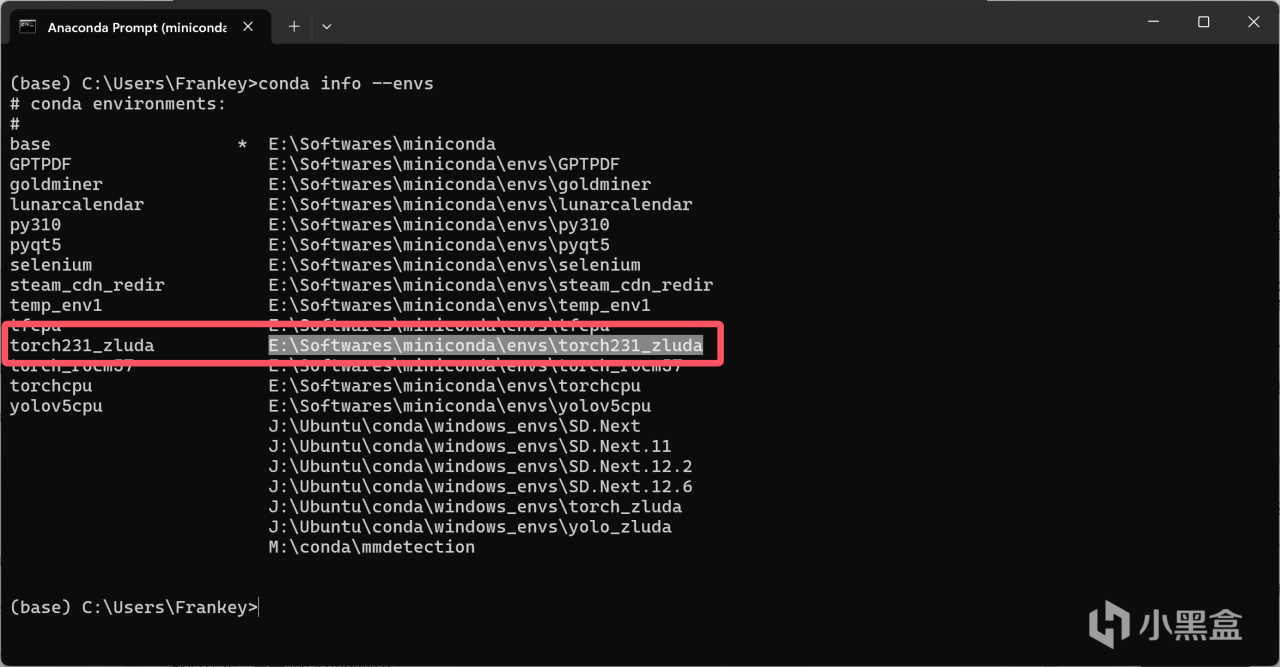
列出環境
打開該目錄,進入.\Lib\site-packages\torch\lib:
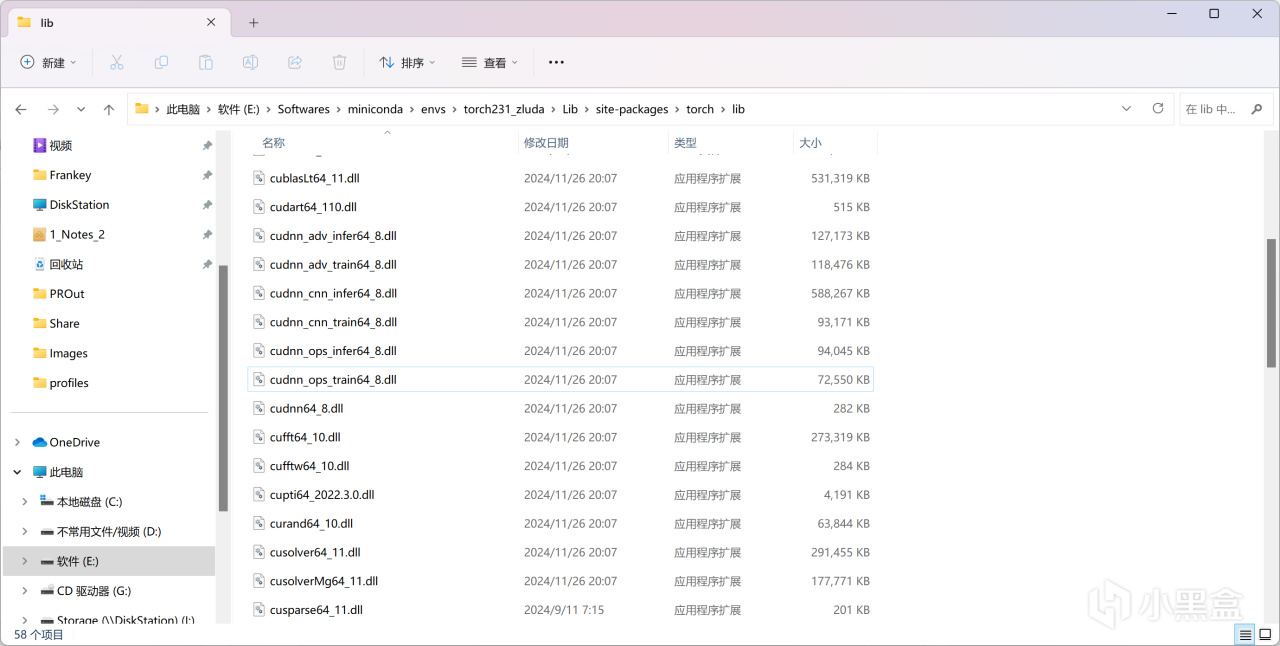
pytorch的lib目錄
將cublas64_11.dll和cusparse64_11.dll分別重命名爲cublas64_11.dll.bak和cusparse64_11.dll.bak:
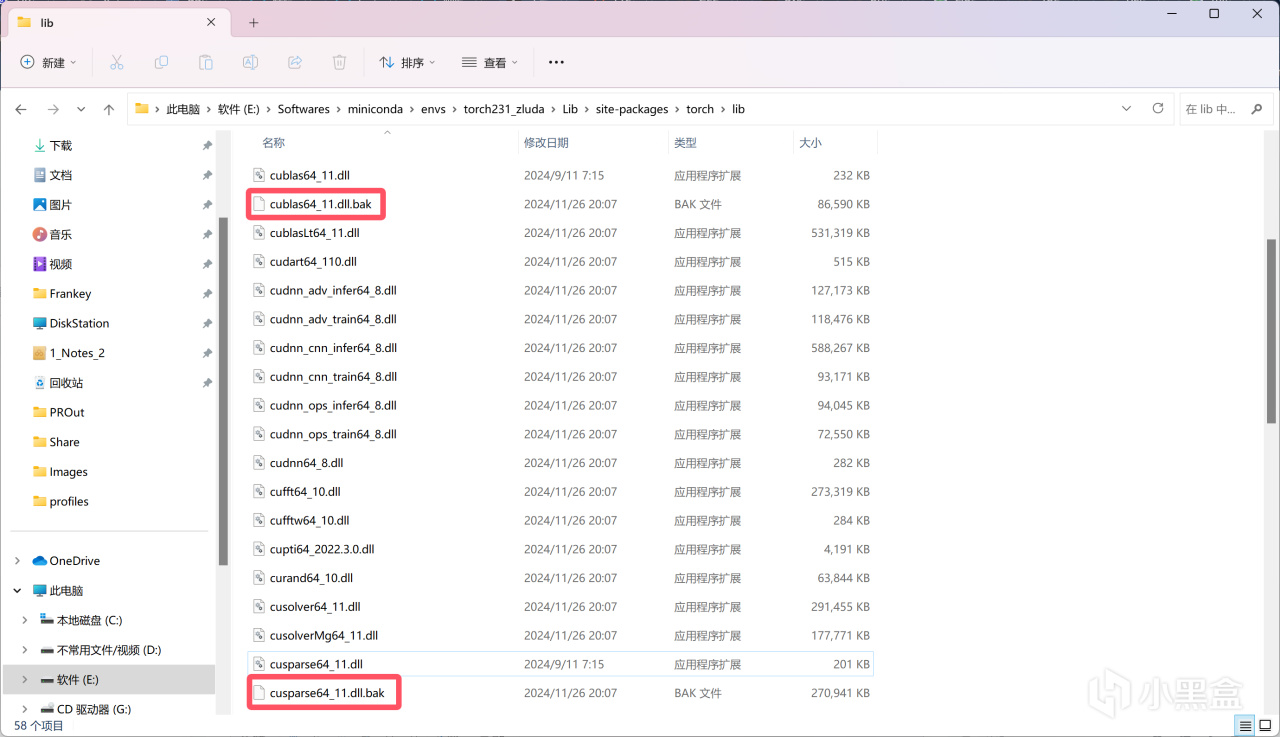
重命名以禁用
打開Zluda的目錄,將Zluda目錄下cublas.dll和cusparse.dll複製下來並粘貼到pytorch的lib目錄當中(也就是上圖中的目錄)。
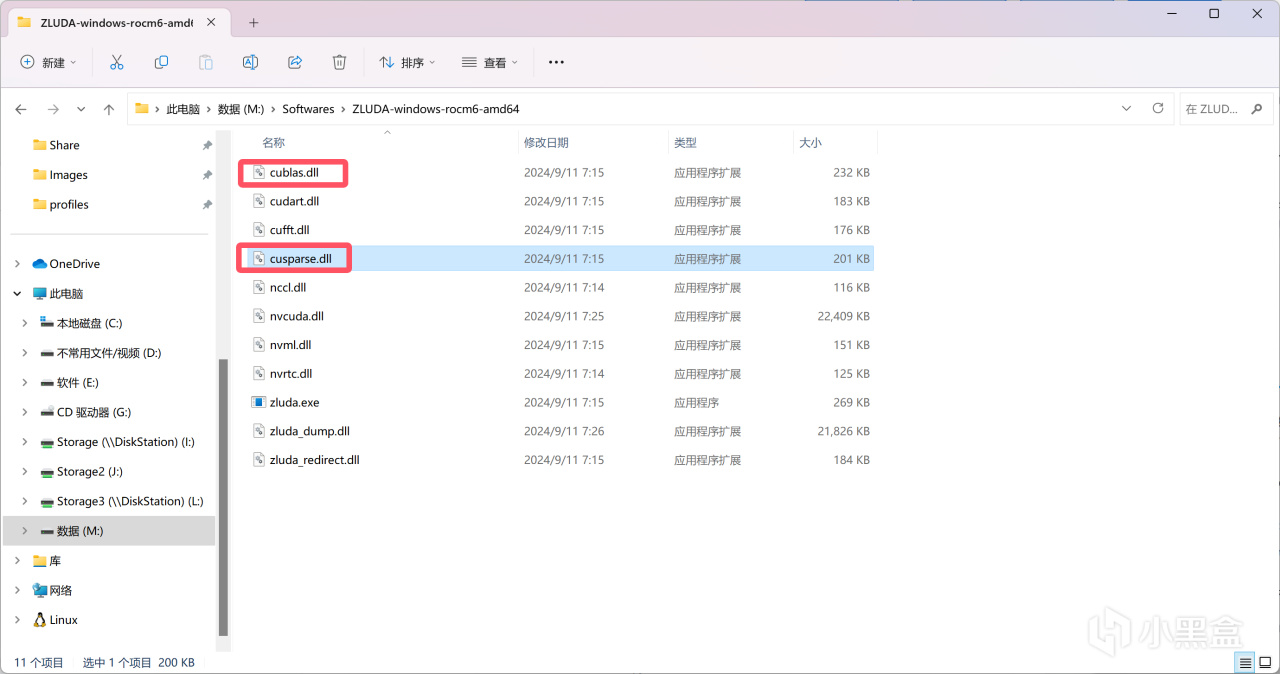
Zluda目錄
在pytorch的lib目錄中將從Zluda目錄複製的cublas.dll和cusparse.dll分別重命名爲cublas64_11.dll和cusparse64_11.dll。
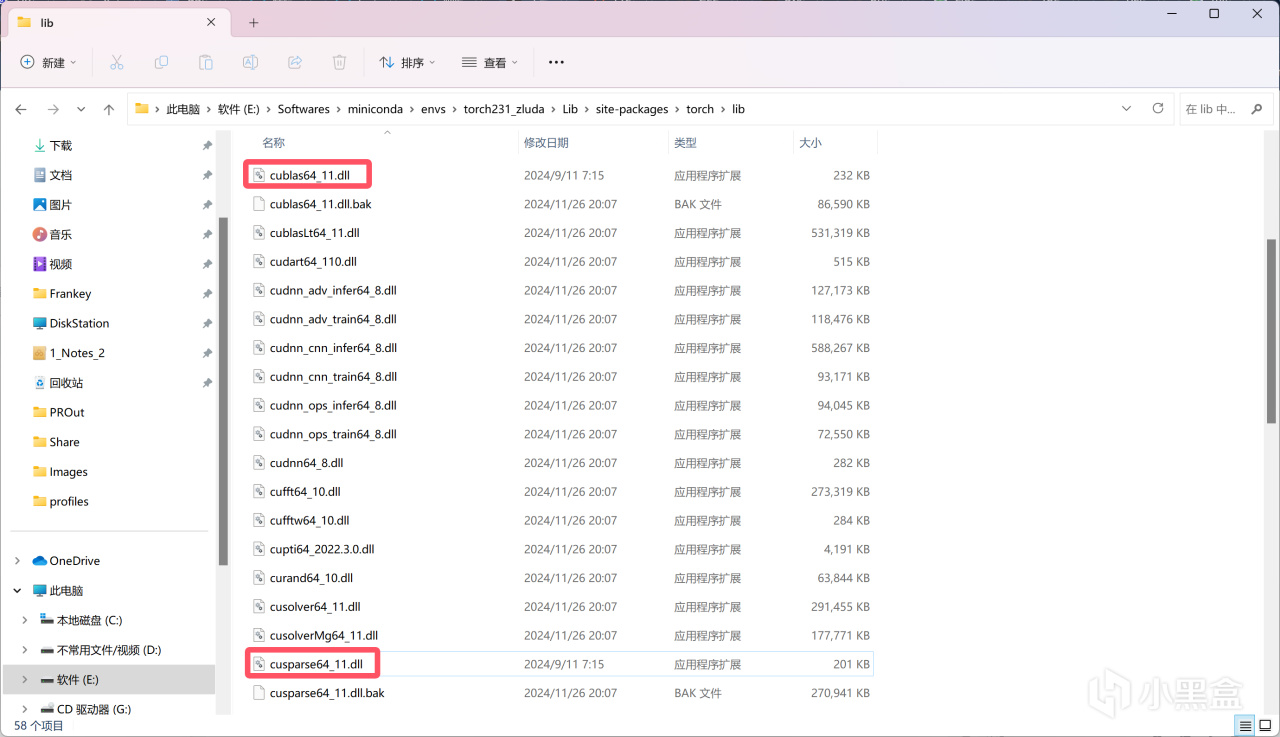
重命名以啓用
此時與WSL相同,在命令行中運行如下指令驗證是否可調用GPU:
python
import torch
torch.cuda.is_available()
正常情況下應該輸出爲True,說明已經可以通過Zluda調用你的AMD GPU進行計算:
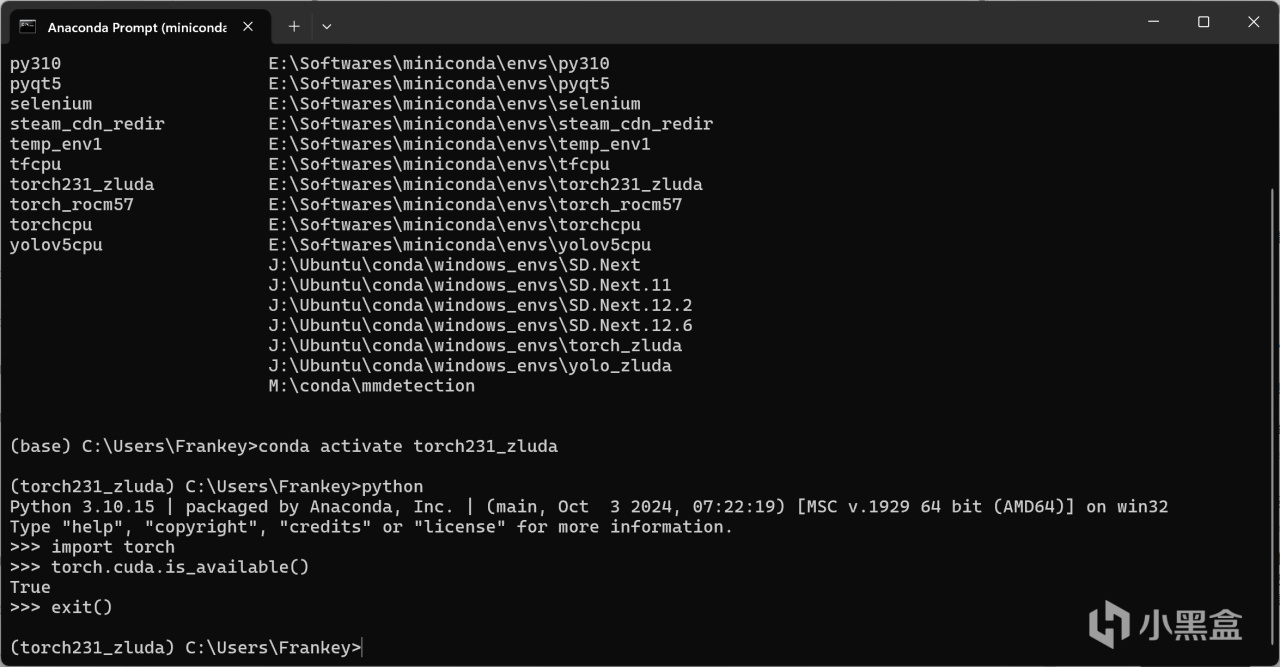
torch.cuda.is_available()
同樣地,輸入exit()來退出python。
需要注意的是,如果你在上面安裝了不受支持的pytorch版本(如2.5.1),儘管這裏torch.cuda.is_available()返回的是True,甚至你創建兩個張量移動到GPU上相加並打印都完全沒有問題,但是當你實際運行神經網絡(如最基本的ResNet18)的時候依然會報CUDA錯誤,該錯誤主要出現在linear線性層進行計算的時候,具體原因未知,但至少正確版本的pytorch能保證不出現該錯誤。
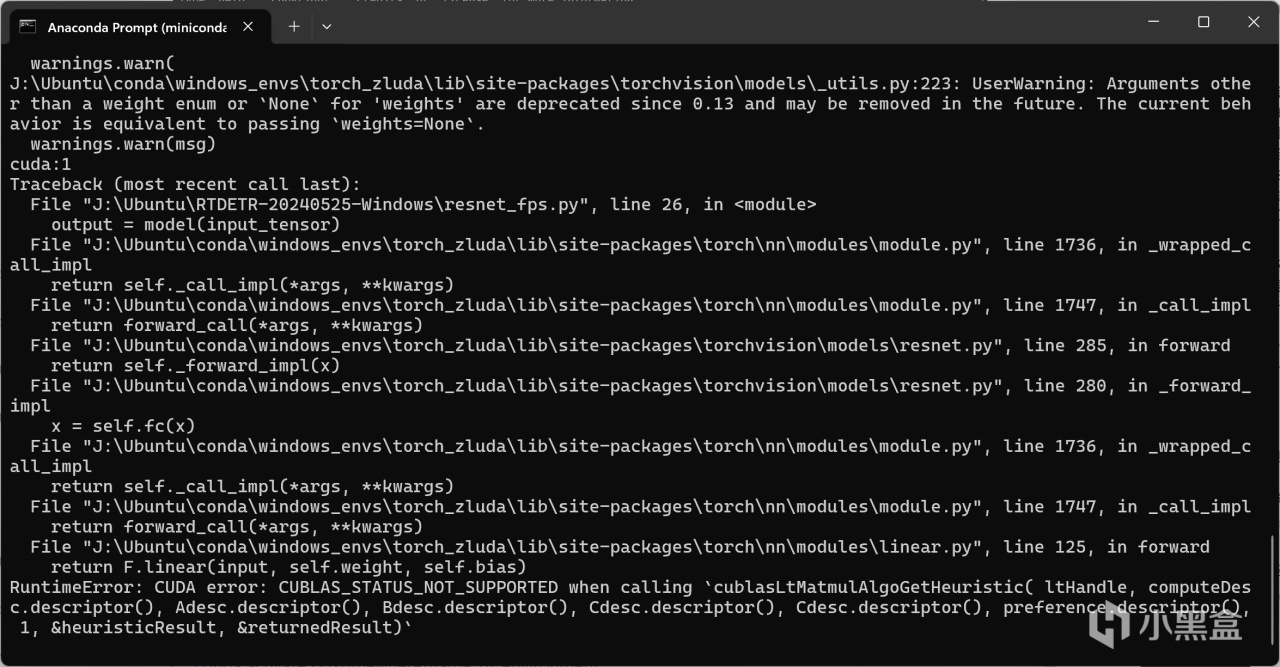
不受支持的pytorch版本導致的CUDA error: CUBLAS_STATUS_NOT_SUPPORTED
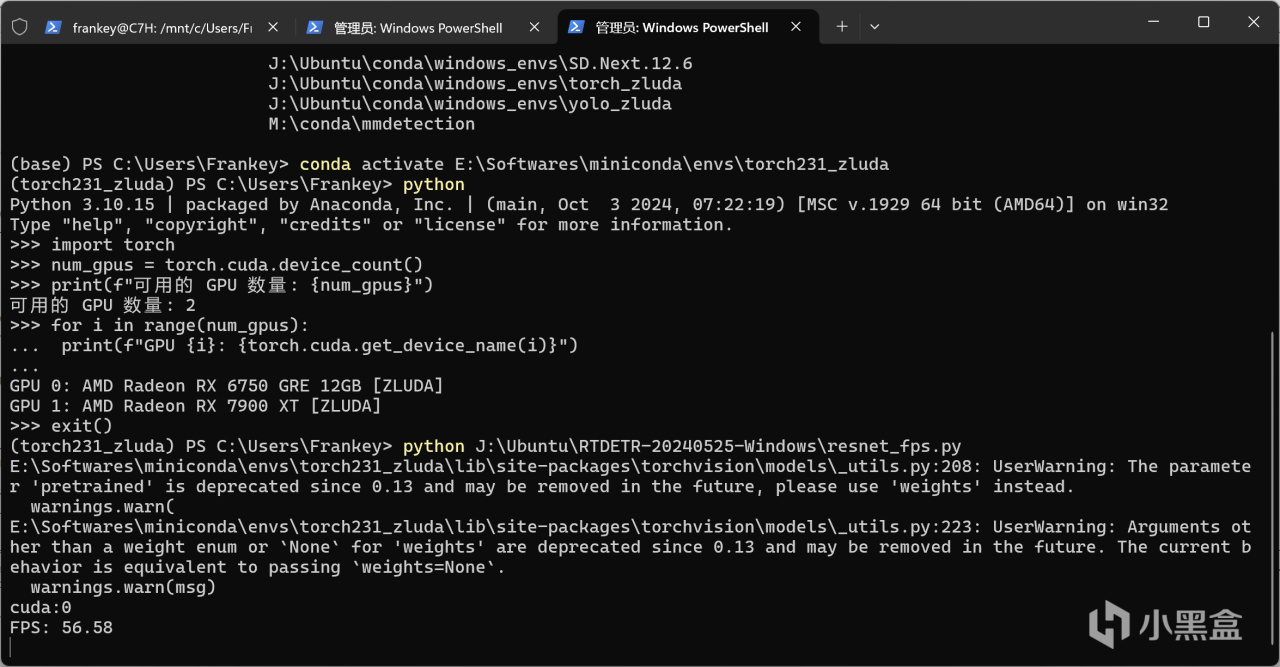
正確的pytorch版本才能正常的進行運算
另外,在通過Zluda運行一個新的torch網絡的時候,其需要編譯PTX模塊,這個過程需要耗費十幾分鍾到一個小時不等,期間終端不會有任何輸出,請耐心等待,第二次及之後運行則不需要此過程。
至此,本篇教程已完全結束,在這之後,你可以使用這些pytorch來運行繪畫模型、大語言模型、語音克隆模型、視覺模型以及其他幾乎任何現有的模型。
需要注意的是,無論是WSL還是Windows,你在本教程中安裝的pytorch可能會被一些程序的安裝腳本安裝的CPU版本的pytorch覆蓋掉,此時你就應該參考本教程,重新進行安裝。因此,這樣的環境並不是一次安裝成功就可以一勞永逸了,本教程屬於授人以漁的範疇,任何時候你需要在新的虛擬環境中安裝一個可使用AMD GPU的pytorch你都可以參考本教程進行安裝。
各位在參照本教程進行環境安裝的時候遇到任何問題均可在評論區留言,我有時間會回答,但是網絡問題除外,一切與網絡相關的問題請自行解決。
補充
最後補充一些其他的conda命令:
裝上pytorch等包的環境會非常大(數個到數十個GB不等),如果你想把環境安裝到其他位置,乃至和我一樣安裝到NAS中,請使用--prefix參數:
conda create --prefix D:/somewhere/name_of_environment python=3.10
此時要激活你的環境就需要輸入完整路徑:
conda activate D:/somewhere/name_of_environment
注:WSL上通過NFS掛載NAS的硬盤有時會出現一些奇怪的BUG(物理機無此問題),儘管我通過一些辦法進行了解決,但由於無法穩定進行復現,所以本篇教程不做闡述。
如果你想從基礎環境複製一個新的環境而不是重新安裝,請使用--clone參數:
conda create --prefix D:/somewhere/name_of_environment --clone D:/somewhere/original_environment
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















