前言
你有没有过哪首非常喜欢的歌,想要翻唱却苦于找不到合适的伴奏?
想要练习鼓点但是原音频太错综复杂难以辨识?
想要简单轻松的扒出一首歌的旋律和和弦但是却总是听不出来?
还需要纠结这个的时代已经 结 束 辣 !
只需要一键就可以轻松提取歌曲伴奏的神器,当然就是————
超级臭氧izotope rx10......才怪!
当然是Ultimate Vocal Remover
(开玩笑,臭氧我怎么可能买得起,再说臭氧的效果跟这个其实差的不大)
介绍
项目仓库: https://github.com/Anjok07/ultimatevocalremovergui
官方网站:https://ultimatevocalremover.com/
面向平台:Windows10及以上 / MacOS / Linux
硬件需求:
- 支持使用CPU/GPU推理
- (如果使用硬件加速)必须为Nvidia显卡,并且支持CUDA,最低要求为 1060 6GB, 并且推荐显存大于8GB
- Readen显卡不支持(因为是基于神经网络,悲
- Intel显卡不支持
使用
完成安装后,双击桌面上的UVR图标,打开软件首先蹦出来的是一个非常Professional的弹窗。

很显然你至少是需要等一会的,因为UVR每次启动的时候都会加载一次默认模型,加载完了就会自动进入软件的主界面。

啊你说为什么没中文,因为我相信各位盒友应该都是不需要担心这个问题的(心虚
所以简单的让我们先来介绍一下这个界面。

首先是文件输入/输出栏,左侧上下两个按钮分别是”Select Input“选择输入文件和”Select Output“选择输出目录。点击就会打开文件浏览器让你选择你需要处理的音频文件或选择你要输出文件的目录。比如这里就是我选择了一首超常MAIMAI准备提取它的伴奏并选择下载文件夹作为它的输出目录。
而右侧的两个小文件夹按钮,则会在点击后直接打开对应的目录,方便你浏览其中的文件。(如果你的电脑上没有安装Ffmpeg,那么Flac和Mp3应该是不可用的)

这三个按钮可以用来选择需要输出的文件格式,直接选择对应的格式即可。
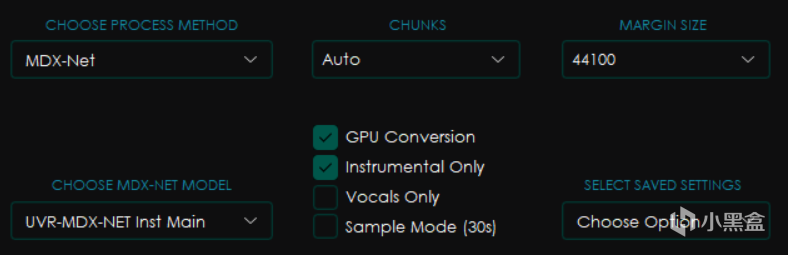
下面的一部分界面则包含了uvr最重要的主要功能设置。
首先是CHOOSE PROCESS METHOD 即 选择处理方式。
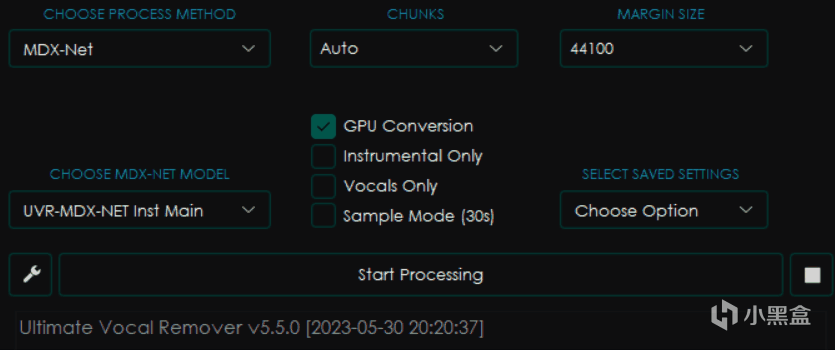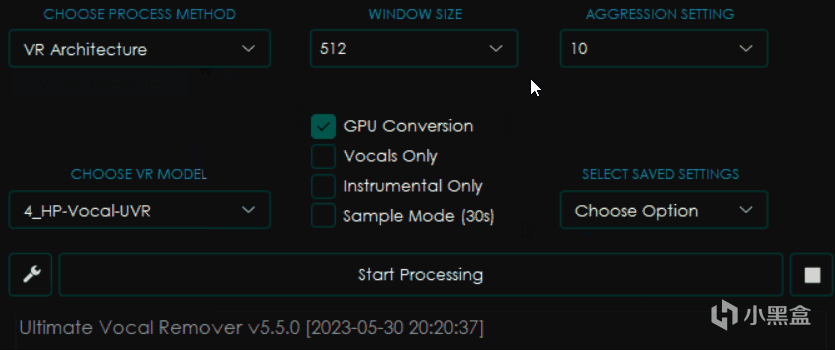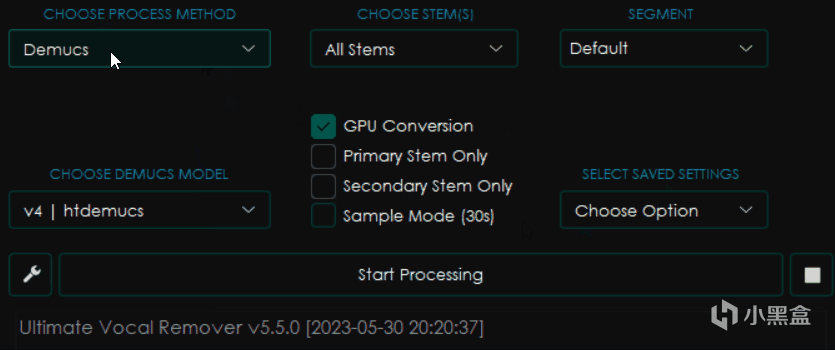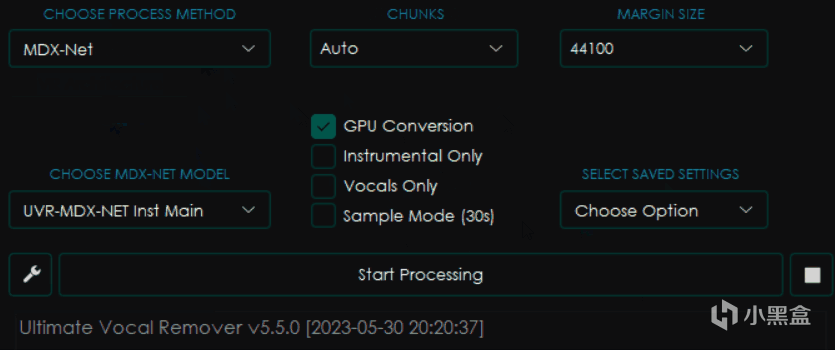
可以见到我修改了其中的选项之后,旁边的界面都发生了变化,这是因为不同的模型会有不同的参数设置。

目前UVR的主要处理模型类别包括三种,即VR Architecture、MDX-Net、Demucs,而另外两个选项则分别是多模型组合模式和音频处理工具,这篇文章里暂时不做更多探讨。
如果盒友们想知道多模型组合效果是什么样的以及怎么使用再以及每个模型有什么不同,可以cy等后续,如果想看的人多下次马上写,当然下次是多久以后这个我也不好说
其中VR架构和MDX-Net是目前效果比较好的降噪、提取伴奏模型,而Demucs则主要负责提取音频中的各种乐器部分,也包括人声。
MDX-Net
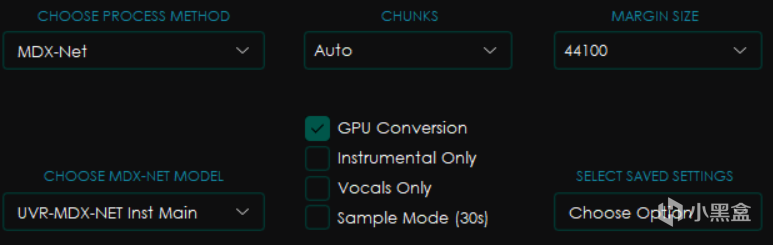
首先是CHOOSE MDX-NET MODEL,也就是选择模型。

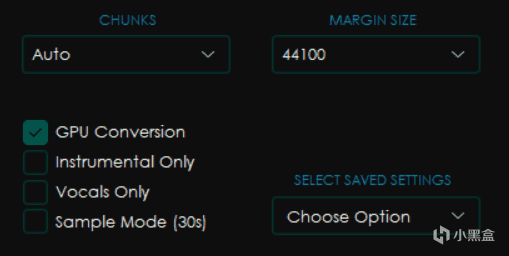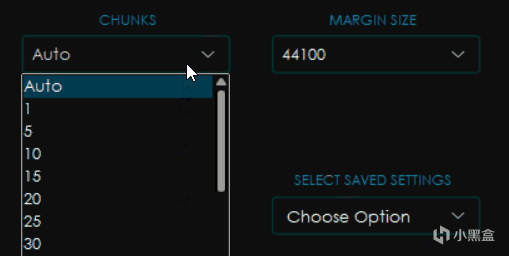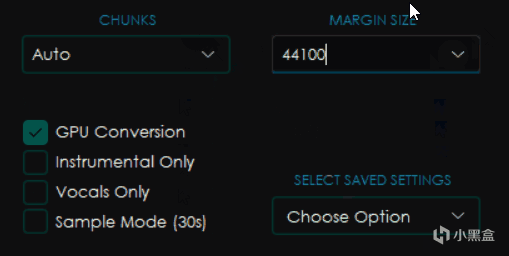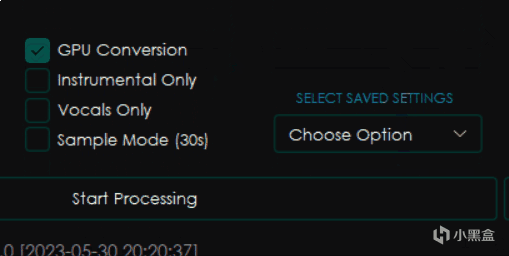
然后右边选项分别是CHUNKS块大小和MARGIN SIZE(实际上就是目标采样率,只有默认的这个模型有,其他模型会有其他选项,比如Noise)
块大小会影响处理过程的显存和内存占用,一般来讲设置的越小占用越小,但是处理也越慢,选择Auto会自动根据你电脑的配置进行修改,而Full则是 威 力 全 开 M O D E ⭐(你最好有这么多显存)
下面的点选框中分别是GPU Conversion使用显卡转换,Instrumental Only仅伴奏,Vocals Only仅人声和Sample Mode采样模式(就是只截取30秒)
而SELECT SAVED SETTINGS选项组则是可以选择保存配置的方式,其中的Save Current Settings是将当前设置保存为可以指定名字的预设,而Reset To Default则是恢复默认设置。
VR Architecture
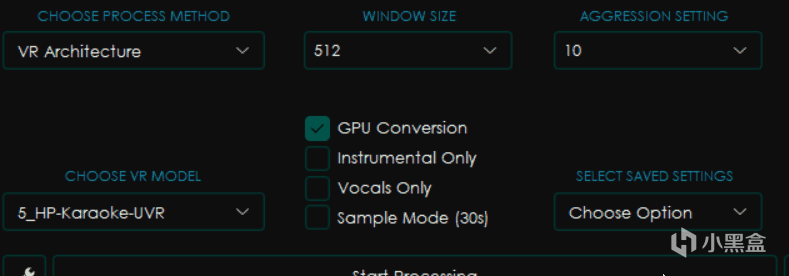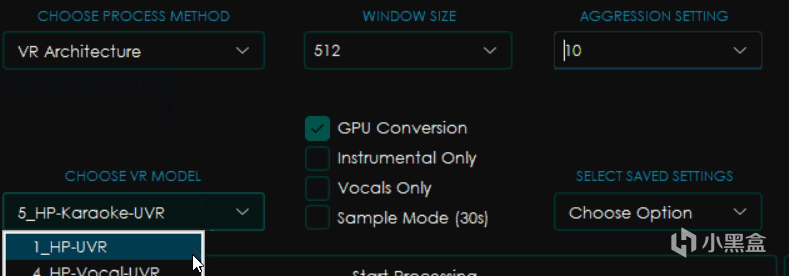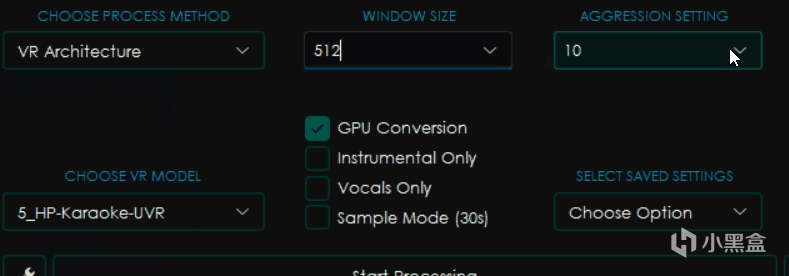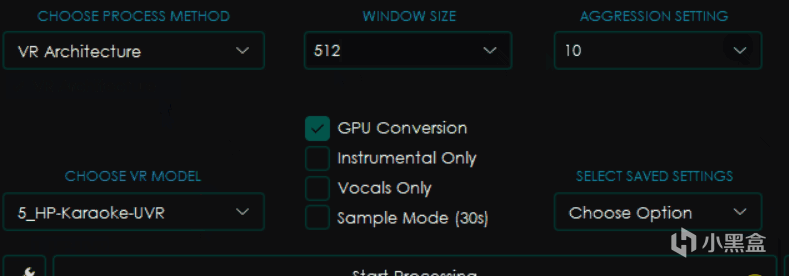
大部分和MDX-Net相同,不过有所区别的是右边变成了WINDOW SIZE窗口大小和AGGRESSION SETTING力度设置。
一般来讲窗口大小越小,处理音频的效果就越好,但是消耗的时间和内存显存占用也更大,一般为了高质量会选择320。
而力度设置则会影响去除声音的力度,越大提取的力度越强,但是并不一定是越大越好,这个值具体在多少可以得到最佳效果是一个玄学问题,只能上手之后才知道。
Demucs
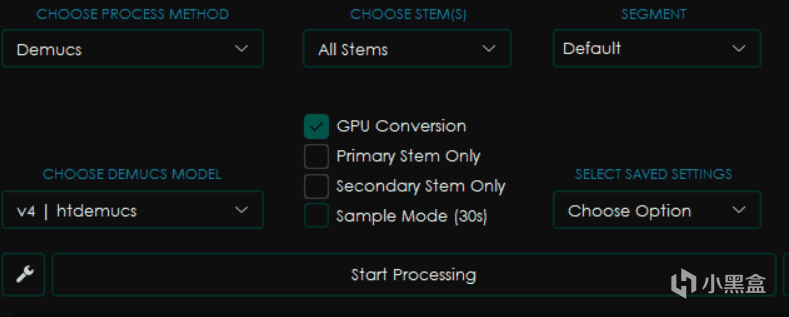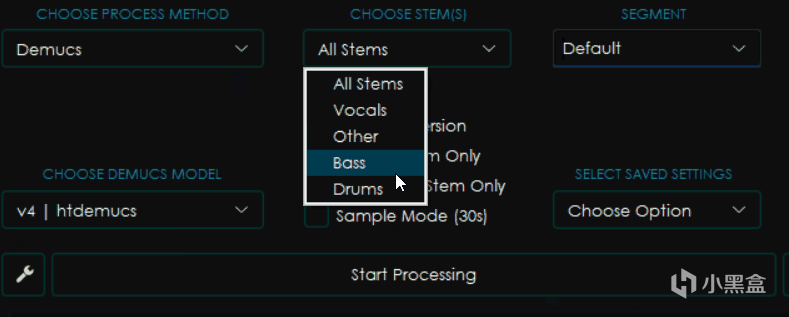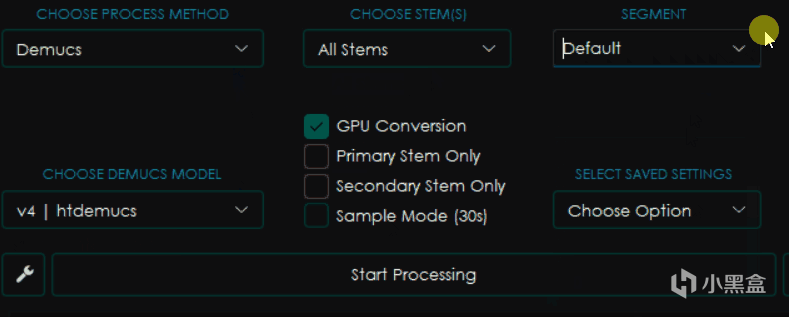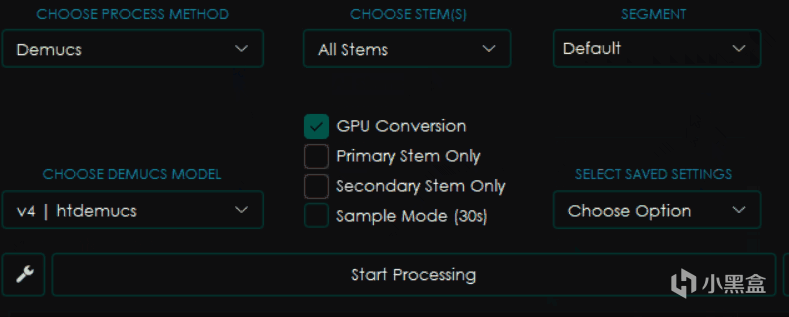
一样是看起来差不多的界面,不过这回又有了新的变化。
CHOOSE STEMS选择音轨,这个选项内一般包含Vocals人声,Other所有其他音轨,Bass贝斯,Drums鼓点以及All Stems也就是输出所有它能区分的音轨。
SEGMENT分块,类似于CHUNK,越小使用的内存和显存则越少,但是影响速度。
Primary Stem Only只保留主音轨,选择之后输出的只有你在上面选择的那部分音轨。
Secondary Stem Only只保留副音轨,选择后只会输出你选择的音轨以外的音轨。
下载新模型
很显然,默认自带的这些模型是不一定能满足我们的所有需求的,所以UVR也附带了许多的社区模型,可以供大家下载。
首先是要找到Start Processing左边的这个小小扳手按钮,这就是UVR的设置按钮。
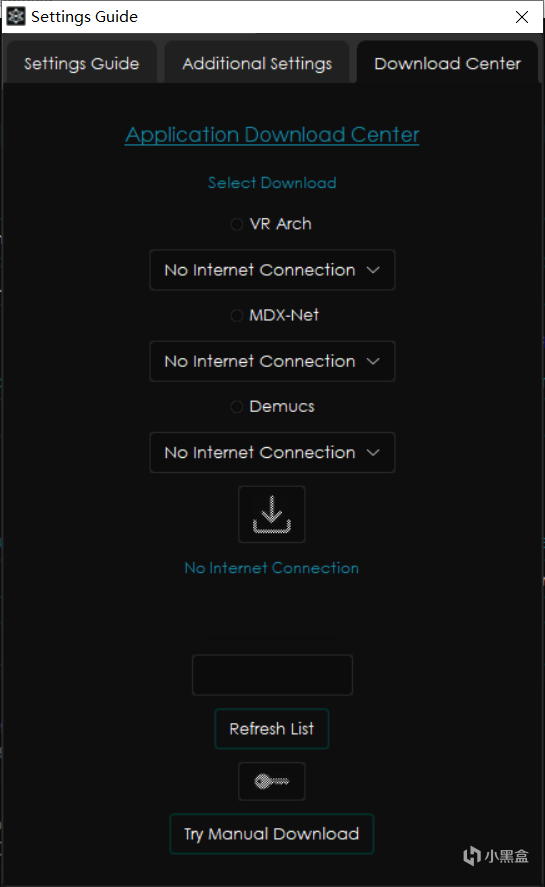
打开并找到其中的Download Center下载中心。
很显然,想要下载模型,我们需要一点奇妙的方法,但是条件限制这里就不能演示了,不过其实你只需要选择对应的处理方法的选项,然后在下面的选项组里选择你需要的模型,再点下面的下载,稍等一会模型就会被下载到你的电脑上了!
开始处理
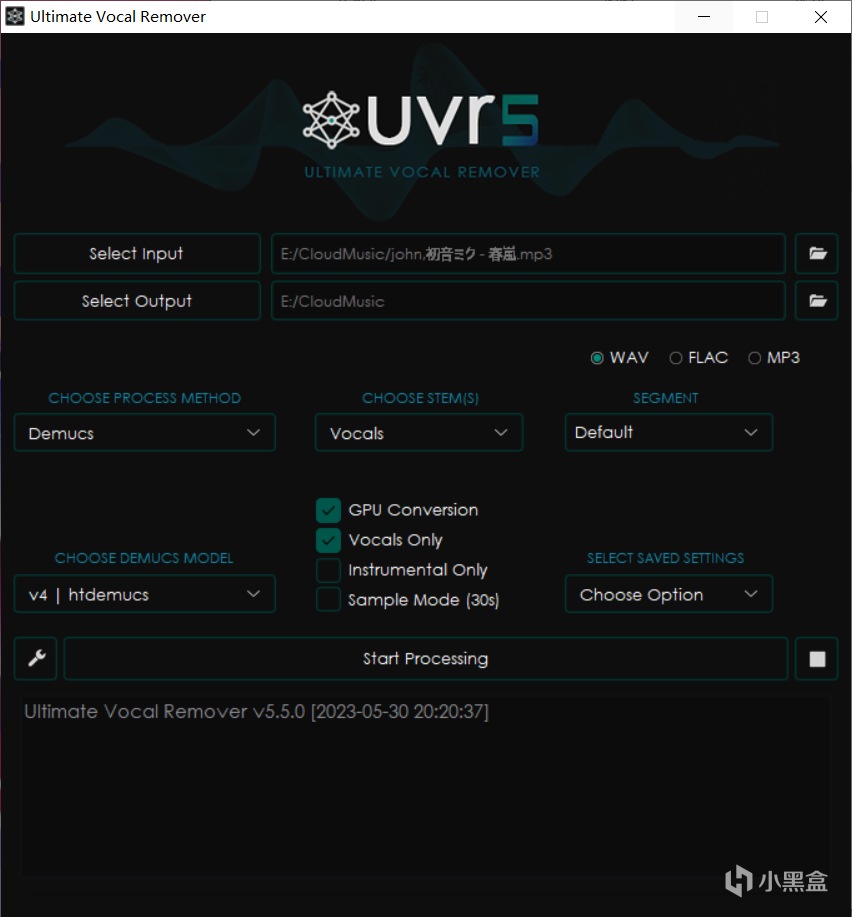
今日推歌推歌推歌春岚真的很好听
现在咱们已经完成了模型的配置,我们只需要选择好输入输出的目录,然后点那个大大大大大大大大大的Start Processing!
进度条跑完,处理好的音频就已经躺在你设置好的输出文件夹了(x
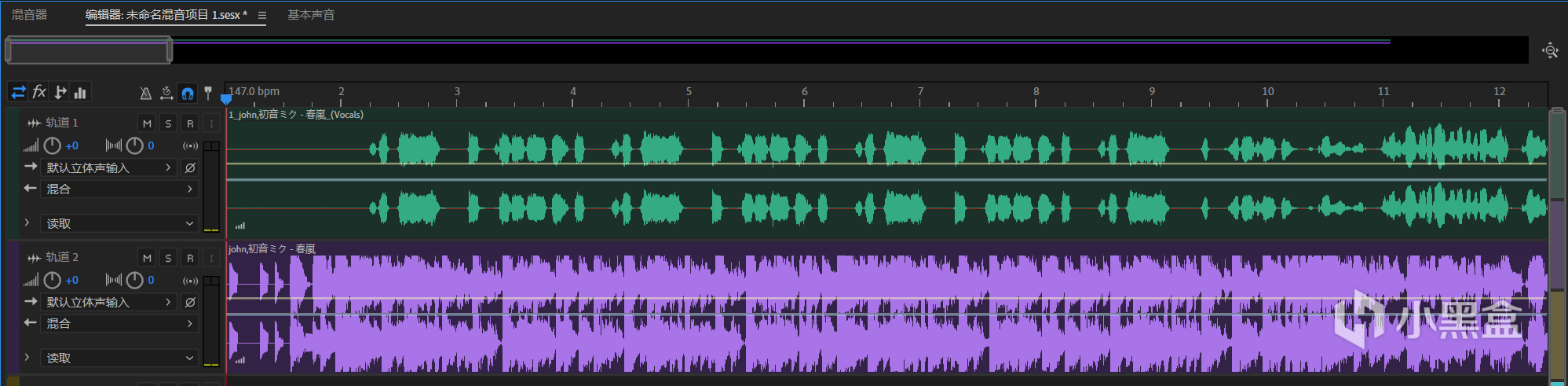
能看出来提取的干声还是比较干净的,但是具体效果要看你使用的模型种类以及你输入的音频来定。
尾声
这期开源项目介绍又到了结束时间啦。
我写文的风格比较偏向口语和日常博客,所以如果各位发现了哪里写的有错误也欢迎评论区捉虫。
如果你觉得这篇文章很有用,请狠狠的为我充电以及点赞(孩子就是喜欢被电的感觉(不是
或者如果你觉得以后可能会用到也请记得cy一下
顺便本日推荐歌曲:
当然是文中已经出现过的春岚啦
阿b传送门:

那么一如既往,下期再见!
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com








![[cube_超人]给我来点爷们儿用的香!](https://imgheybox1.max-c.com/bbs/2025/04/21/e46f2d7bce4b878289330d7d04856c3e.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)








