为什么要本地部署?
本地部署的模型不需要联网(dddd),不会出现服务器繁忙,且能够很好的保护隐私...
注意:
本地部署只推荐有独立显卡的用户且内存16+
核显推荐12+代CUP
话不多说,直接开始
1.下载部署模型的软件LM Studio
官网:https://lmstudio.ai
根据自己的系统进行下载,正常安装过程,记住安装的路径
LM Studio下载
2.进入LM Studio
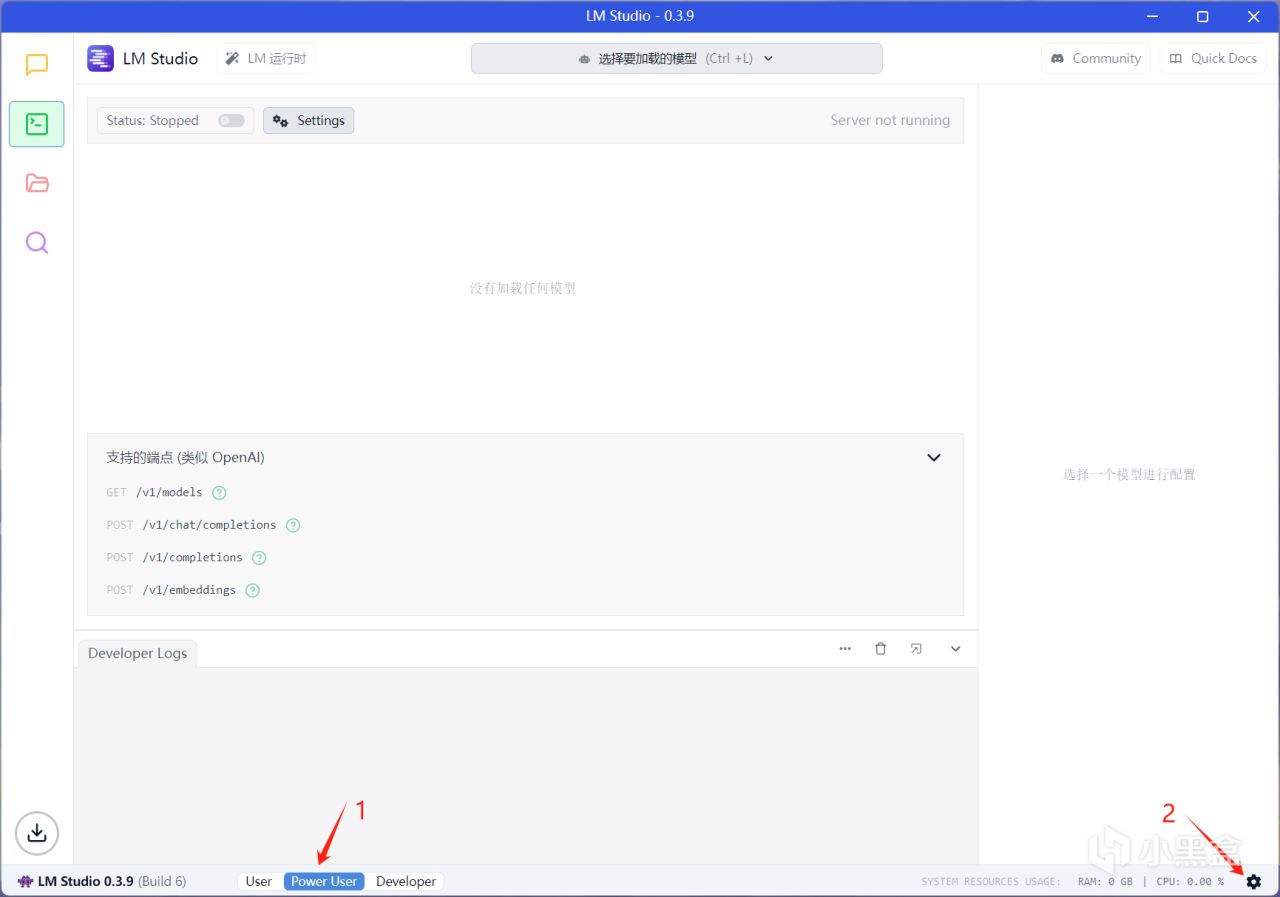
LM界面
3.设置中文
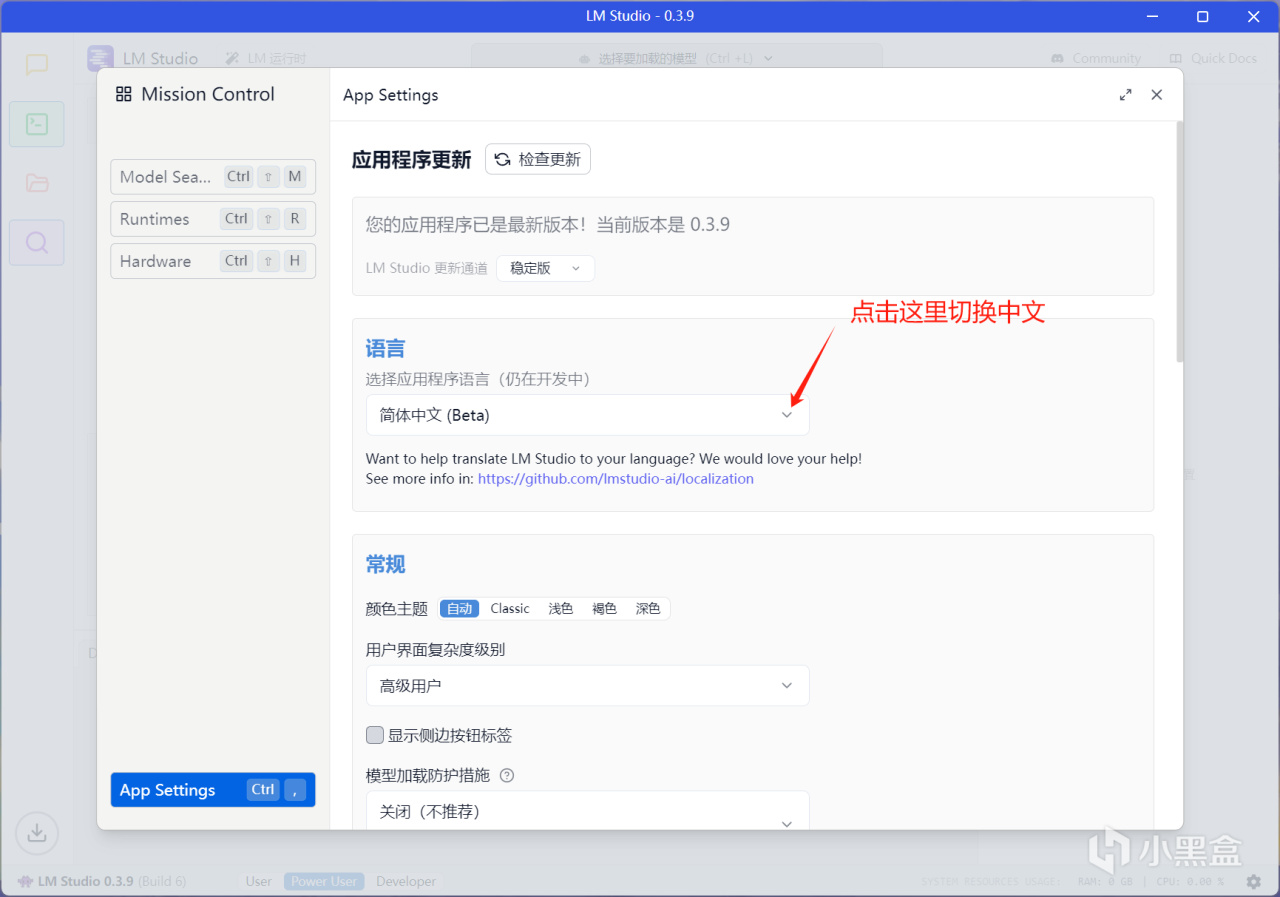
4.下载要本地部署的蒸馏模型(需要魔法,没有魔法的看文章末尾,使用镜像网站下载)

需要魔法才可以下载
5.选择自己要部署的模型
推荐上32B Q4模型,效果最佳,笔记本3050 4g都可运行,只是速度较慢
没有GPU:1.5B Q8推理 或者 8B Q4推理
4G GPU:8B Q4推理
8G GPU:32B Q4推理 或者 8B Q4推理
16G GPU:32B Q4推理 或者 32B Q8推理
24G GPU: 32B Q8推理 或者 70B Q2推理

需要魔法才能看得到右边页面
6.查看自己下载好的模型

模型目录
7.选择聊天

聊天界面
8.选择要加载的模型
注意:如果选太高,内存占满电脑会直接卡死!!!选小一点,再根据电脑占用情况进行调整。进度条拉不动可以直接输入数字。

配置模型
9.模型完成加载

加载完成
10.模型加载完成之后就可以进行对话啦。(到这里,就可以直接拔网线进行对话了,模型自己推理得出结果)

直接对话
没有魔法的看这里
访问:https://hf-mirror.com这个镜像网站,顶部进行搜索
(一定要下载GGUF文件,这样才可以在LM里面运行)
推荐上32B Q4模型,效果最佳,笔记本3050 4g都可运行,只是速度较慢
没有GPU:1.5B Q8推理 或者 8B Q4推理
4G GPU:8B Q4推理
8G GPU:32B Q4推理 或者 8B Q4推理
16G GPU:32B Q4推理 或者 32B Q8推理
24G GPU: 32B Q8推理 或者 70B Q2推理

搜索模型

查找模型

下载模型
这里,我们可以在LM里面看到默认路径,点击更改,和我一样选择一个新路径,需要嵌套文件夹,不然无法识别到

模型文件夹
恭喜你,到这里,属于自己本地的AI模型就部署成功了,有什么问题评论区。
感兴趣下期带来如何真正的关闭联网,优化最佳性能,榨干电脑所用性能
部分素材来源:B站-NathMath
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com








![我和妹妹就是在成年人世界里逆行的青少年同伙(本篇为妹妹执笔[cube_悟空])](https://imgheybox1.max-c.com/bbs/2025/02/08/37d1c30ef45845ddc52f1a52a8e3b7d9.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)








