前言
你有沒有過哪首非常喜歡的歌,想要翻唱卻苦於找不到合適的伴奏?
想要練習鼓點但是原音頻太錯綜複雜難以辨識?
想要簡單輕鬆的扒出一首歌的旋律和和絃但是卻總是聽不出來?
還需要糾結這個的時代已經 結 束 辣 !
只需要一鍵就可以輕鬆提取歌曲伴奏的神器,當然就是————
超級臭氧izotope rx10......纔怪!
當然是Ultimate Vocal Remover
(開玩笑,臭氧我怎麼可能買得起,再說臭氧的效果跟這個其實差的不大)
介紹
項目倉庫: https://github.com/Anjok07/ultimatevocalremovergui
官方網站:https://ultimatevocalremover.com/
面向平臺:Windows10及以上 / MacOS / Linux
硬件需求:
- 支持使用CPU/GPU推理
- (如果使用硬件加速)必須爲Nvidia顯卡,並且支持CUDA,最低要求爲 1060 6GB, 並且推薦顯存大於8GB
- Readen顯卡不支持(因爲是基於神經網絡,悲
- Intel顯卡不支持
使用
完成安裝後,雙擊桌面上的UVR圖標,打開軟件首先蹦出來的是一個非常Professional的彈窗。

很顯然你至少是需要等一會的,因爲UVR每次啓動的時候都會加載一次默認模型,加載完了就會自動進入軟件的主界面。

啊你說爲什麼沒中文,因爲我相信各位盒友應該都是不需要擔心這個問題的(心虛
所以簡單的讓我們先來介紹一下這個界面。

首先是文件輸入/輸出欄,左側上下兩個按鈕分別是”Select Input“選擇輸入文件和”Select Output“選擇輸出目錄。點擊就會打開文件瀏覽器讓你選擇你需要處理的音頻文件或選擇你要輸出文件的目錄。比如這裏就是我選擇了一首超常MAIMAI準備提取它的伴奏並選擇下載文件夾作爲它的輸出目錄。
而右側的兩個小文件夾按鈕,則會在點擊後直接打開對應的目錄,方便你瀏覽其中的文件。(如果你的電腦上沒有安裝Ffmpeg,那麼Flac和Mp3應該是不可用的)

這三個按鈕可以用來選擇需要輸出的文件格式,直接選擇對應的格式即可。
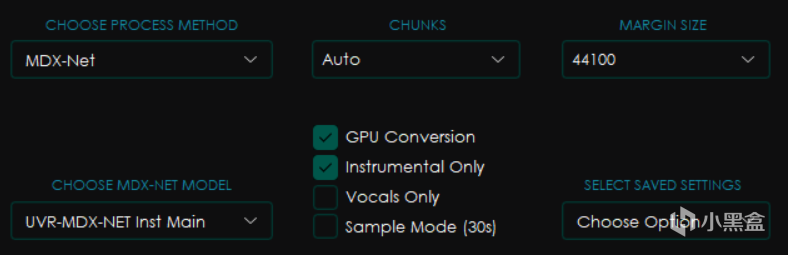
下面的一部分界面則包含了uvr最重要的主要功能設置。
首先是CHOOSE PROCESS METHOD 即 選擇處理方式。
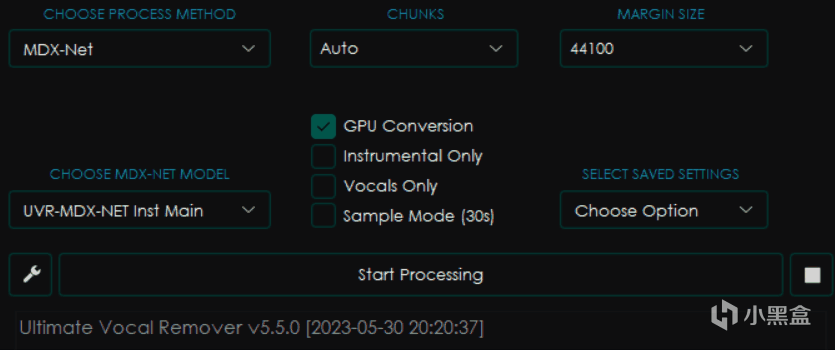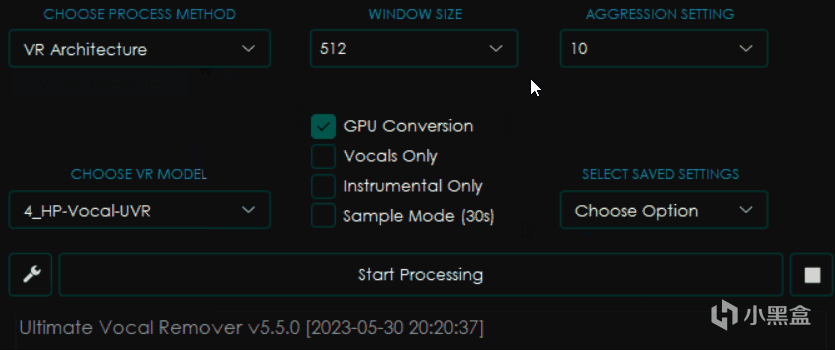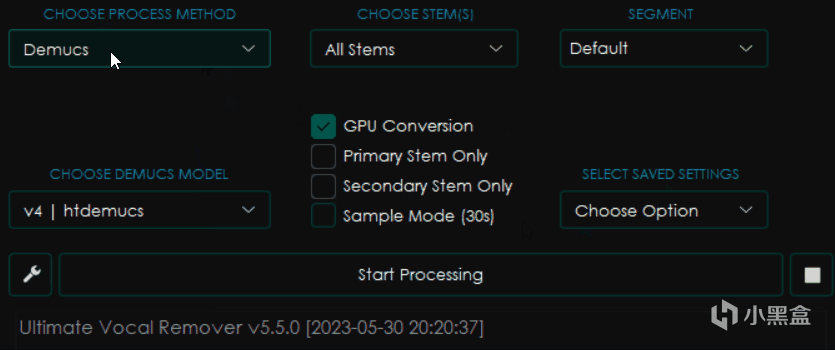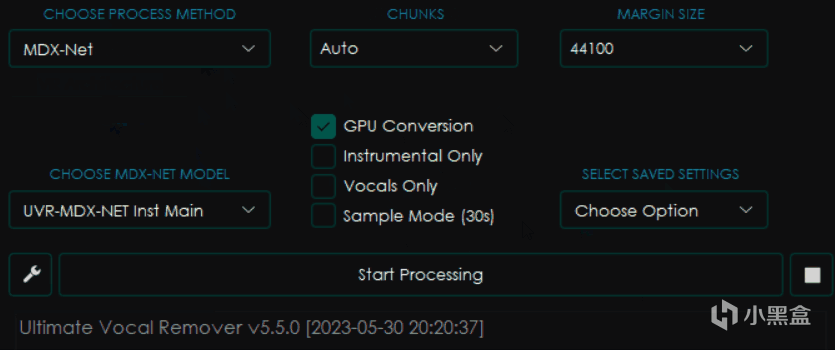
可以見到我修改了其中的選項之後,旁邊的界面都發生了變化,這是因爲不同的模型會有不同的參數設置。

目前UVR的主要處理模型類別包括三種,即VR Architecture、MDX-Net、Demucs,而另外兩個選項則分別是多模型組合模式和音頻處理工具,這篇文章裏暫時不做更多探討。
如果盒友們想知道多模型組合效果是什麼樣的以及怎麼使用再以及每個模型有什麼不同,可以cy等後續,如果想看的人多下次馬上寫,當然下次是多久以後這個我也不好說
其中VR架構和MDX-Net是目前效果比較好的降噪、提取伴奏模型,而Demucs則主要負責提取音頻中的各種樂器部分,也包括人聲。
MDX-Net
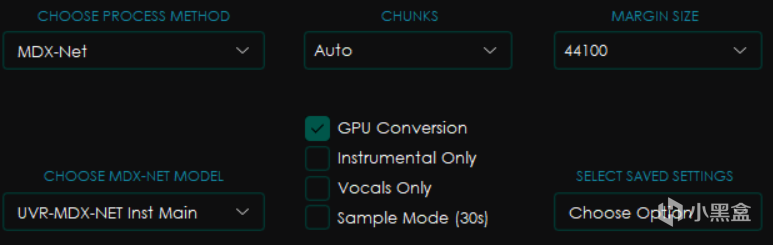
首先是CHOOSE MDX-NET MODEL,也就是選擇模型。

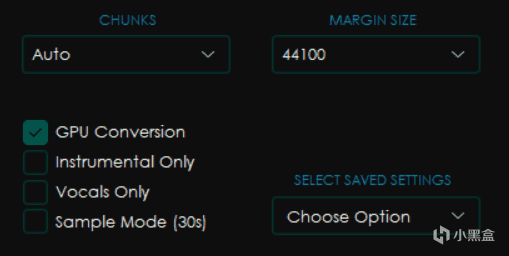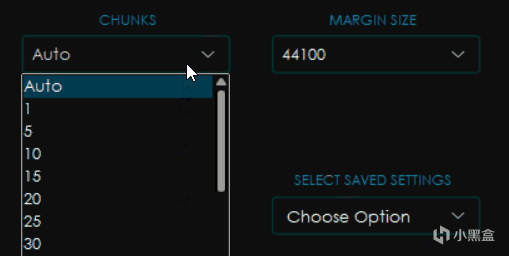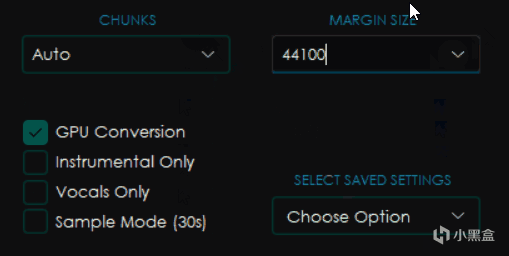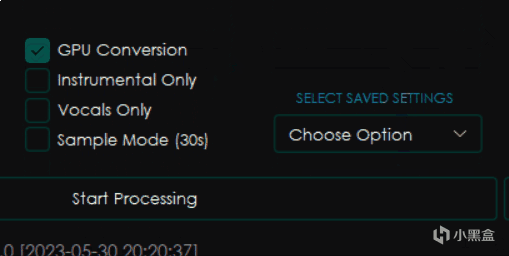
然後右邊選項分別是CHUNKS塊大小和MARGIN SIZE(實際上就是目標採樣率,只有默認的這個模型有,其他模型會有其他選項,比如Noise)
塊大小會影響處理過程的顯存和內存佔用,一般來講設置的越小佔用越小,但是處理也越慢,選擇Auto會自動根據你電腦的配置進行修改,而Full則是 威 力 全 開 M O D E ⭐(你最好有這麼多顯存)
下面的點選框中分別是GPU Conversion使用顯卡轉換,Instrumental Only僅伴奏,Vocals Only僅人聲和Sample Mode採樣模式(就是隻截取30秒)
而SELECT SAVED SETTINGS選項組則是可以選擇保存配置的方式,其中的Save Current Settings是將當前設置保存爲可以指定名字的預設,而Reset To Default則是恢復默認設置。
VR Architecture
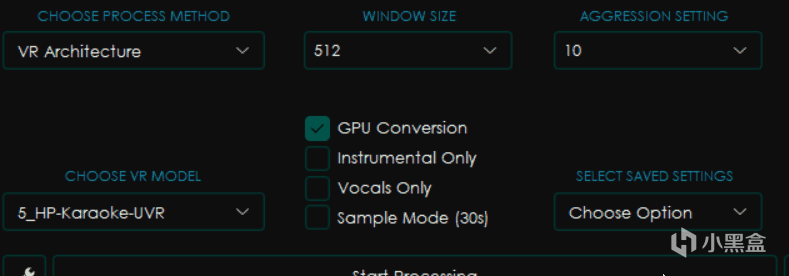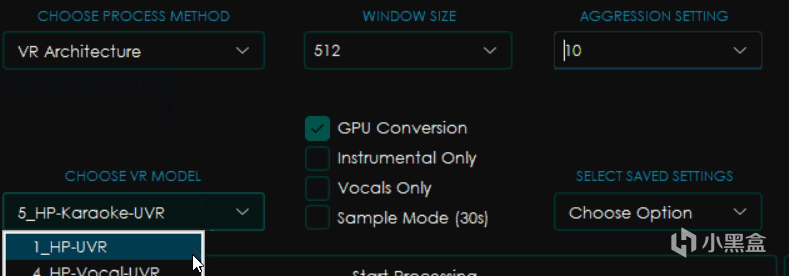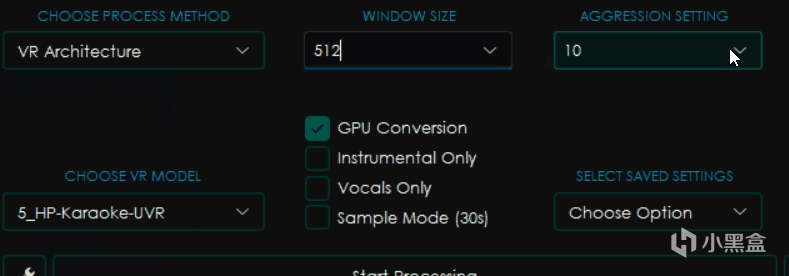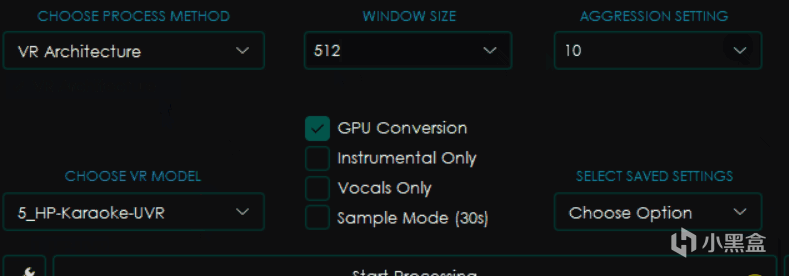
大部分和MDX-Net相同,不過有所區別的是右邊變成了WINDOW SIZE窗口大小和AGGRESSION SETTING力度設置。
一般來講窗口大小越小,處理音頻的效果就越好,但是消耗的時間和內存顯存佔用也更大,一般爲了高質量會選擇320。
而力度設置則會影響去除聲音的力度,越大提取的力度越強,但是並不一定是越大越好,這個值具體在多少可以得到最佳效果是一個玄學問題,只能上手之後才知道。
Demucs
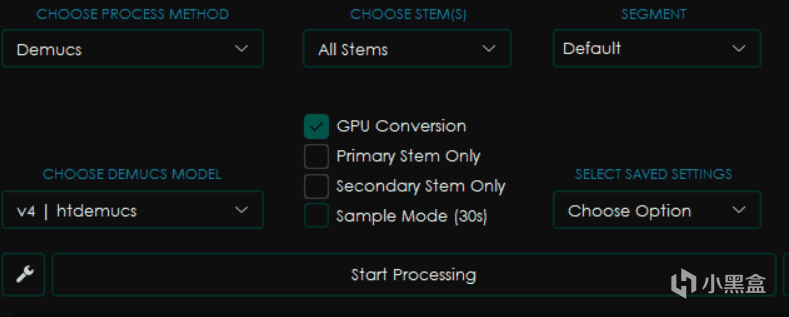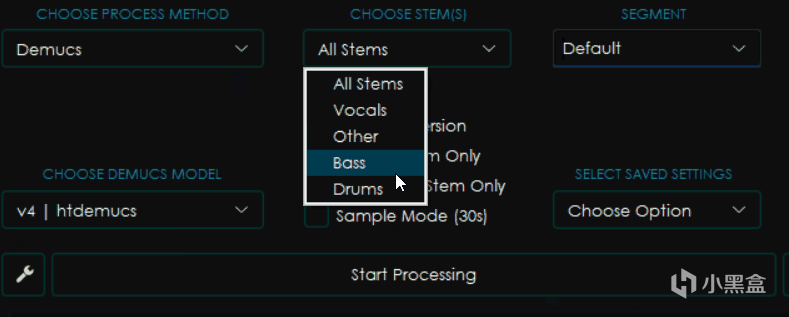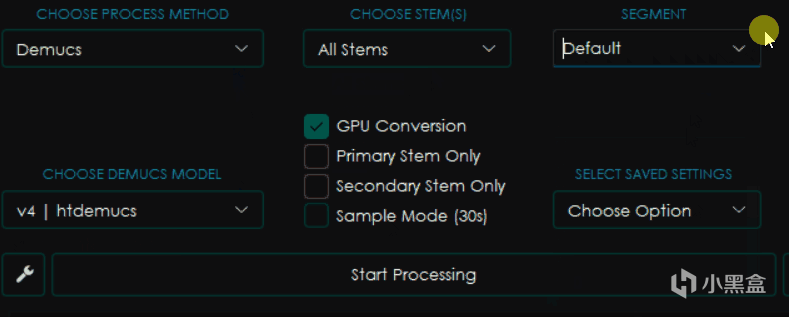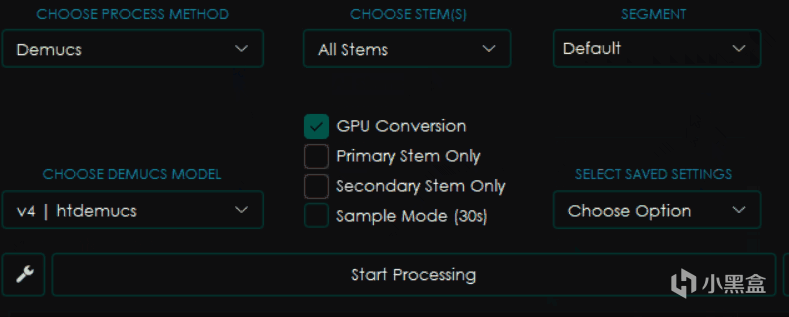
一樣是看起來差不多的界面,不過這回又有了新的變化。
CHOOSE STEMS選擇音軌,這個選項內一般包含Vocals人聲,Other所有其他音軌,Bass貝斯,Drums鼓點以及All Stems也就是輸出所有它能區分的音軌。
SEGMENT分塊,類似於CHUNK,越小使用的內存和顯存則越少,但是影響速度。
Primary Stem Only只保留主音軌,選擇之後輸出的只有你在上面選擇的那部分音軌。
Secondary Stem Only只保留副音軌,選擇後只會輸出你選擇的音軌以外的音軌。
下載新模型
很顯然,默認自帶的這些模型是不一定能滿足我們的所有需求的,所以UVR也附帶了許多的社區模型,可以供大家下載。
首先是要找到Start Processing左邊的這個小小扳手按鈕,這就是UVR的設置按鈕。
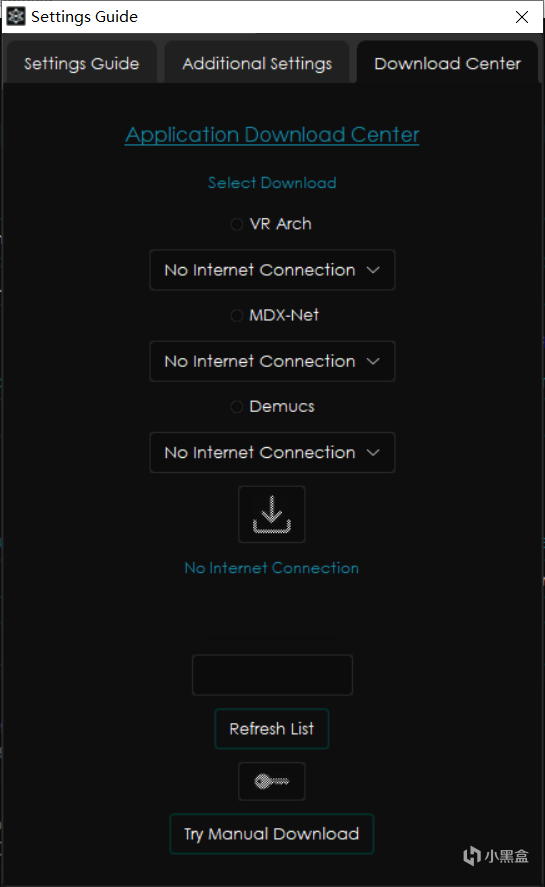
打開並找到其中的Download Center下載中心。
很顯然,想要下載模型,我們需要一點奇妙的方法,但是條件限制這裏就不能演示了,不過其實你只需要選擇對應的處理方法的選項,然後在下面的選項組裏選擇你需要的模型,再點下面的下載,稍等一會模型就會被下載到你的電腦上了!
開始處理
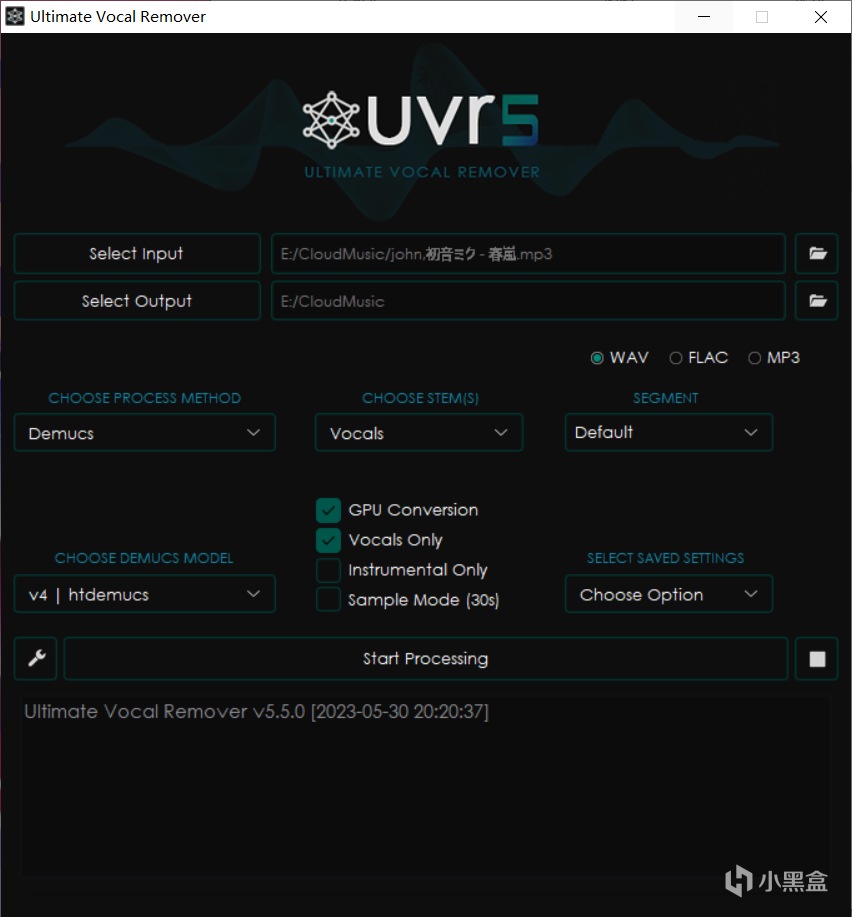
今日推歌推歌推歌春嵐真的很好聽
現在咱們已經完成了模型的配置,我們只需要選擇好輸入輸出的目錄,然後點那個大大大大大大大大大的Start Processing!
進度條跑完,處理好的音頻就已經躺在你設置好的輸出文件夾了(x
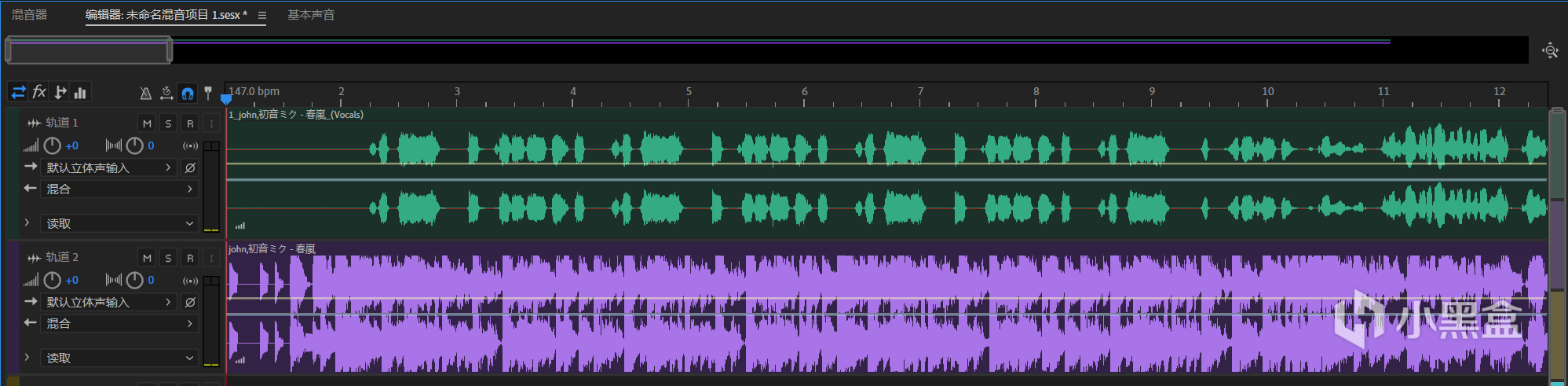
能看出來提取的幹聲還是比較乾淨的,但是具體效果要看你使用的模型種類以及你輸入的音頻來定。
尾聲
這期開源項目介紹又到了結束時間啦。
我寫文的風格比較偏向口語和日常博客,所以如果各位發現了哪裏寫的有錯誤也歡迎評論區捉蟲。
如果你覺得這篇文章很有用,請狠狠的爲我充電以及點贊(孩子就是喜歡被電的感覺(不是
或者如果你覺得以後可能會用到也請記得cy一下
順便本日推薦歌曲:
當然是文中已經出現過的春嵐啦
阿b傳送門:

那麼一如既往,下期再見!
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















