最近看到一位國外coder的觀點,覺得有點意思,分享給大家。
對人類開發者而言最優的,或者至少是我們認爲理想的,並不一定是對 AI 助手而言最優的。隨着 AI 逐步融入我們的開發流程,我們也需要做出相應的調整。你的代碼不應該只適合給人看,更應該適合給AI看。

他舉的例子主要是ts的,不過其他語言也是類似思想。
1.代碼即文檔(Documentation as Code)
傳統做法: 詳細的文檔通常存放在 Wiki、Notion 或團隊知識庫中,與代碼庫分離。
AI 友好的做法: 在項目根目錄和每個子模塊中放置詳盡的 README.md 文件。創建 CONTRIBUTING.md,說明編碼規範、PR 預期和測試覆蓋要求。如有必要,可以在源碼附近添加額外的文檔,或者在代碼中直接註釋,解釋代碼的目標和技術實現,以便 AI 更好地理解。AI 可以直接讀取這些文檔,並據此執行任務,無需額外的自定義提示或專門的 AI 指南 —— 你的項目文檔本身就變成了 AI 的操作手冊。

2.減少包的碎片化(Minimize Package Explosion)
傳統做法: 爲每個獨立功能創建一個新的包,以強化關注點分離(Separation of Concerns)。
AI 友好的做法: 採用儘可能少的包,並確保每個包的邊界清晰。只有當代碼需要在多個應用之間共享時,才創建獨立的包。
AI 代理在處理大量包時會遇到困難,就像新加入的開發者一樣。每增加一個包,AI 需要理解的不僅是代碼本身,還有它與其他包之間的關係,從而增加了認知負擔。

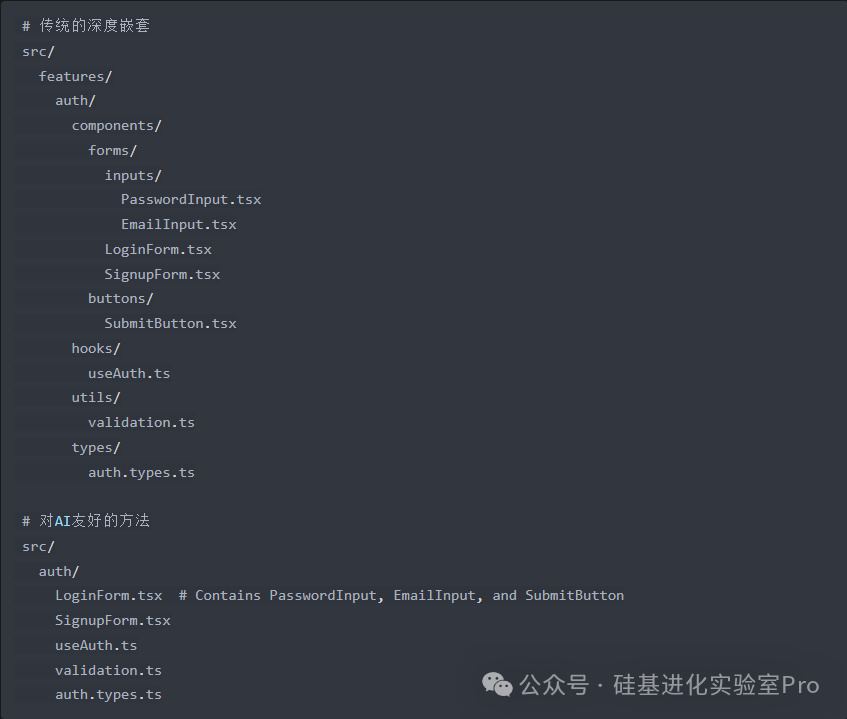
3.簡化項目結構(Simplify Project Structure)
傳統做法:採用深層嵌套的目錄結構,並拆分成許多小文件,以實現最大程度的模塊化。
AI 友好的做法: 採用更扁平的目錄結構,並使用語義清晰的命名。將相關功能放在一起,而不是分散在衆多文件和文件夾中。
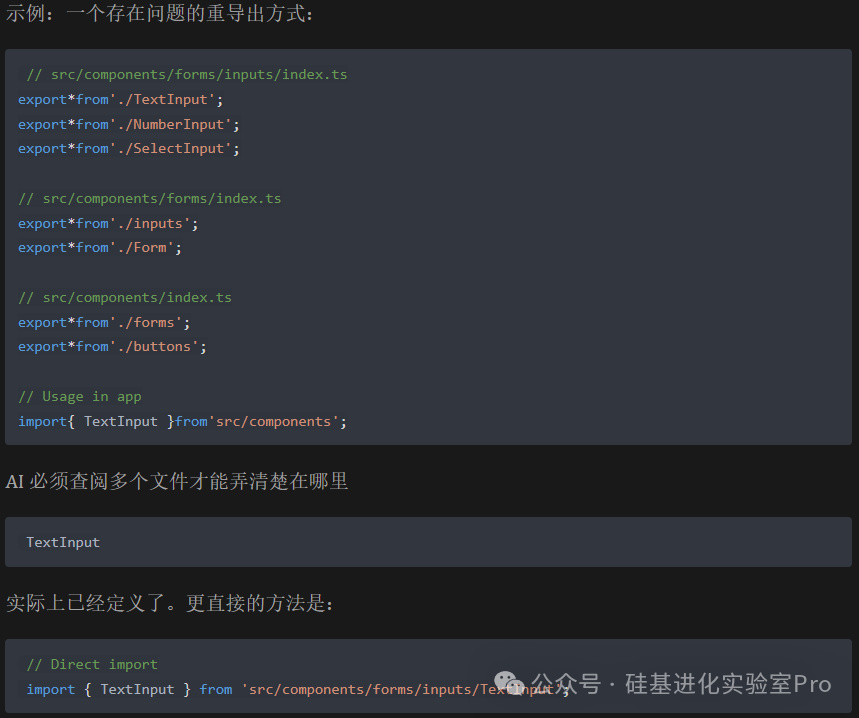
4.避免重導出和過多的間接引用(Avoid Re-exports and Indirection)
傳統做法:在每個目錄層級使用 index.ts 進行重導出,以創建整潔的公共 API。
AI 友好的做法:限制重導出僅用於包級別。內部的重導出會增加代碼的間接性,使 AI 更難追蹤依賴關係。
5.優先編譯時驗證而非運行時檢查
傳統方法:依賴運行時驗證和測試來捕捉錯誤。
AI 友好方法:儘可能將驗證推到編譯時,使用強類型和靜態分析。
6.將 Lint 規則和代碼格式化配置統一到根目錄(Consolidate Linting and Formatting at the Root Level)
傳統做法: 在 Monorepo(多包代碼倉庫)中,每個包都有自己的 ESLint 和 Prettier 配置,導致風格不一致,維護成本增加。
AI 友好的做法: 將所有 Lint 規則和代碼格式化配置集中到 項目根目錄,確保所有包的風格保持一致,同時降低維護難度。
這種方法遵循 DRY(Don’t Repeat Yourself,不要重複自己) 原則,減少了單個包的複雜度。AI 只需要理解一個統一的 Lint 配置,而不是處理多個不同的規則集。
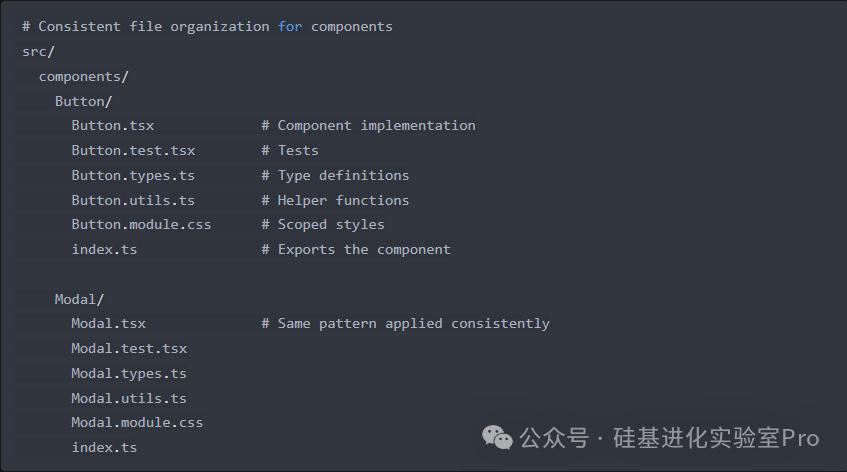
7.一致的文件組織模式
傳統方法:根據不同開發人員的偏好或不斷發展的標準,在代碼庫的不同部分以不同方式組織文件。
AI 友好方法:在組件或模塊內使用一致、可預測的文件組織模式。
AI 模型在一致的模式下工作得更好,因爲它們可以更輕鬆地預測在哪裏可以找到相關代碼以及組件應該如何結構化。這種一致性減少了 AI 和人類開發人員的認知負擔。
這種共同定位有助於 AI 理解組件的所有方面,而無需在多個目錄中搜索。一致的命名模式也使 AI 更容易預測特定功能的位置。
8.測試用例驅動的文檔
傳統方法:分別編寫文檔和測試,通常導致文檔隨着代碼庫的發展而變得過時。
AI 友好方法:使用編寫良好的測試作爲活的文檔,清楚地展示函數和組件的預期行爲。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com







![[cube_超人]給我來點爺們兒用的香!](https://imgheybox1.max-c.com/bbs/2025/04/21/e46f2d7bce4b878289330d7d04856c3e.jpeg?imageMogr2/auto-orient/ignore-error/1/format/jpg/thumbnail/398x679%3E)









