真正 “Open” 的 DeepSeek ,打出開源周的第二發炮彈,短短几個小時就已經在 GitHub 上,收穫了 3k 多星。
“ 開源老兵 ”阿里通義千問也沒閒着,推出了 QwQ-Max-Preview 深度思考模型,展示思維鏈,還支持聯網搜索。
還有凌晨兩點多,大夥兒可能還在做夢的時候,大洋彼岸的 Anthropic 也給模型升級換代了。號稱他們迄今爲止最聰明的 Claude 3.7 Sonnet ,還是個推理模型和傳統模型的 “ 混血 ” 。
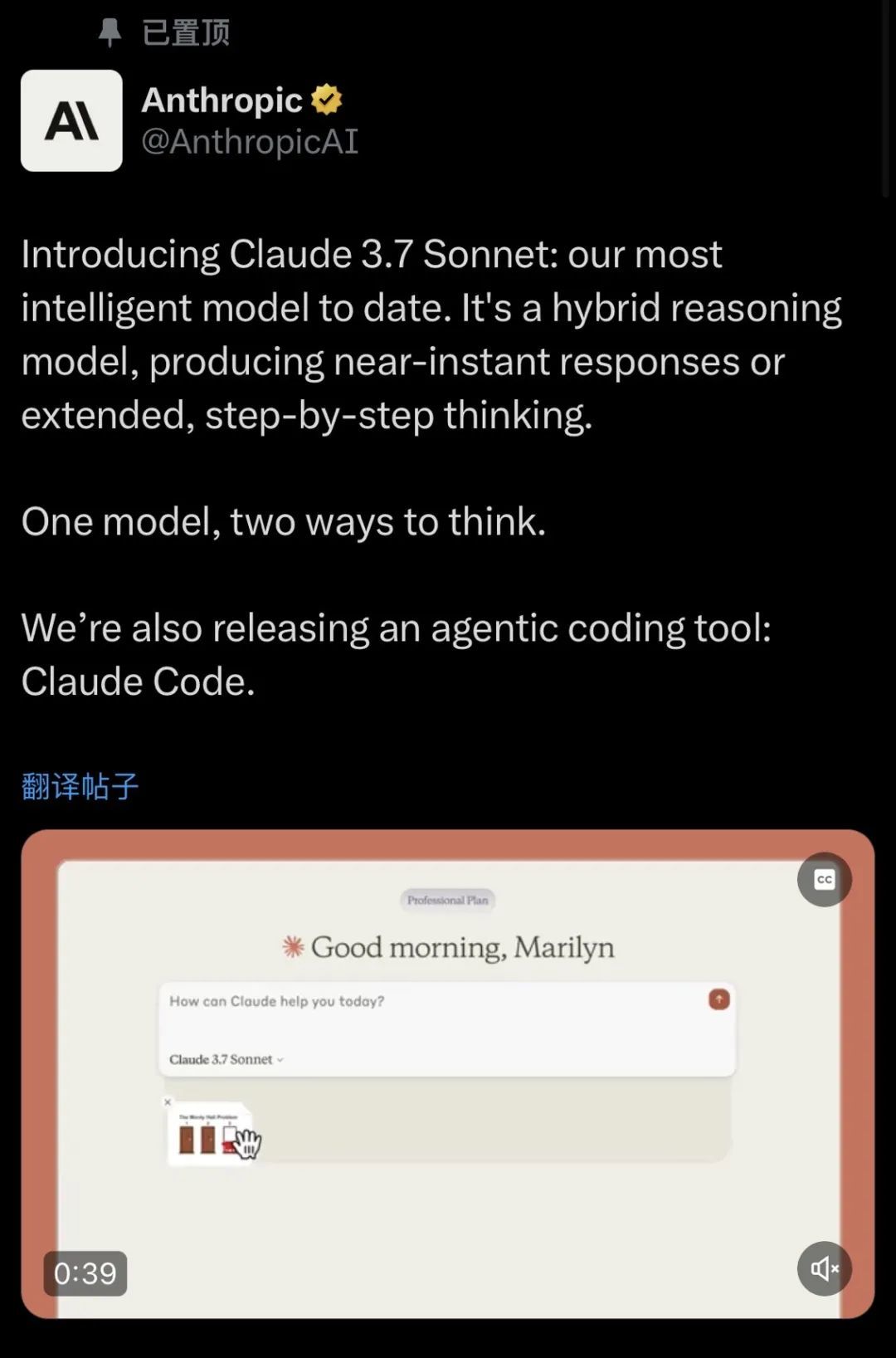
我估計今天那些專門做模型測評的博主,都快要忙不過來了吧。。。
再加上 Grok 3 、 DeepSeek R1 、 o3 mini ,世超猜到了今年推理模型必有一戰,但沒想到,來得這麼快。
先把視線,放在新一代 “ 開源戰神 ” DeepSeek 身上。
用 R1 教育了一遍市場之後, DeepSeek 這兩天,乾脆開源了個徹底, 5 天時間,每天發一個代碼庫。
第一天,整了個 FlashMLA ,這玩意兒專門針對英偉達的 Hoppers GPU ( 比如 H100 、 H800 ),進行了效率優化,通俗點說就是榨乾 GPU 的最後一滴性能。

今天開源的,則是 DeepEP 通信庫。
根據官方的介紹,這是一個專門爲專家混合( MoE )和專家並行( EP )設計的通信庫。太複雜的咱也不去深究,大白話就是通信庫可以讓 “ 專家們 ” 的交流更快速、高效。
不知道明天 DeepSeek 又會開源哪個代碼庫,但光憑他們這敞亮、真誠的態度,圈粉就是分分鐘的事兒,在 DeepSeek 的評論區底下,世超已經看到不只一位老哥,對着 OpenAI 貼臉開大了。
不過說到這,可能會有差友疑惑,網上整天嚷嚷着開源,這跟咱到底有啥關係?
這麼說吧, DeepSeek R1 開源以後,大大小小的私企、國企都吻了上來,還有高校甚至政府機關,不是已經接入 DeepSeek ,就是在接入的路上。
很難說,閉源模型在構建生態這一步,能不能在短時間內達到像 DeepSeek 這樣的效果。
所以這一切,我們可能都得感謝開源。

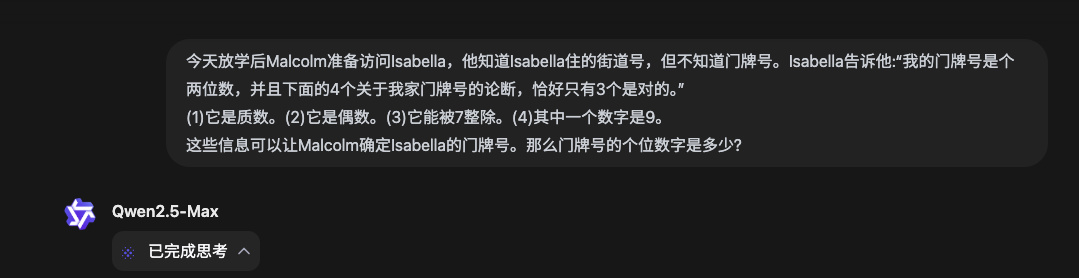
再來看阿里通義千問的 QwQ-Max-Preview ,是個推理模型。阿里也算是國內第一個,推出推理模型的頭部大廠。
根據官方的說法,這是一個基於 Qwen2.5-Max 的推理模型,有很強的數學理解、編碼能力,但目前還只是預覽版。

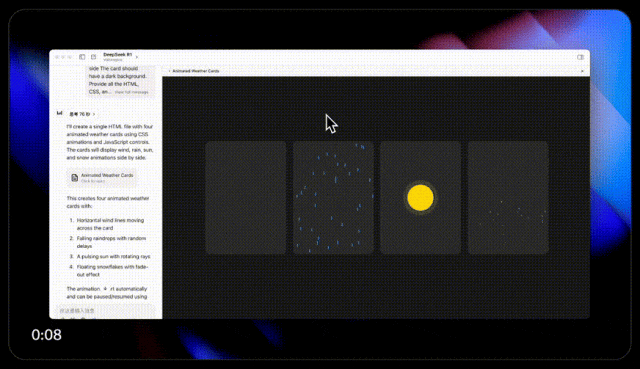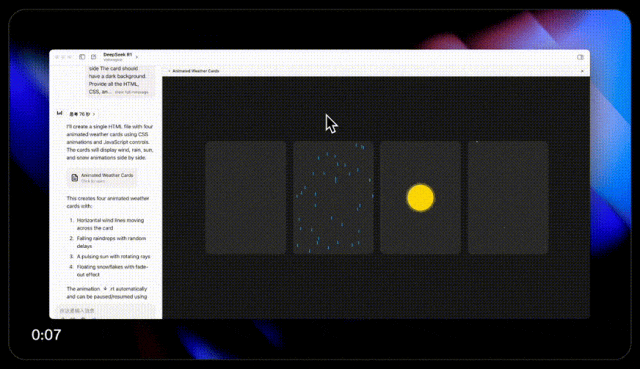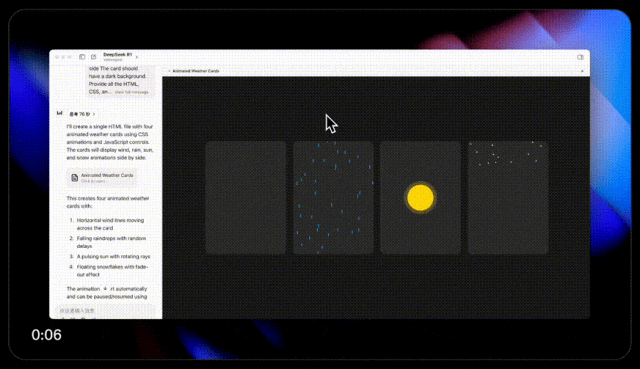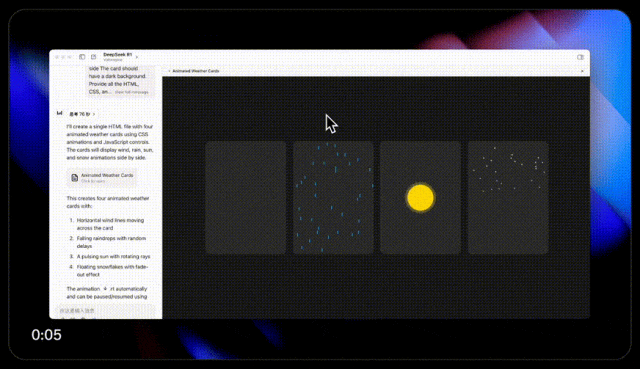
問它一道數學競賽真題,最後的答案倒是對了,就是思考時間稍微久了些,我粗略估計思考了得有兩分鐘出頭。
這道題問 DeepSeek R1 ,它的思考過程跟 QwQ 很相似,也是分析了多種可能性,但 R1 勝在推理的速度稍微快一些( 112 秒 )。
而同樣的題目,我又問了今天的另外一位主角 Claude 3.7 Sonnet 。
只能說,又快又準。

但值得注意的是, Claude 3.7 Sonnet 是個混合模型,一個模型有標準和擴展兩種模式。
如果你想看到大模型的推理步驟、思考過程,那就得選擴展模式。
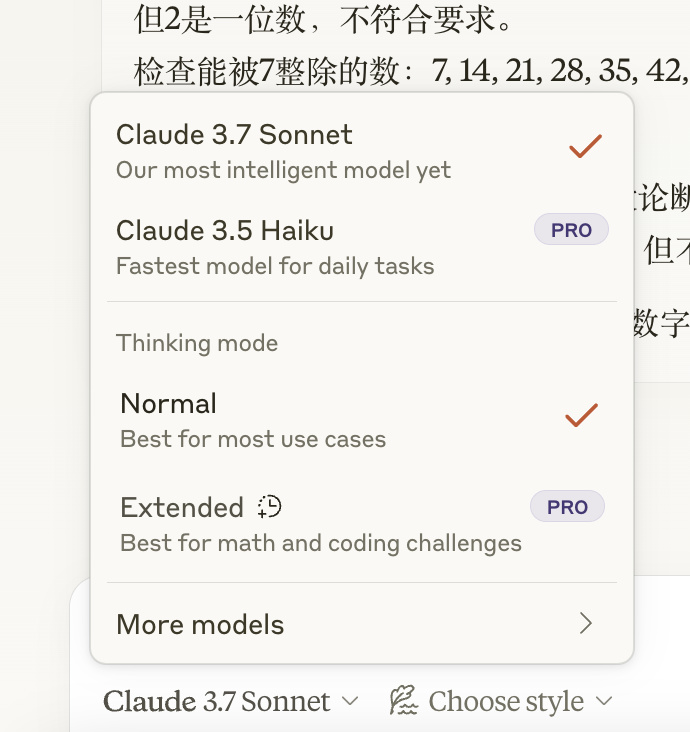
如大夥兒所見,體驗 Claude 3.7 Sonnet 的推理能力,是另外的價格。
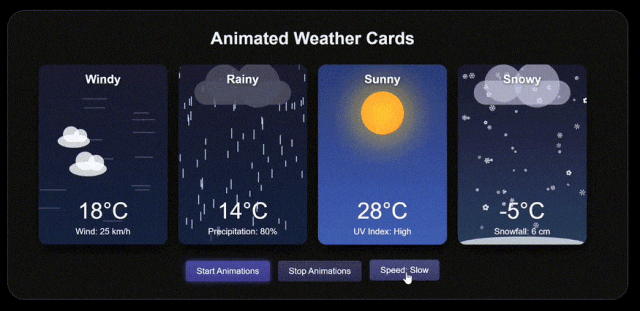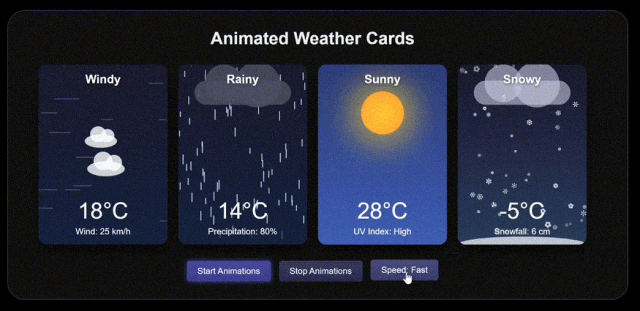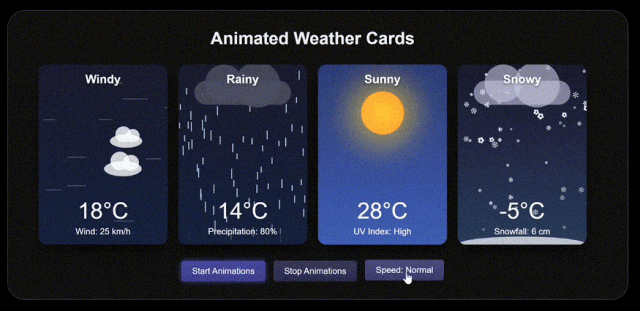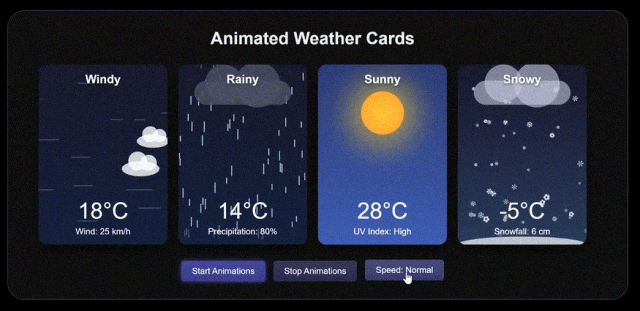
世超還找了幾個外網的實測案例,發現 Claude 的代碼能力依然強得可怕。
同一組提示詞餵給 Claude 3.7 Sonnet 和 Grok 3 ,這是 Claude 3.7 Sonnet 的結果。
再來看 Grok 3 的,直接被碾壓。
即使 DeepSeek 加入戰鬥,也被秒了。。。
反正看下來, AI 發展到今天,已經有點超乎世超的想象了。
雖說今天這三則新聞放一起,打眼一看,好像沒啥特別大的關聯。
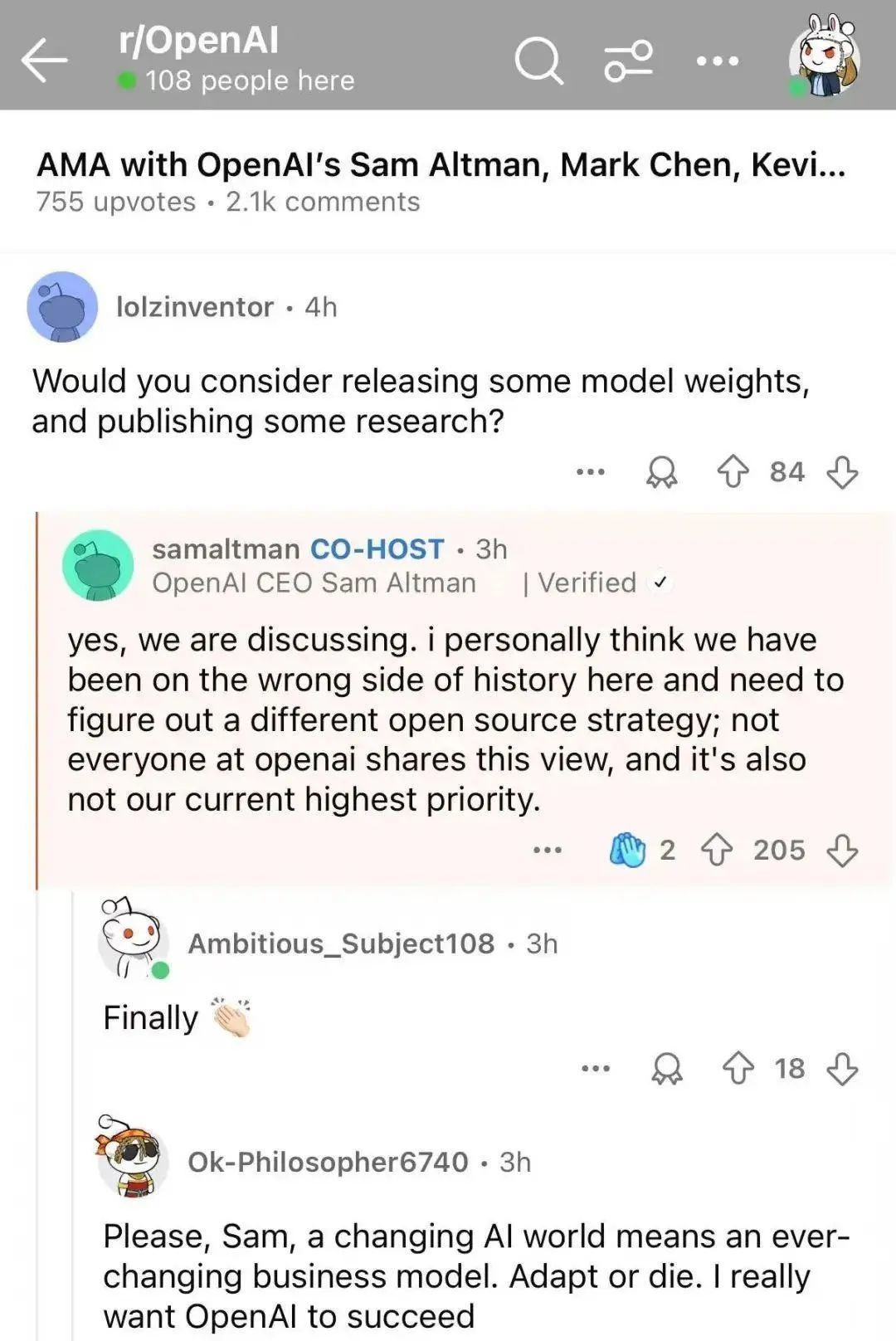
模型的開源和閉源之爭, DeepSeek 一出手,即便是奧特曼,也不得不親口承認, OpenAI 的閉源策略 “ 站在了歷史錯誤的一邊 ” 。
像 Llama 家族這種具有里程碑意義的模型,對於開源社區的重要性無需多言。
而除了 DeepSeek 和 Meta ,阿里通義千問、 xAI ,還有陸續擁抱開源的百度、 Minimax 和階躍星辰,開源陣營肉眼可見在壯大。
另外一邊,前兩年大模型是不是老強調自己的長文本能力,慢慢的開始卷文生圖、文生視頻還有語音交互這些多模態,再到最近,模型跑分全是數學、代碼。
照這麼下去,可能哪天 OpenAI 宣佈開源,又或者誰家突然宣佈把 AGI 整出來了,我都不會覺得驚訝了。
撰文:西西
編輯:江江&面線
美編:煥妍
圖片、資料來源:
X、Claude、Qwen
部分圖源網絡

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















