NVIDIA 公布 Rubin GPU 规划,2026 年推出,2027 年迎来 Rubin Ultra,Feynman 架构也加入路线图

NVL144 与 NVL576 配置将陆续登场
在 GTC 2025 大会上,老黄公布了 NVIDIA 最新的 数据中心 GPU 发展路线图,正式确认 Rubin GPU 平台 将于 2026 年下半年 推出,而更强大的 Rubin Ultra 计划在 2027 年 登场。此外,Feynman 架构 也被纳入 NVIDIA 的长期规划。
Rubin GPU的性能翻倍,全面升级存储与互联架构
尽管 NVIDIA Blackwell B200 刚刚全面量产,而 Blackwell B300 预计在 2025 年下半年上市,但 NVIDIA 已经开始布局未来几年服务器级 GPU 生态的演进方向。

在介绍 Rubin 之前,老黄特意指出:“Blackwell 其实命名有误。” 他解释称,Blackwell B200 实际上是 双核心设计,这导致 NVLink 互联架构发生变化。因此,尽管 B200 被称为 NVL72,但实际上更准确的叫法应该是 NV144L,而未来的 Rubin 方案将会沿用这一命名方式。
Rubin NVL144:FP4 算力提升至 3.6 PFLOPS,FP8 训练性能大增
Rubin GPU 的首发产品 NVL144 将 完全兼容现有的 Blackwell NVL72 服务器架构,但算力表现大幅提升:FP4 精度计算性能:3.6 PFLOPS(B300 NVL72 为 1.1 PFLOPS),FP8 训练算力:1.2 ExaFLOPS(B300 NVL72 仅为 0.36 ExaFLOPS),计算性能整体提升 3.3 倍。
Rubin 还将从现有的 HBM3 / HBM3e 内存升级至 HBM4,而 Rubin Ultra 则会采用 HBM4e,进一步提高带宽。每颗 GPU 的显存仍为 288GB,但内存带宽从 8 TB/s 提升至 13 TB/s。
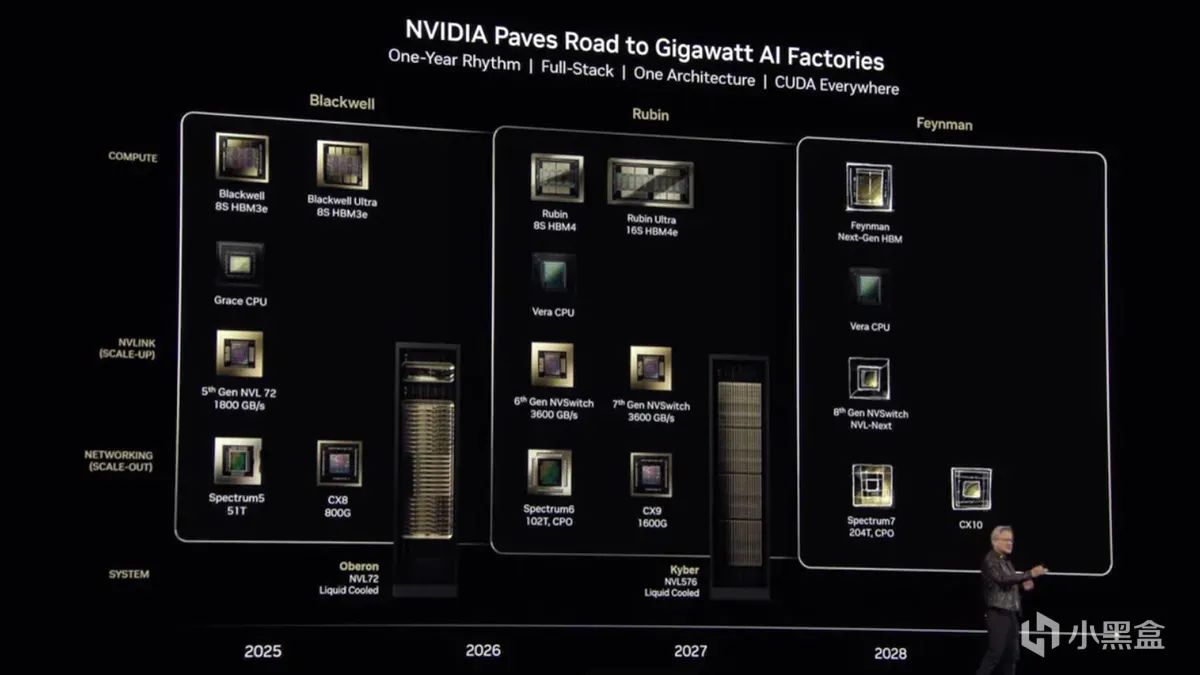
在互联方面,NVLink 速率翻倍,总带宽达到 260 TB/s,新一代 CX9 互联 允许机架间数据交换速率提升至 28.8 TB/s(是 B300 CX8 的两倍)
Rubin Ultra,算力飙升 4 倍,最高支持 576 颗 GPU 并行计算
2027 年 Rubin Ultra 上市后,数据中心架构将迎来又一次飞跃。尽管 Rubin Ultra 仍会搭配 Vera CPU(替代当前的 Grace CPU),但 GPU 性能将迎来质变。NVL576 架构,每个机架支持 576 颗 GPU,FP4 精度推理计算:提升至 15 ExaFLOPS(Rubin NVL144 为 3.6 ExaFLOPS),FP8 训练计算:提升至 5 ExaFLOPS。
Rubin Ultra 采用四核心 GPU 封装,大幅提高计算密度,每个机架提供 365TB 高速内存(相比 Rubin NVL144 的 75TB)。但是,Rubin Ultra 在 HBM4e 内存带宽上的数据有所疑点,整体带宽 4.6 PB/s,576 颗 GPU 平均下来仅 8 TB/s / GPU,相比 Rubin NVL144 的 13 TB/s / GPU 似乎有所下降,这可能与 四核心封装 GPU 内部的互联方式 相关,但目前 NVIDIA 尚未详细解释这一点。
在互联架构方面,NVLink7 互联速率提升 6 倍,总吞吐量 1.5 PB/s,CX9 机架间互联速率提升 4 倍,达 115.2 TB/s

Rubin 之后,Feynman 架构登场,推向“千亿瓦级 AI 数据中心”
除了 Rubin 及 Rubin Ultra,NVIDIA 还在 GTC 2025 上首次提及了 Feynman 架构。按照 NVIDIA 目前的命名习惯,未来可能会推出 Richard CPU 搭配 Feynman GPU,为超大规模 AI 计算提供更强算力支持。
从 NVIDIA 的路线图来看,未来几年,数据中心 GPU 将继续朝着 更高算力、更快互联、更大带宽 的方向发展,为 AI 训练、科学计算和企业级推理任务提供前所未有的性能支持。Rubin 只是 NVIDIA AI 计算生态的下一个阶段,而 Feynman 可能会真正推动行业迈向“千亿瓦级 AI 数据中心”时代。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com

















