請注意,這篇“短文”可能略微有點長,並且涉及到一些計算機相關的知識,其中的一部分可能會有一些晦澀,但是他們並不影響後續的操作。
如果你想手操進行模型的訓練請至少保證你有一張顯存大於6G的Nvidia顯卡,當然就算你沒有你也可以看着玩一玩XD
你將會在文中看到:筆者超高濃度私貨音聲合成技術史,寫的一團亂麻但是實際上手卻異常簡單的訓練過程,以及超級飛天咕咕鴿
前言
AI,AI,AI
2023年還沒過半,但是估計各位都已經早早的感受到了時代又在變換。
從22年年中開始,各類AI有如疾風驟雨突然出現打破了本來頗有點平靜的網絡。
你就當他大概算是......平靜吧。
就算你沒有聽說過標題裏的so-vits-svc,你大概也肯定聽說過什麼AI冬雪蓮,AI孫笑川。

雖然別的ai可能在擠壓創作者的生存空間,但是svc肯定是狠狠的拓寬了一下各位逆天們的創作上限,草
嘛,相比起ChatGPT,novelai,DALEE給其他行業帶來的震撼,svs技術的發展顯然更直接的給各位帶來了全新的高純度樂子。
當然,有些人用來整活給大家帶了快樂,也有人用ai去復刻了那些再也無法歌唱的聲音。
何嘗不是一種再見,儘管永遠只能是遠遠的再眺望一眼
雖然也有人拿rvc模型實時變聲加上之前就有的實時換臉拿來搞電信詐騙,只能說人啊真是無可救藥。
雖然AI的高速發展引發了諸多的爭議,但是其實最終真正決定ai會做什麼能做什麼的,還是去使用ai的人。
當然,這有點跑題了,今天的這篇短文的主要目標當然是————
讓各位也可以自己使用So-VITS-svc煉出想要的聲音
不過在我們動手之前還是有很多需要了解的東西的,那麼照例還是先要來一段簡單的介紹。
介紹
什麼是svs?
如你所見,So-VITS-svc(下文簡稱sovits)是一種SVS(singing voice synthesis)即音聲合成技術。
所以在正式開始sovits的介紹之前,我們也應該對svs的發展有一點基礎的瞭解。
如果你曾經關注過VOCALOID/UTAU之類的程序,那你應該對什麼是svs已經有了初步的瞭解,也就是通過拼接/合成等方法來實現從文字向聲音的轉變。
對於最先出現的一類SVS技術,也就是以VOCALOID和UTAU爲代表的採樣拼接式合成,它們的原理是通過以一定的模式去拼接預先錄製的採樣並對其進行音高和音素的拉伸變換來實現合成所需的歌聲。

初音未來所基於的VOCALOID軟件,就是由日本的雅馬哈公司研發的一種SVS技術
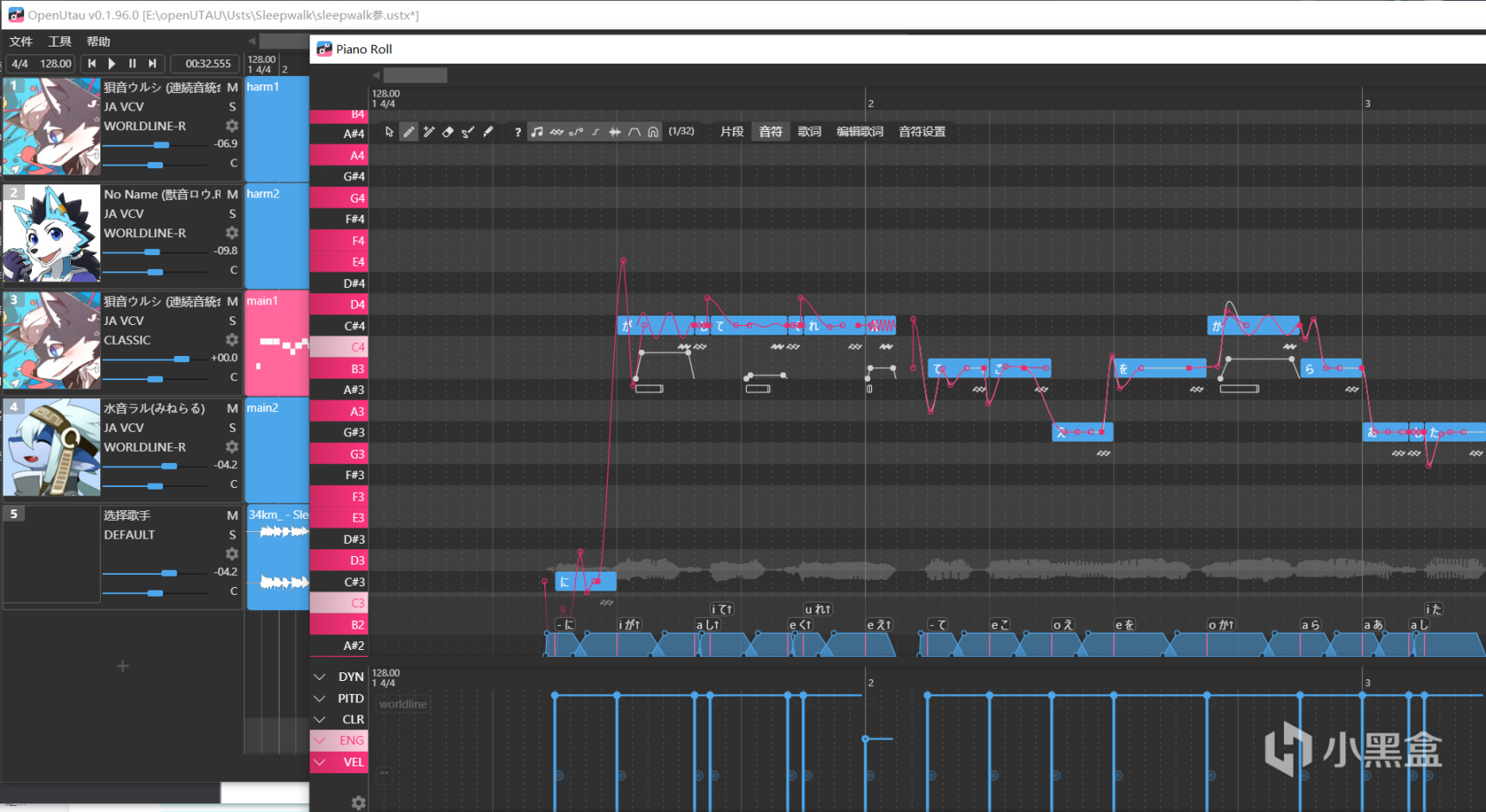
UTAU則是後來由日本的飴屋氏製作的歌聲合成軟件,可以通過用戶自己錄製採樣來製作聲庫,也是一類基於拼接的SVS技術
而在2018年年中,SynthesizerV橫空出世,正式帶領SVS技術進入了通過神經網絡模型(LLSM)和拼接採樣混合來合成歌聲的時代。
值得一提的是,其實最先出現的llsm+拼接採樣混合的合成引擎是CeVIO,有關注這塊的可能聽說過其早期的神音源 佐藤莎莎拉。但是CeVIO早期實在是缺乏人氣,更多被作爲一個語音合成軟件來使用,加上沒有和現有的VOCALOID、UTAU創作生態融合,直接導致了很長一段時間的查無此人。
不過在後來CeVIO也推出了完全基於llsm的CeVIO AI,加上紅極一時的音源可不,成功和SynthesizerV AI一起笑到最後成爲了本世代的贏家,並且把VOCALOID5和6徹底擠到了角落去自娛自樂。
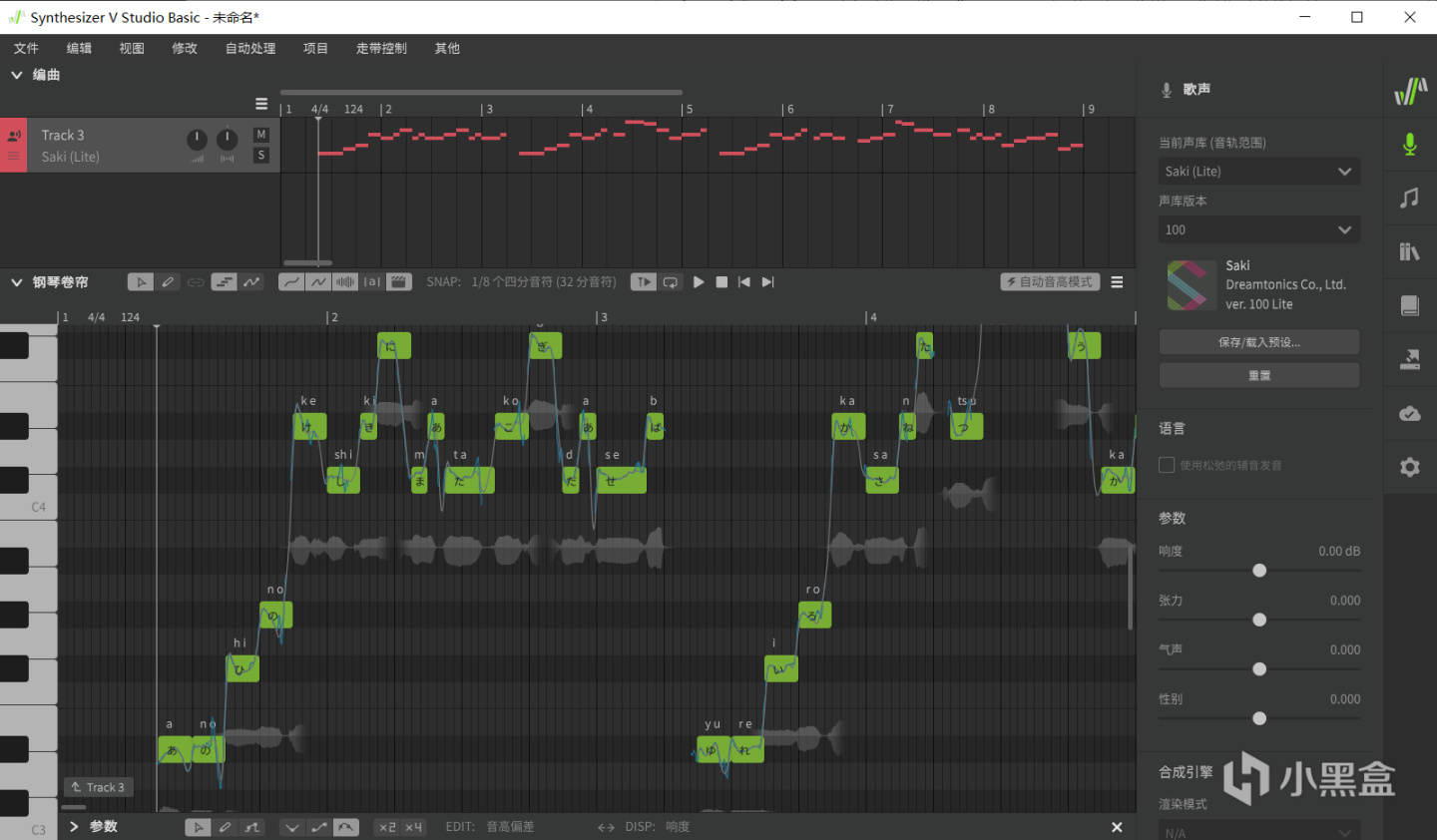
SynthV並沒有官方表示過他們具體使用的模型種類,所以就籠統的以llsm帶過了,不過值得一提的是,sv的主要開發者 華侃如 正是當年阿b上Rocaloid(讓初音未來唱出中文)項目以及UTAU上極出名的Moresamplers重採樣器的作者,真正的技術大神。
相對於sv本體的混合式合成引擎,後來發佈的Synthesizer V AI則是完全轉向了llsm技術的懷抱,而這也就來到了我們今天的主題。
什麼是So-VITS-svc?
可能極度晦澀注意
Synthesizer V AI和CeVIO AI的火熱也讓llsm技術走進了社區的視野,在全新的技術下,合成的人聲擁有了前所未有的流暢感,無限接近真人的歌聲,但是這對於社區來講卻是一個頭疼的問題。爲什麼?
因爲以上的所有都是商業產品,你只能購買其他公司製作好的音源,更不能用自己的聲音來製作一個獨特的聲庫,而此時社區的聲庫自制卻還停留在以UTAU和VocalSharp爲代表的拼接類採樣引擎以及DeepVocal這樣的弱神經網絡+採樣拼接合成引擎,它們已經逐漸無力滿足大家被AI養刁了的耳朵。
於是,隨着擴散模型、對抗網絡模型和聲碼器相關的技術的成熟,社區中逐漸也開始誕生了全新的svs項目,這其中便包括了sovits。
So-VITS-svc是一種svc模型,即singing voice convertion,歌聲轉換。
svc是svs中的一個分支,主要通過輸入音頻中的音高和音素來自動實現音色和唱法的轉換,而不是像傳統的svs一樣手動輸入音高和音素,但是這也表示svc模型需要一個原始音頻作爲轉換的來源,並且這個音頻應該是足夠乾淨的幹聲。
So-VITS-svc的全稱是SoftVC VITS Singing Voice Conversion,這個長長的全名也表示了這個模型的技術的來源。
簡單的解釋一下這個名字,就是基於Soft編碼的VITS聲音轉換模型。
很顯然,這個解釋並不好,一次又拋出了兩個新的概念,什麼都沒解釋出來。
再精細一點的解釋就是,通過Hubert的Soft編碼輸入來替換VITS中的ppg從而實現的聲學轉換模型,而VITS是一種基於對抗網絡訓練的聲音合成模型。
現在這個解釋變得更加難懂了,寫了又好像什麼都沒寫,這是因爲筆者也不是人工智能專業的,再繼續往深去就已經超越孩子的知識儲備了(
但是如果要省流一下,就是效果比傳統的VITS模型更好的聲音轉換模型。
(笑哭)
算了,比起解釋他的原理,顯然還是直接上手操作更有效果(
君のSovits本當上手
這篇教程基於BV1H24y187Ko 作者 羽毛布団 的整合包製作,什麼,你問我爲什麼不從原倉庫下載和webUI搭建開始?
顯然,這裏不是酷安,而是小黑盒(
其實是因爲整合包內置了大部分所需的環境,操作起來更加簡單,也可以規避很多複雜的問題(尤其是大多數人基本都會翻車十幾次的環境配置部分)。
這篇教程僅僅包含單說話人模型的訓練!
當然,按照慣例,以下是So-VITS-svc項目的地址:
在你對這個項目有了足夠的瞭解之後,也可以試着去按照原本的項目來對你的訓練參數進行更改來獲得更好的效果。
以及在此之前,你應當注意:

來自整合包的作者,請務必遵守相關的開源許可
同時,你不應使用未得到授權的聲音素材進行訓練後公開發布模型,不應在得到具有法律效力的許可之前將聲音素材和訓練後的模型進行任何商業使用。
事先準備
- 一個時長至少高於十分鐘的素材集,在有可能的情況下總量最好超過1h。(如果素材集小於十分鐘甚至只有十幾秒也可以進行訓練,但是會明顯影響最後的成品質量)
- 你的電腦應擁有16G及以上的內存,如果僅有8G那麼請確保你的素材存放在足夠快的固態硬盤中,否則會極大影響訓練的速度並導致很多不該出現的error発生,如果連8G都沒有就還是先洗洗睡吧x。
- 你需要一張擁有6G以上顯存並且支持CUDA的Nvidia顯卡,合理的選擇如3060Ti,不過理論上1060 6G一樣可以跑。對於這類對抗網絡的訓練,顯卡的顯存需求大於算力的需求,更高的算力確實可以一定程度上提升訓練的速度,但是一個足夠大的顯存更爲關鍵,在可行的情況下,一張3080 12G及以上的顯卡會很好的提升你在訓練過程中的體驗。
- 除非你對你的內存性能及儲量有絕對自信,否則你還是應該準備一塊存的下你的所有數據的固態硬盤,當然如果內存夠大可以直接寫入內存那麼機械硬盤也是可以的。
下載訓練工具
解壓至任意文件夾,請注意文件路徑內不要出現漢字或全角符號等。
數據集
顯然,在你訓練出對應的聲音之前,你應該準備一些採樣來準備製作數據集。
採樣應該是:
- 完全純淨的幹聲,你可以通過uvr來獲得幹聲,但是這會很大程度的影響成品的效果,除非你對你提取之後幹聲的純淨度有足夠的自信
- 採樣應該來自同一個人並且音色保持相似
- 採樣的命名中請不要包含日語,漢字等非unicode字符
這些採樣應該被放在同一個文件夾下,就像這樣:
原本這些採樣其實是最好應該被切成10s以內的短採樣的,不過現在這個功能Web面板自帶了,直接把完整採樣放進來也是沒問題的。
然後將準備好的數據集文件夾放進sovits整合包中的dataset_raw中。
文件夾裏面就是訓練用的素材
這樣就完成了數據集的準備,可以開始訓練了!
啓動面板/處理數據
回到整合包文件夾裏,雙擊啓動WebUI.bat
然後應該會蹦出來一個命令行:
等一段時間之後這裏的文字會發生變化,然後會自動爲你打開瀏覽器,如果瀏覽器沒有自動打開的話,也可以直接訪問http://127.0.0.1:7860。
然後,進入瀏覽器,就可以看到這個非常簡明的WebUI了!
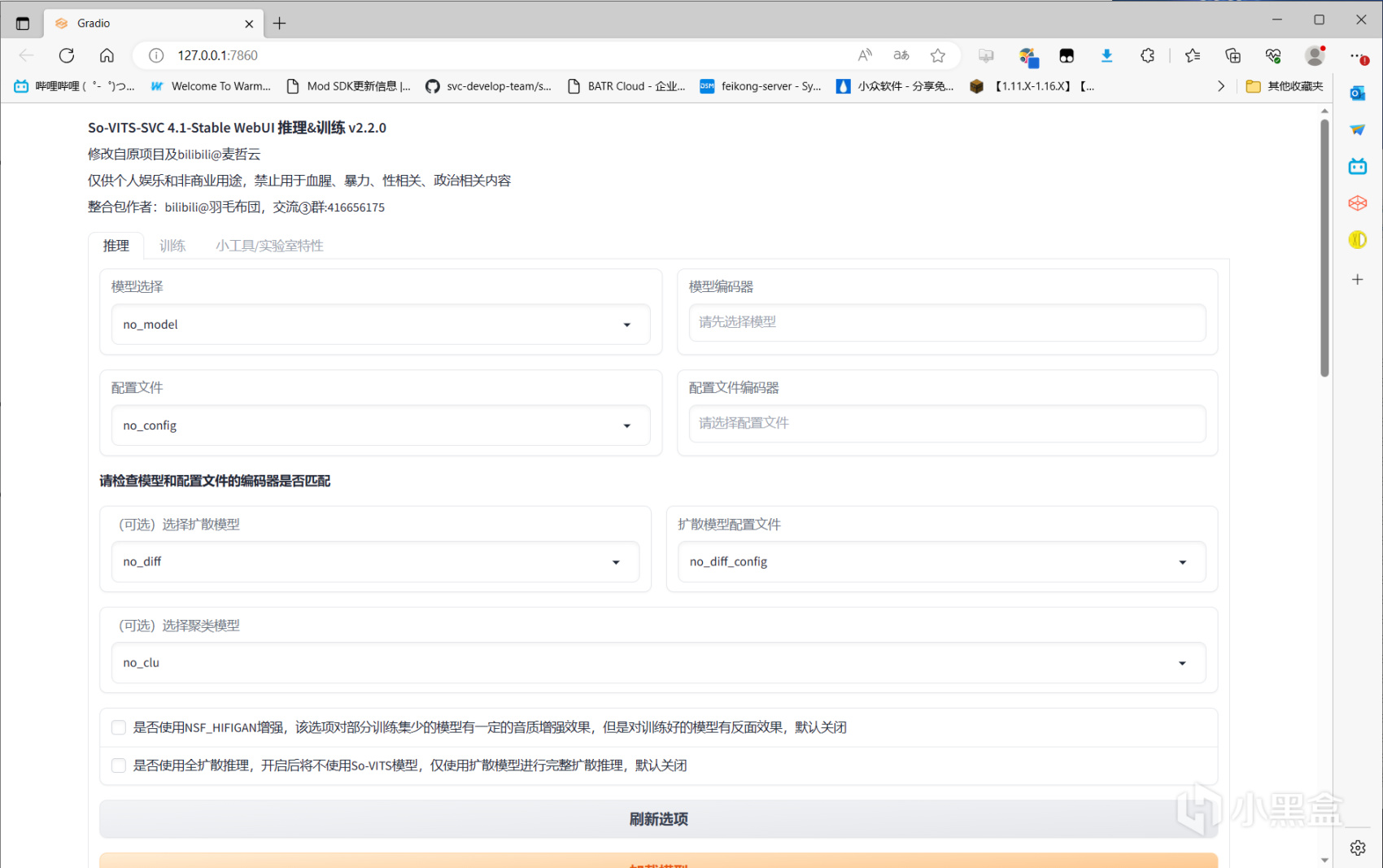
我們現在還沒有模型可以用來推理,所以推理這部分我們晚一點再介紹。
直接選擇選項卡里的訓練就可以了......等等!
很顯然,在這之前我們應該先處理一下音頻,所以讓我們首先點進小工具/實驗室特性,然後選擇智能音頻切片。
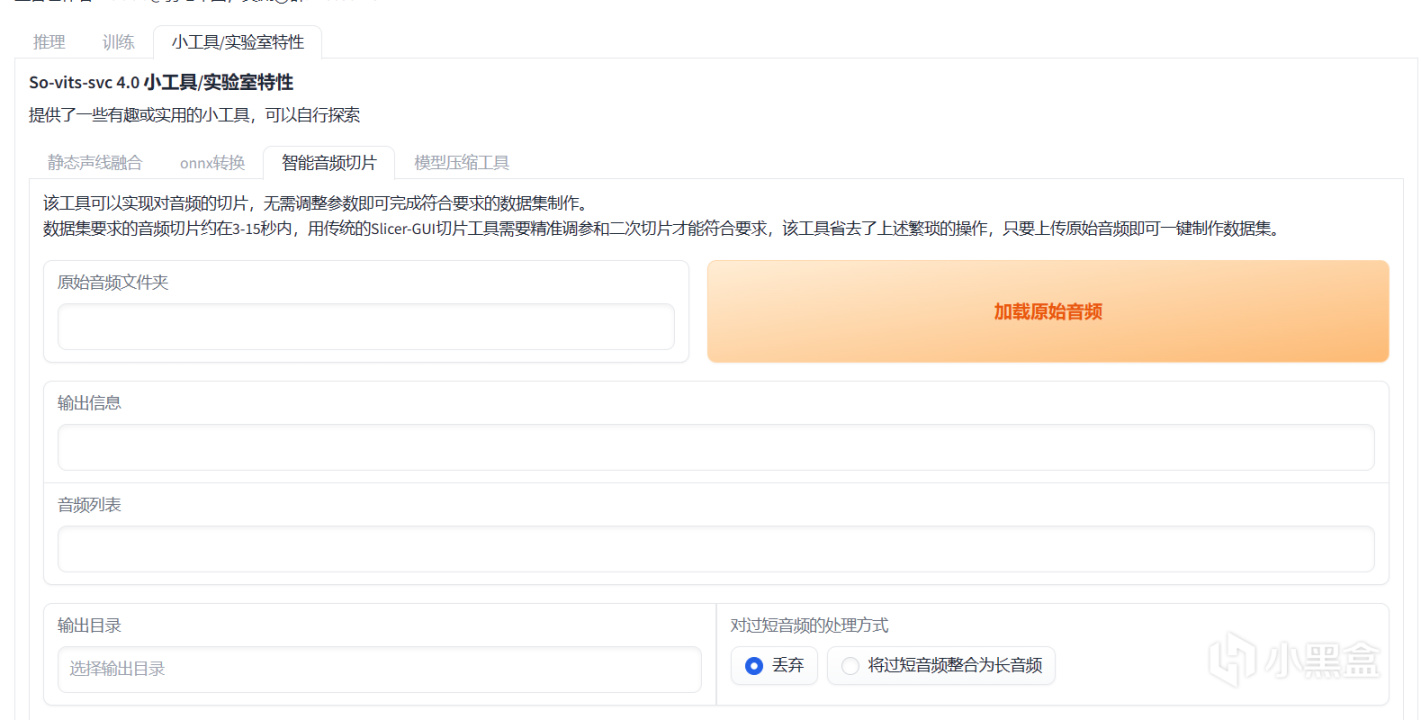
現在要將音頻目錄輸入在原始音頻文件夾的輸入框中,一般是./dataset_raw/xxxxxx(你的數據集文件夾的名字),然後點擊加載原始音頻。
這裏是使用了相對目錄,你也可以使用絕對目錄,例如E:\sovits\dataset_raw\xxxxxx
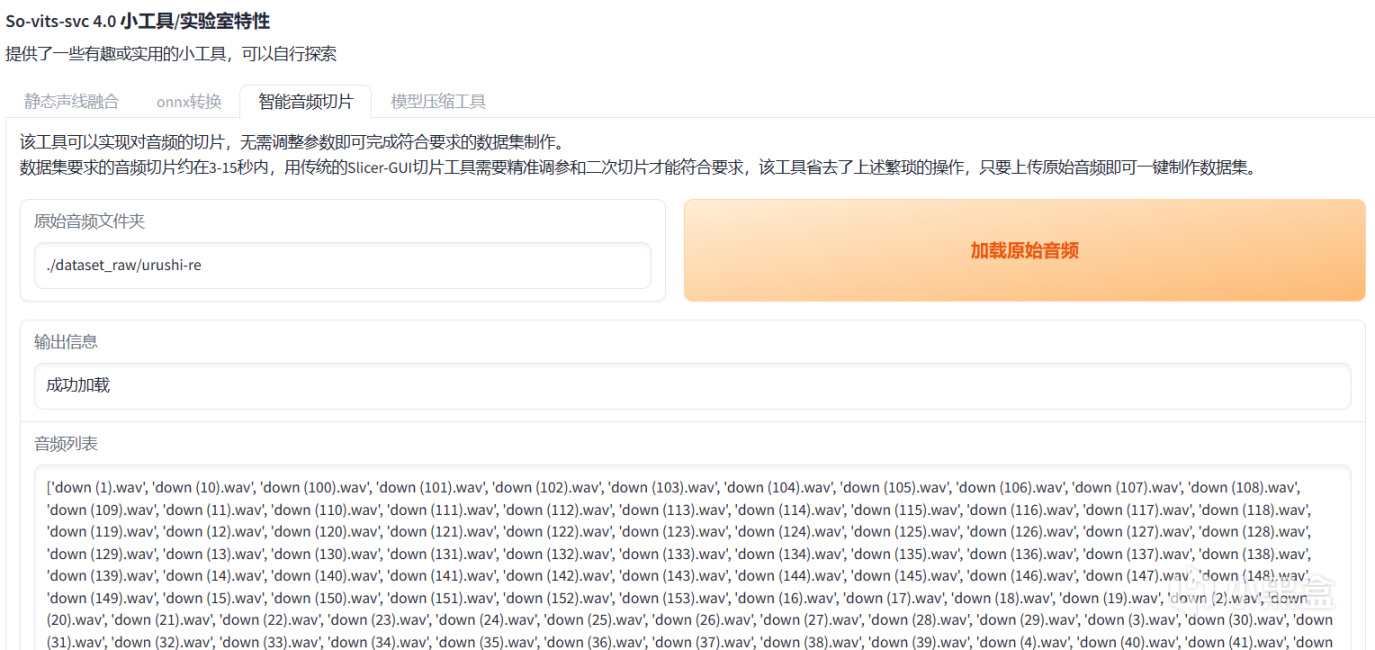
能看到下面輸出了你的音源文件就說明加載完成了
將網頁拖到下面,設置輸出的目錄,比如./dataset_raw/xxxxxx_sliced,音頻處理方式建議選擇丟棄。
如果你和我一樣輸出的文件也在dataset_raw中,請記得把原來沒處理過的數據集刪除掉!不然會炸顯存!

具體怎麼命名就看各位怎麼想了x
然後點擊開始切片,就可以開始處理了!

切片處理需要一段時間的,如果你放進去的數據比較多,那麼可能要處理幾分鐘,所以稍安勿躁啦
提示成功即可
訓練前的配置
現在我們可以換到訓練選項卡了。
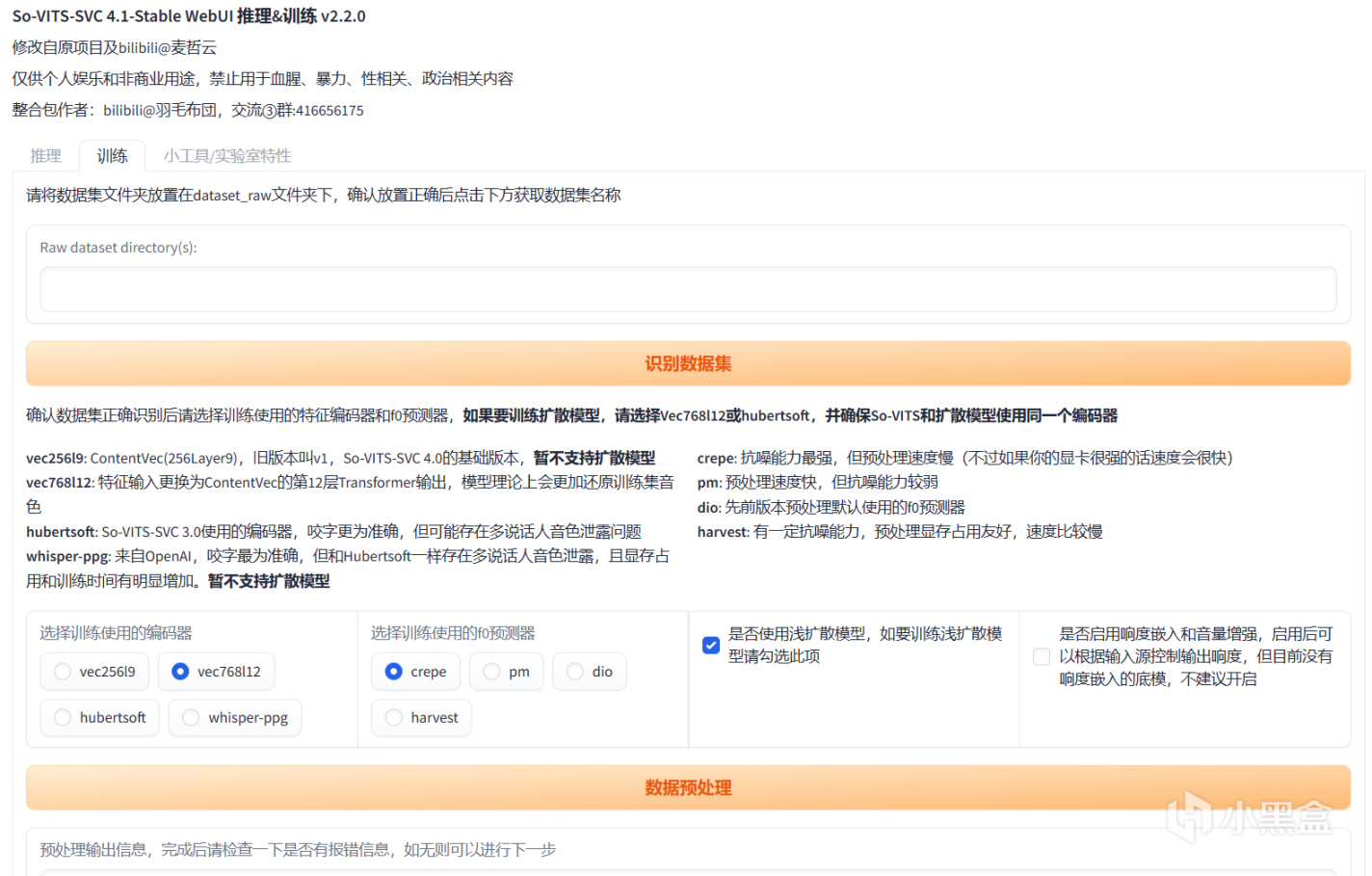
首先點擊識別數據集,它會自動識別你之前放進去處理好的數據集。
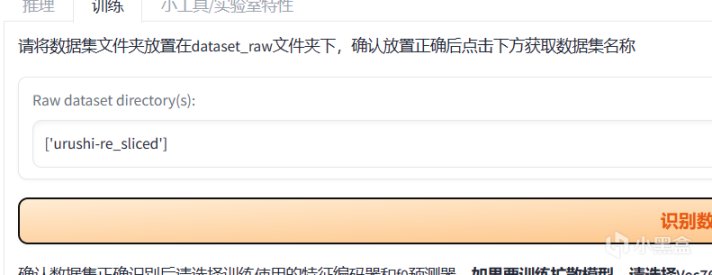
然後是編碼器的選擇。
個人推薦vec768l12,比較均衡,不過各位既然使用的都是單說話人模型,那麼咬字清晰的whisper-ppg也是不錯的。
擴散模型的訓練就不細講了,建議如果第一次上手不要考慮淺擴散(diff)模型,等到你操作稍微熟練之後這些東西是啥你自然會明白。
當然如果你很好奇這裏的擴散模型是什麼,可以百度diff-svc
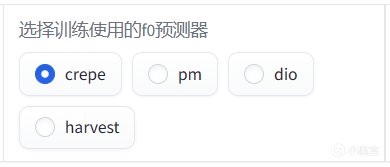
F0預測器的選擇上,看各位顯卡性能定,比如你有一張3080 10G及以上的顯卡,那麼crepe就是比較合適的選擇,如果顯卡性能不佳尤其是顯存偏少(6G左右)比較建議選擇Harvest。
So,你可能會想問什麼是f0預測,簡單來講f0預測是對輸入的聲音進行處理來分析其中的音素及持續時間並生成一個元數據,在訓練過程和推理過程中都會用到這個功能

兩項都不要開啓,除非你已經知道它們是用來幹什麼的。
完成以上的設置之後,就可以開始數據預處理了!
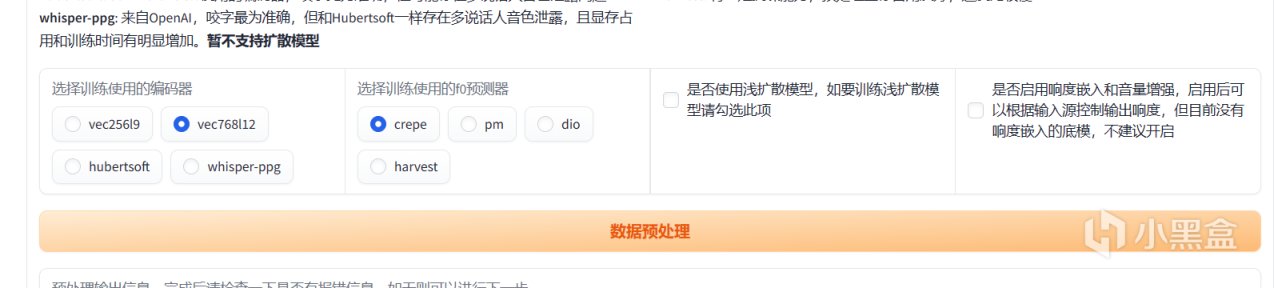
就這個好大好大的按鈕
預處理過程會消耗一點時間(不止一點),可以去找包零食刷刷視頻。
等下面的輸出信息裏的進度條到100%並且沒報錯就說明處理完了(或者什麼時候你滑滾輪能直接滑下去了)
什麼,你說你報錯了?那肯定是你前面的哪裏做錯了,快回去再看一遍處理過程!
想成爲看爐童子,你必須學會的技能就是......摸魚。
因爲這些數據處理和訓練真的非常消耗時間。
當然也真的很需要耐心,因爲如果你運氣不好的話,你照着這個文檔做可能要來來回回翻上翻下幾十次,不要覺得奇怪,煉丹就是這樣的,每天都在排錯。
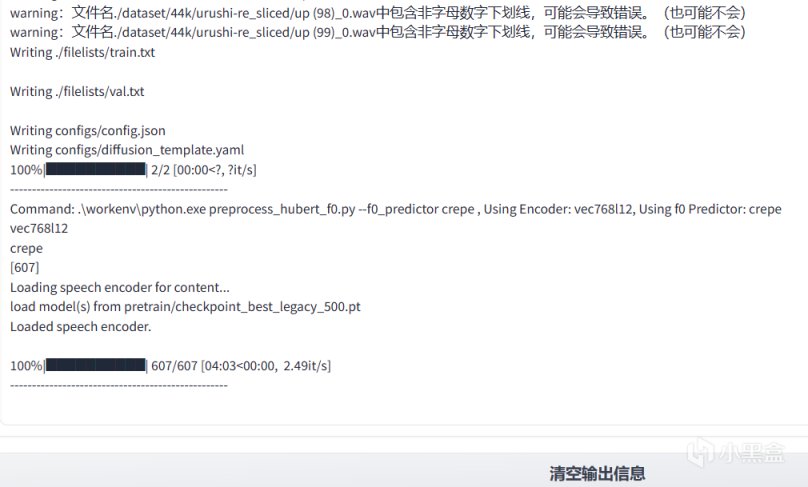
這個100%出來之後就堂堂結束咯!
然後是要填寫訓練設置和超參數。
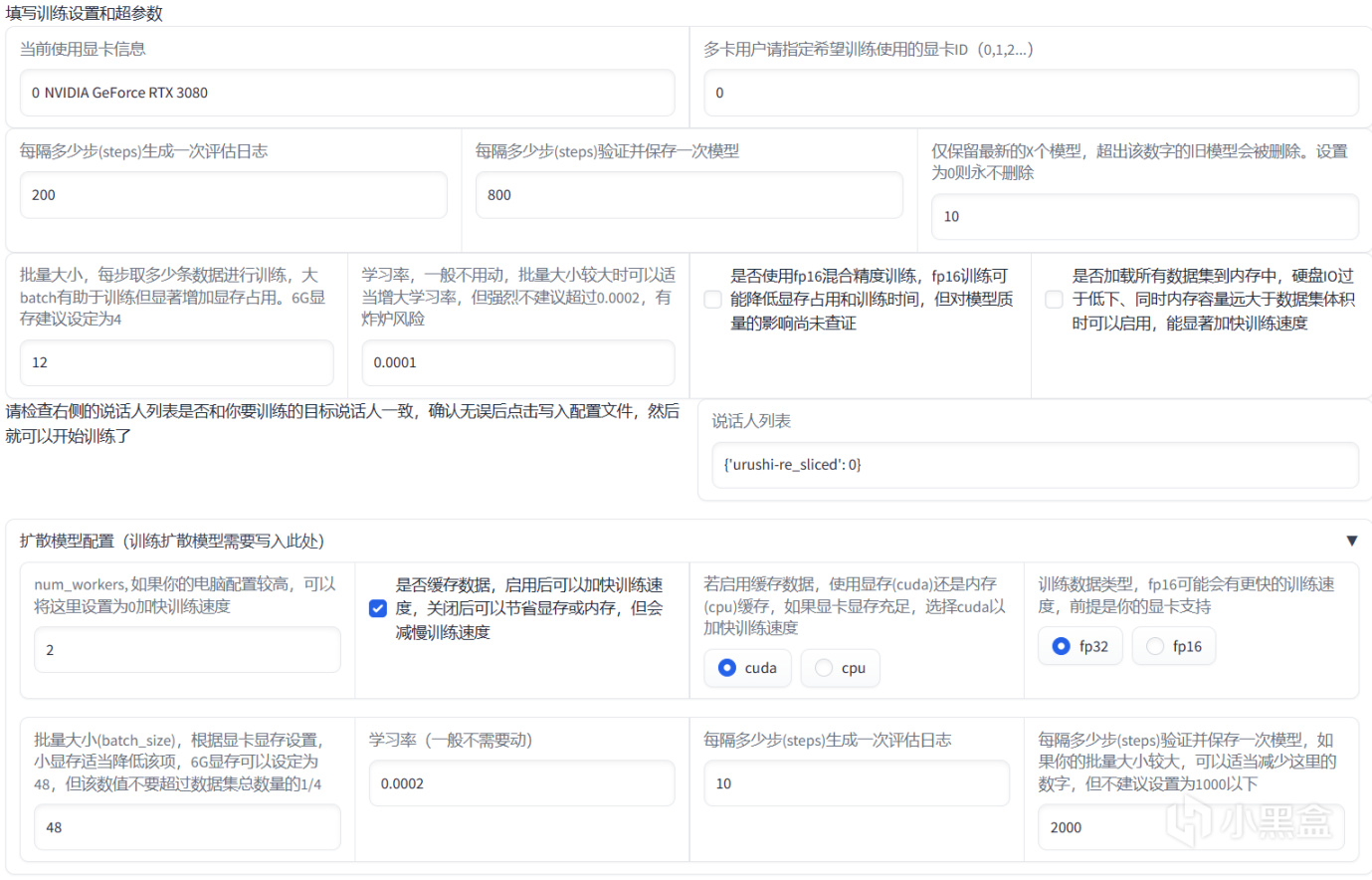
下面的擴散模型部分我們暫時不需要管

首先是顯卡信息,這個各位如果用筆記本的話要注意一下,別把核顯和獨顯搞混了,一般來講這裏都會自動識別一張能CUDA的n卡,以及如果你要多卡訓練要記得sli,否則只能單卡。
下面的生成評估日誌是指後臺輸出一次模型的相關數據的頻率,兩百步就是每迭代兩百次就輸出一次相關數據,這個對性能影響不大,你喜歡看爐子的話可以設置的小一點,比如200,個人一般設置到800。
每隔多少步驗證並保存一次模型是一個關鍵設置,默認設置了800即每迭代800次會保存一個模型在本地,在條件允許的情況下建議這個值可以適當設小(太小會影響訓練速度,500到800左右就挺合適的)。
保存的頻繁可以保證模型的安全,比如我在訓練到第96500步的時候模型發生了過擬合導致音色丟失,那麼設置了800步的情況下你就可以保存到96000步的模型,而設置了400步的時候就能保存到96400步的模型,而如果設置了1800步就只能保存到95400步的模型,但是這也意味着你需要付出更多的時間來看爐子,或者保存大量的模型並且浪費巨量存儲空間。
右邊則是保留模型數量的設置,比如你設置了10就會保留最新訓練的10個模型。
假設我保存步數設置爲800,保存模型數設置爲5,那麼訓練到16000步時就會保存步數爲16000、15200、14400、13600、12800的這五個模型。

然後就是下面這組
批量大小也就是Batch Size,可以說是決定訓練速度的選項,batch size越大每輪訓練就越快,不過這個選項要看你的顯存來定,一般6G設置到4,10G設置到6,16G設置到10.
學習率不用動,bs大於10可以設置到0.0002,嚴重玄學炸爐參數(孩子第一次炸爐就是bs設置6學習率設置了0.0002,第二天過來看爐子完全沒法聽(悲
半精度(fp16)訓練,這個用不用看你顯存,如果低於8g那還是用吧,但是對音質有沒有影響實在是有點玄學
加載所有數據到內存,這個選項建議你內存大於等於32G的時候可以用,尤其是你的硬盤速度並不理想(比如筆者用的東芝的企業級機械)的時候可以有效提升煉丹體驗。
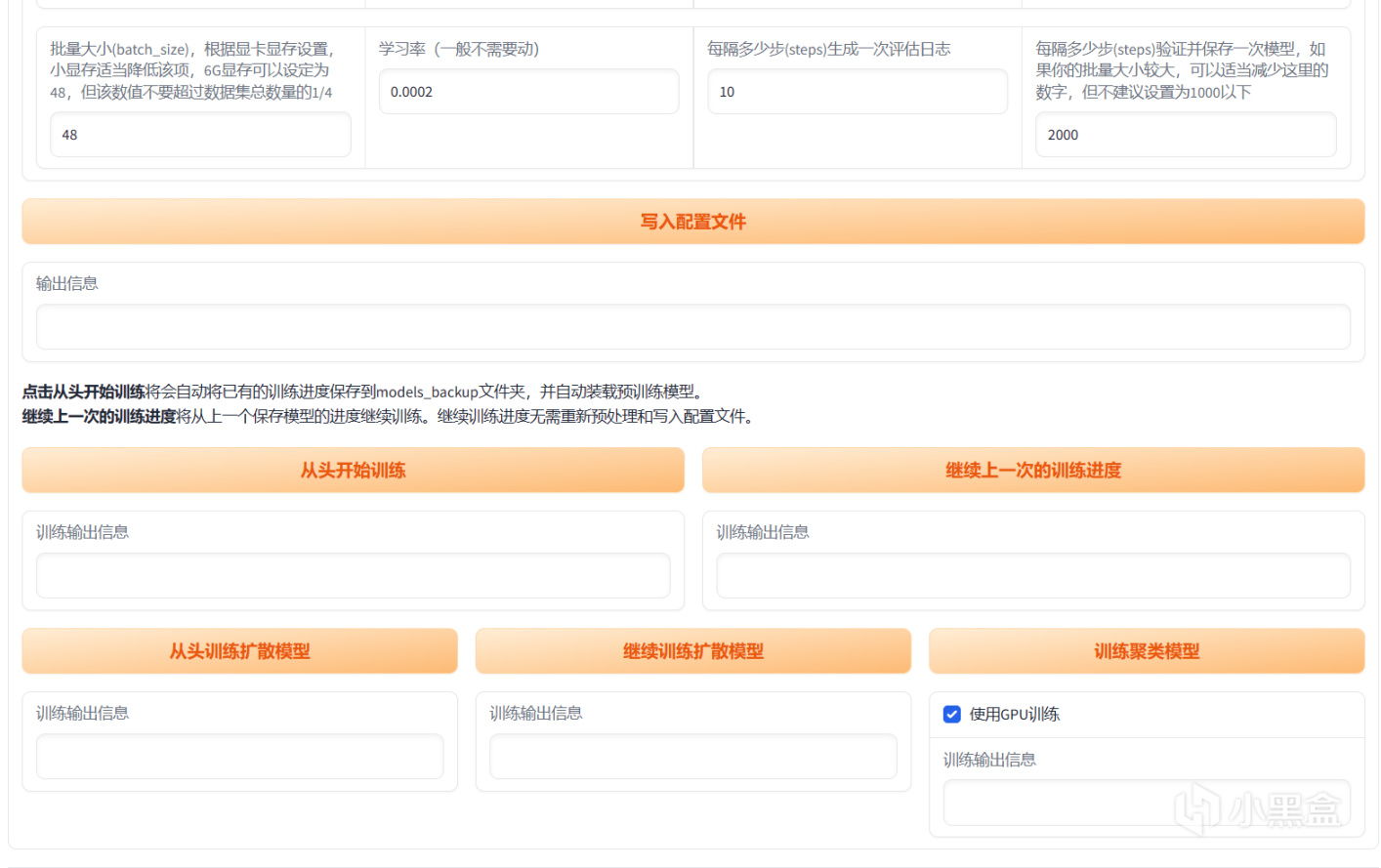
設置完這些之後,就是要寫入配置文件,然後點擊下面的從頭開始訓練啦!
煉他奶奶的
煉丹的過程會非常枯燥,你需要盯着後臺看他不停的迭代(當然你也可以關了電腦屏幕然後回去睡一覺,但是會不會這會炸爐我不保證)
作爲示例的話,筆者的Urushi AI煉了6個多小時才100000步(96000之後就過擬合了,結果最後最好用的還是89600步的)
作爲合格的看爐童子,摸魚是很好的習慣,然而你的顯卡在高負荷工作你的電腦這會大概率看個視頻都卡。
你知道嗎,整合包文件夾裏還有一個 啓動Tensorboard.bat
這個面板可以方便你監視模型訓練過程中的參數,尤其是Loss的擬合程度,有的時候可能你沒盯着面板一小會loss曲線就過了,加油啊煉丹的大哥哥
尾聲
什麼你問怎麼這就結尾了?
你不會覺得你開始煉丹之後還能這麼等着看下一部分吧(
所以關於推理和多說話人的部分......當然還是下一期了!
希望各位都能煉出自己滿意的聲音噢~
往期 黑盒學Tech :
Markdown:如何成爲Web時代最熱門的文檔標記語言|黑盒學Tech#1
往期 開源項目推薦:
優雅的Markdown寫作工具Marktext | Bot空的開源項目推薦#5
QtScrcpy:高質量投屏何須花錢 | Bot空的開源項目推薦#4
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















