NVIDIA 公佈 Rubin GPU 規劃,2026 年推出,2027 年迎來 Rubin Ultra,Feynman 架構也加入路線圖

NVL144 與 NVL576 配置將陸續登場
在 GTC 2025 大會上,老黃公佈了 NVIDIA 最新的 數據中心 GPU 發展路線圖,正式確認 Rubin GPU 平臺 將於 2026 年下半年 推出,而更強大的 Rubin Ultra 計劃在 2027 年 登場。此外,Feynman 架構 也被納入 NVIDIA 的長期規劃。
Rubin GPU的性能翻倍,全面升級存儲與互聯架構
儘管 NVIDIA Blackwell B200 剛剛全面量產,而 Blackwell B300 預計在 2025 年下半年上市,但 NVIDIA 已經開始佈局未來幾年服務器級 GPU 生態的演進方向。

在介紹 Rubin 之前,老黃特意指出:“Blackwell 其實命名有誤。” 他解釋稱,Blackwell B200 實際上是 雙核心設計,這導致 NVLink 互聯架構發生變化。因此,儘管 B200 被稱爲 NVL72,但實際上更準確的叫法應該是 NV144L,而未來的 Rubin 方案將會沿用這一命名方式。
Rubin NVL144:FP4 算力提升至 3.6 PFLOPS,FP8 訓練性能大增
Rubin GPU 的首發產品 NVL144 將 完全兼容現有的 Blackwell NVL72 服務器架構,但算力表現大幅提升:FP4 精度計算性能:3.6 PFLOPS(B300 NVL72 爲 1.1 PFLOPS),FP8 訓練算力:1.2 ExaFLOPS(B300 NVL72 僅爲 0.36 ExaFLOPS),計算性能整體提升 3.3 倍。
Rubin 還將從現有的 HBM3 / HBM3e 內存升級至 HBM4,而 Rubin Ultra 則會採用 HBM4e,進一步提高帶寬。每顆 GPU 的顯存仍爲 288GB,但內存帶寬從 8 TB/s 提升至 13 TB/s。
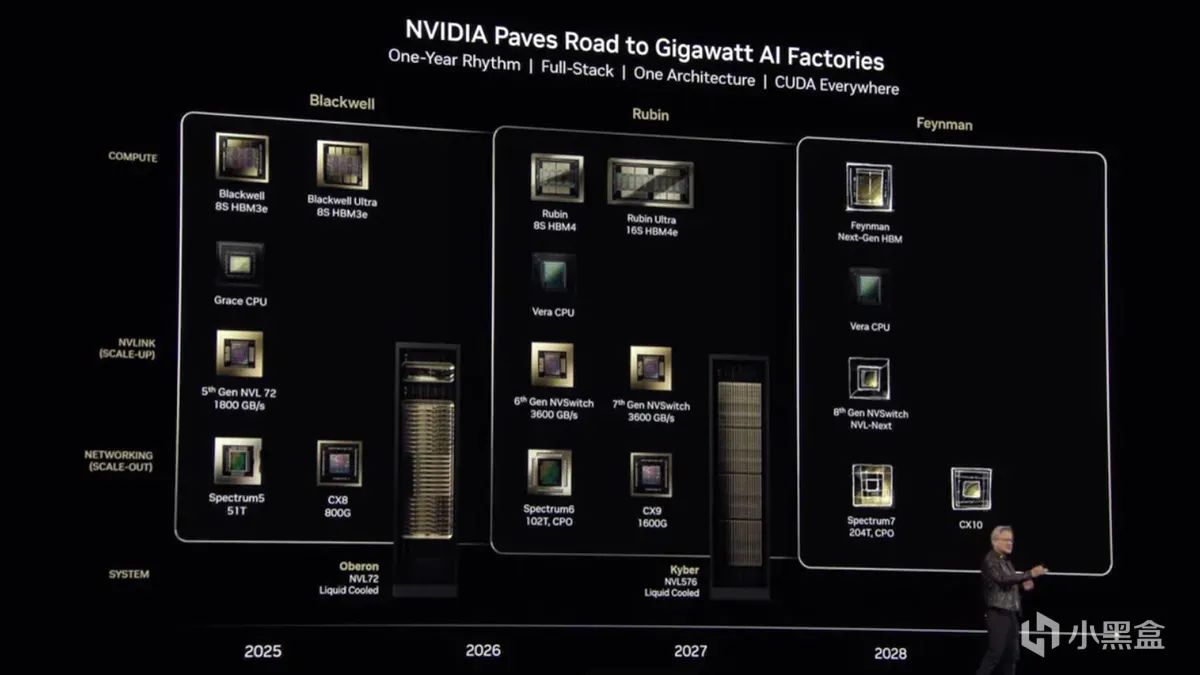
在互聯方面,NVLink 速率翻倍,總帶寬達到 260 TB/s,新一代 CX9 互聯 允許機架間數據交換速率提升至 28.8 TB/s(是 B300 CX8 的兩倍)
Rubin Ultra,算力飆升 4 倍,最高支持 576 顆 GPU 並行計算
2027 年 Rubin Ultra 上市後,數據中心架構將迎來又一次飛躍。儘管 Rubin Ultra 仍會搭配 Vera CPU(替代當前的 Grace CPU),但 GPU 性能將迎來質變。NVL576 架構,每個機架支持 576 顆 GPU,FP4 精度推理計算:提升至 15 ExaFLOPS(Rubin NVL144 爲 3.6 ExaFLOPS),FP8 訓練計算:提升至 5 ExaFLOPS。
Rubin Ultra 採用四核心 GPU 封裝,大幅提高計算密度,每個機架提供 365TB 高速內存(相比 Rubin NVL144 的 75TB)。但是,Rubin Ultra 在 HBM4e 內存帶寬上的數據有所疑點,整體帶寬 4.6 PB/s,576 顆 GPU 平均下來僅 8 TB/s / GPU,相比 Rubin NVL144 的 13 TB/s / GPU 似乎有所下降,這可能與 四核心封裝 GPU 內部的互聯方式 相關,但目前 NVIDIA 尚未詳細解釋這一點。
在互聯架構方面,NVLink7 互聯速率提升 6 倍,總吞吐量 1.5 PB/s,CX9 機架間互聯速率提升 4 倍,達 115.2 TB/s

Rubin 之後,Feynman 架構登場,推向“千億瓦級 AI 數據中心”
除了 Rubin 及 Rubin Ultra,NVIDIA 還在 GTC 2025 上首次提及了 Feynman 架構。按照 NVIDIA 目前的命名習慣,未來可能會推出 Richard CPU 搭配 Feynman GPU,爲超大規模 AI 計算提供更強算力支持。
從 NVIDIA 的路線圖來看,未來幾年,數據中心 GPU 將繼續朝着 更高算力、更快互聯、更大帶寬 的方向發展,爲 AI 訓練、科學計算和企業級推理任務提供前所未有的性能支持。Rubin 只是 NVIDIA AI 計算生態的下一個階段,而 Feynman 可能會真正推動行業邁向“千億瓦級 AI 數據中心”時代。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com

















