2月18日,今天大模型領域又迎來新動向,馬斯克在今天中午發佈了Grok-3大模型,跟上DeepSeek和OpenAI的步伐,引入了“思維鏈”推理機制,同時在數學、科學和代碼生成等領域表現出色,消耗了大約20萬塊英偉達GPU訓練而成,測試數據顯示Grok-3性能已經媲美甚至超越DeepSeek等競爭對手!與此同時,DeepSeek也在今天發佈了一篇全新的技術論文NSA!

馬斯克旗下人工智能公司xAI在去年8月份,發佈了 Grok-2 大模型早期預覽版,隨後在12月向X平臺上的所有用戶免費推出新版 Grok-2 模型;在短短半年時間過後,馬斯克再推出了Grok 3的早期預覽版,Grok 3被視作對OpenAI o3-mini和DeepSeek-R1的回應。
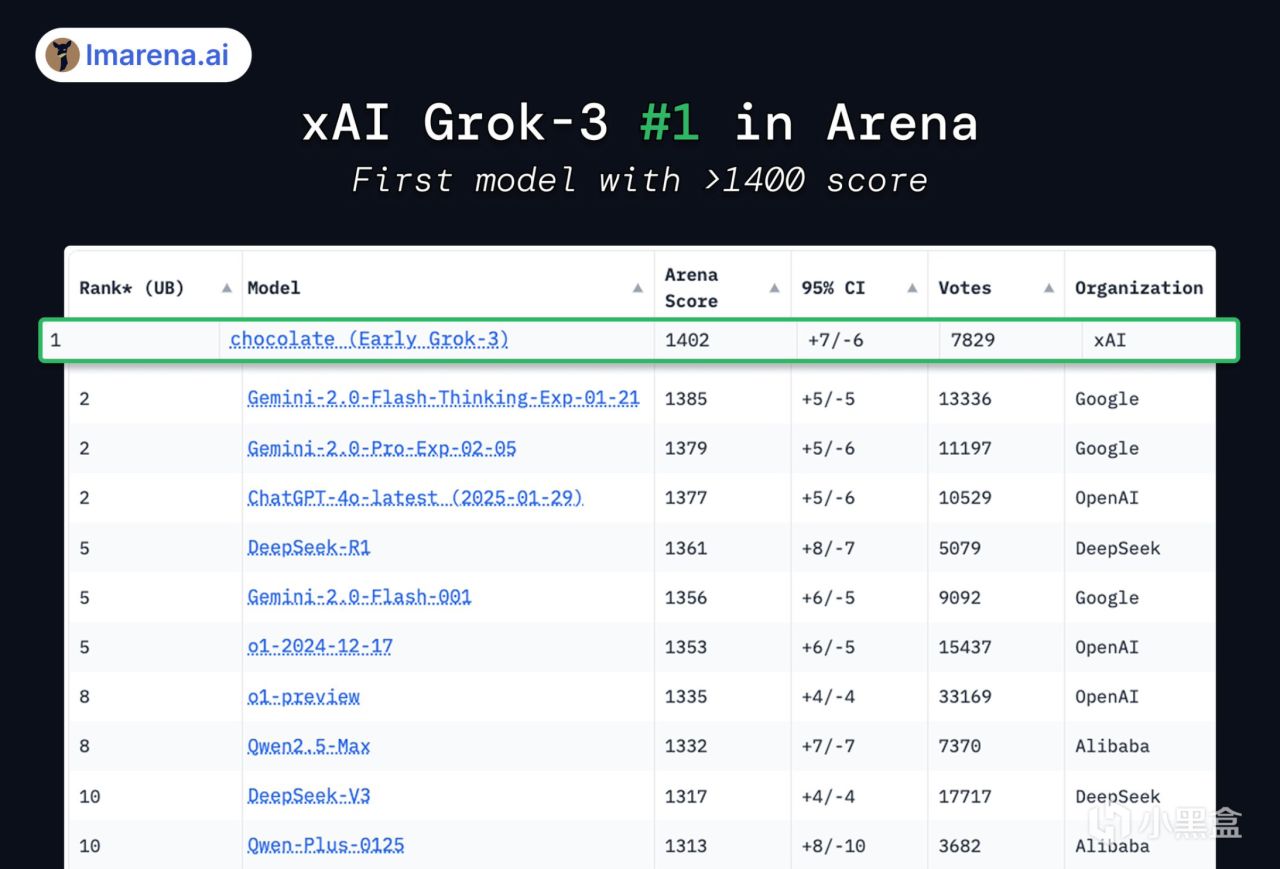
從AI基準測試開放平臺lmarena.ai的數據顯示,Grok-3(代號chocolate)在Arena排行榜上拿下了第一,成爲有史以來第一個獲得超過1400分的模型!
馬斯克聲稱,Grok-3在AIME和GPQA等基準測試中,擊敗了市面上包括OpenAI o3-mini、o1、DeepSeek-R1和Germini-2等在內的所有模型。

OpenAI聯合創始人Andrej Karpathy在體驗後表示,Grok-3 + Thinking的感覺與ChatGPT的o1-pro差不多,略好於DeepSeek-R1和谷歌的Gemini 2.0 Flash Thinking。

不過在發佈會之後,有用戶發現Grok-3在特定領域的表現存在問題,比如有直播主(愛迪生玩遊戲)測試《流放之路2》遊戲時,相關問題錯誤頻出,另有用戶測試發現Grok-3在經典的多邊形小球編程問題上也出現了錯誤。

馬斯克在直播時透露,Grok 3訓練過程累計消耗20萬塊英偉達GPU,訓練在xAI公司的數據中心完成。馬斯克同時還介紹Grok之後會陸續上線語音交互多模態功能,並且xAI還將成立AI遊戲工作室。

這次直播過程中,馬斯克旁邊站在C位的是兩位華人科學家,分別是多倫多大學助教Jimmy Ba和xAI聯合創始人吳宇懷,其中Jimmy Ba是諾獎、圖靈獎得主辛頓的學生,吳宇懷初中在杭州建蘭中學就讀,後來轉到加拿大讀高中,在多倫多大學、斯坦福大學完成學業,先後在DeepMind和OpenAI實習,後來與馬斯克一起成立了xAI。
今天DeepSeek之後也發佈了一篇關於NSA的純技術論文報告,NSA通過針對現代硬件的優化設計,在提升推理速度的同時降低預訓練成本且不犧牲性能。在通用基準測試、長上下文任務以及基於指令的推理中,NSA的表現可媲美甚至超越全注意力模型。

比如在8卡A100計算集羣上,NSA的前向傳播和反向傳播速度分別比全注意力快9倍和6倍,在處理64k長度的序列時,NSA在解碼、前向傳播和反向傳播等各個階段都實現了顯著的速度提升,最高可達11.6倍,NSA的推出爲AI模型的長上下文訓練帶來了新的可能性,這篇論文署名還有DeepSeek的創始人梁文鋒!隨着DS的入場,今年的AI大模型領域競爭也格外激烈,開源仍然是當下的趨勢,馬斯克也宣佈當Grok 3成熟穩定後,將會開源Grok 2,算是半開源(如開)。

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















