
今年過年,年味濃不濃俺不好說,但 AI 味肯定是夠夠的了。
這麼說吧, DeepSeek 憑一己之力,拉高了全國對 AI 的認知程度。

至於 DeepSeek 到底有多厲害,想必這段時間哥幾個也已經上手體驗過了,說它是目前最懂中文互聯網的 AI 模型,應該沒人有意見吧?
反正從身邊人統計學來看,這段時間什麼 Claude 、 ChatGPT 通通都不香了。
OpenAI 大年初四發 o3 推理模型,今天又免費開放了搜索功能,谷歌的 Gemini2.0 全量開放,還有阿里的 Qwen2.5-Max 也發力打榜 DeepSeek 。。。

要我說,這些科技公司還是得逼一把,不然你都不知道他們的實力到底有多少。
先說 OpenAI 的 o3 ,去年底的發佈會就傳出了消息,說今年 1 月份要上線。
但奧特曼估計也沒想到,被 DeepSeek 狙了一手,現在這個發佈的時間節點,多少就有點耐人尋味了。包括世超也覺着, o3-mini 的發佈是爲了反擊 DeepSeek 。
當然回到正題啊,這次的 o3-mini ,號稱是他們的推理系列中最具成本效益的模型,還尤其擅長科學、數學和編碼,響應的速度也更快。
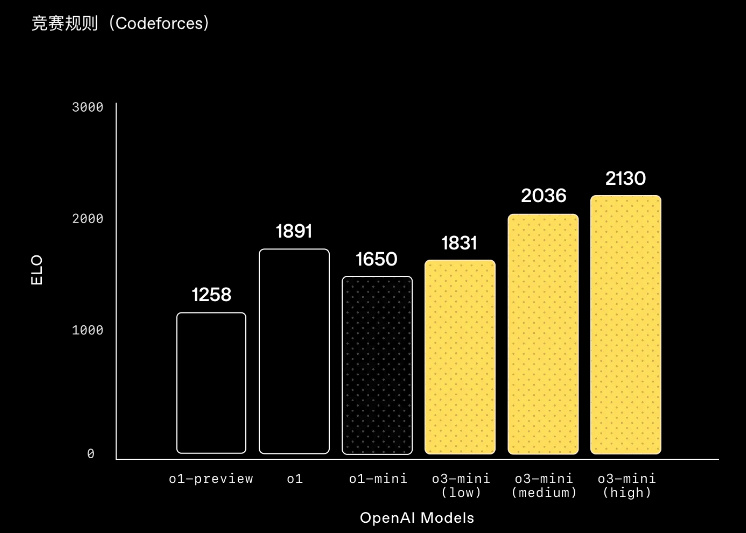
就拿編程來說,除了 o3-mini ( low )打不過 o1 以外, o3-mini 三個檔位的模型,基本亂殺前輩 o1 系列。
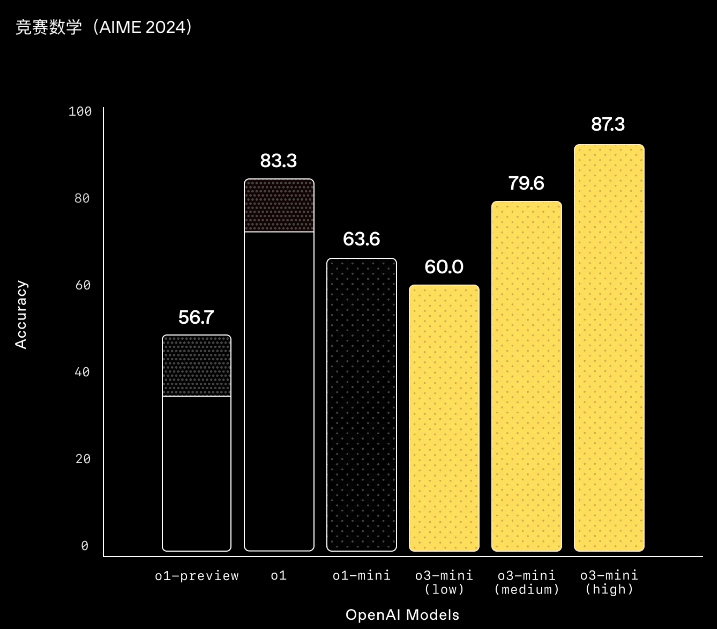
競賽數學也不在話下, o3-mini ( high )的表現都要好過 o1 系列。
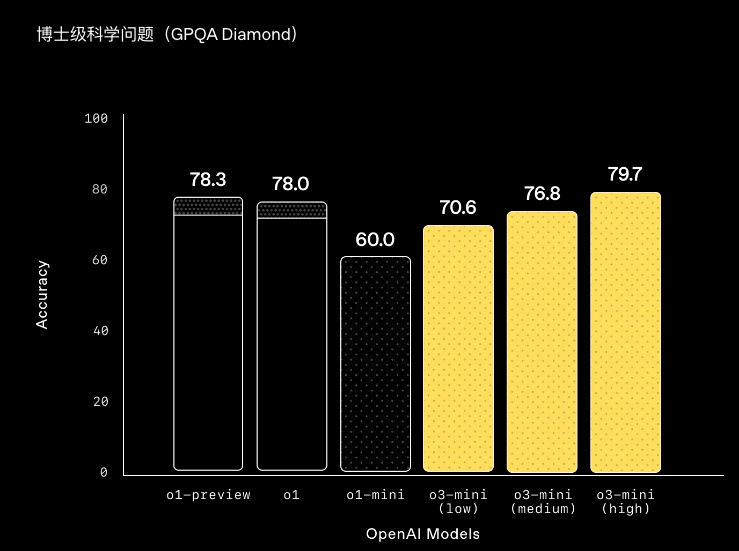
就連博士級別的題目, o3-mini 也能跟 o1 系列打得有來有回。
x 上有老哥用同一組 prompt 測試了 o3-mini 和 DeepSeek R1 ,得出的結論是 “ o3-mini ( 編程能力 )碾壓 DeepSeek R1 ” 。

說實話,光看視頻的話,確實是 o3-mini 的效果更逼真。

另外一位老哥也測試了一把 o3-mini 的物理理解能力( prompt :編寫一個球在超立方體內彈跳的 Python 腳本 ),直接誇 o3-mini可能是物理學得最好的模型。
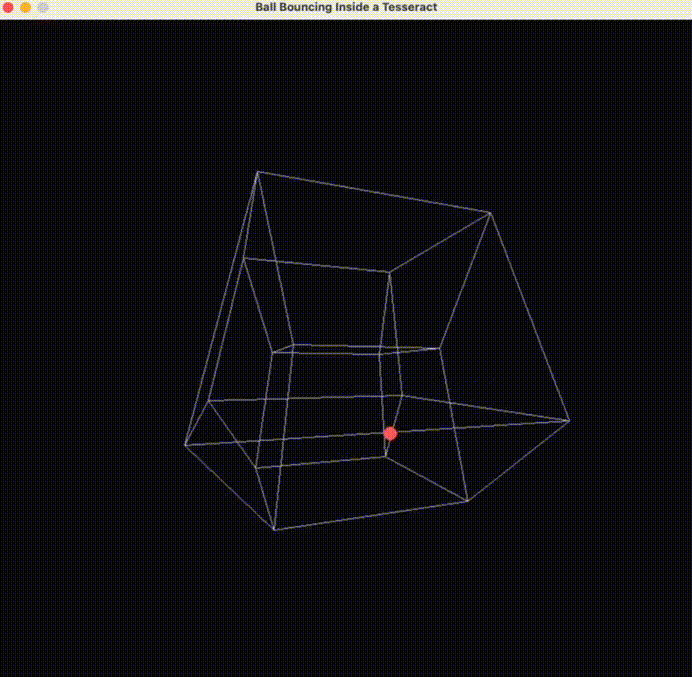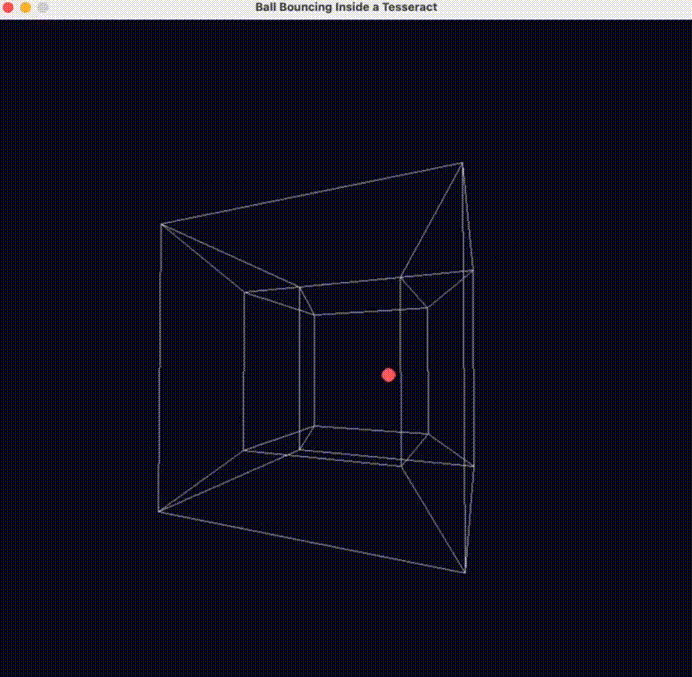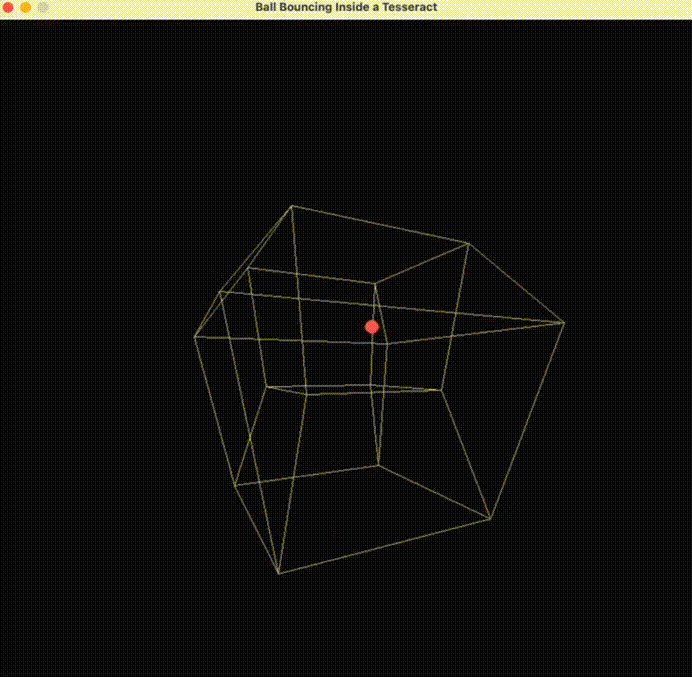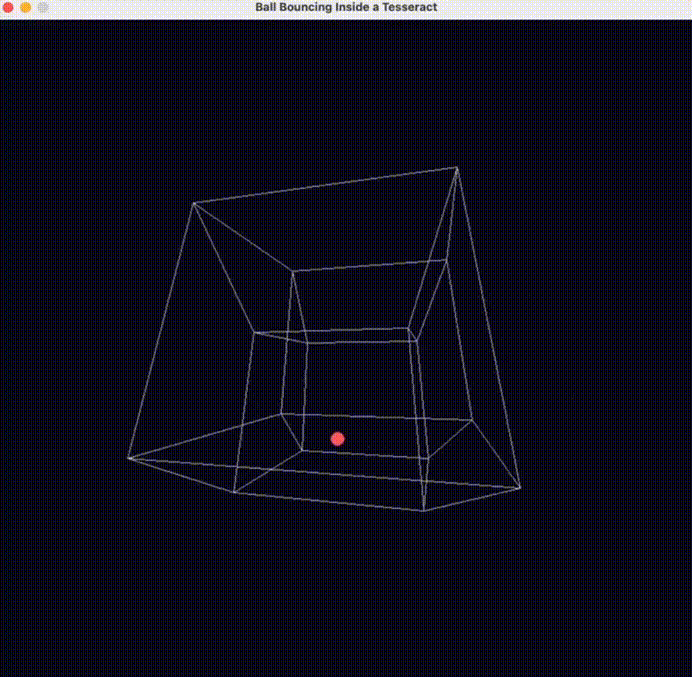
反正看了一波大夥兒的測試,世超覺着 o3-mini 似乎更接近咱們一直在說的,能夠理解物理世界、模擬物理規律的世界模型。
重點是, o3-mini 現在免費就能用上,可比之前的 o1 要大方的多了。
這不,除了發佈 o3-mini 外, OpenAI 又趁着咱們開工的這兩天,免費開放了 ChatGPT 搜索。
現在你甚至都不需要註冊,就能直接用。
過年那陣,微軟也讓所有的 Copilot 用戶免費用上了 o1 推理模型,要不說還得謝謝 DeepSeek 呢。
同樣是去年 12 月發佈 Gemini 2.0 ,但那會兒只有開發者和一部分測試者能用,一直咕咕咕也不見有動靜。
結果被 DeepSeek 這麼一激,一口氣發了三個版本的 Gemini2.0 模型。
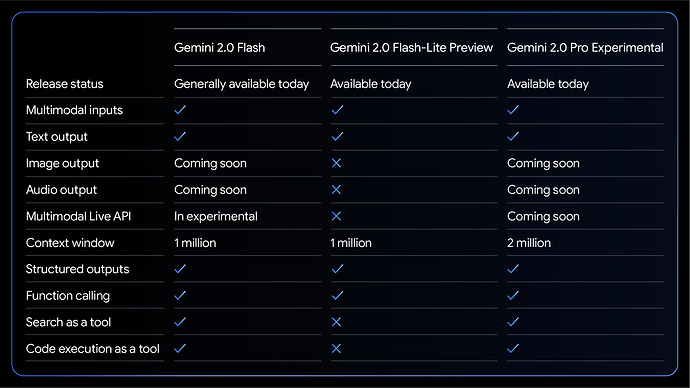
基準測試中,各方面性能也都優於前代模型。
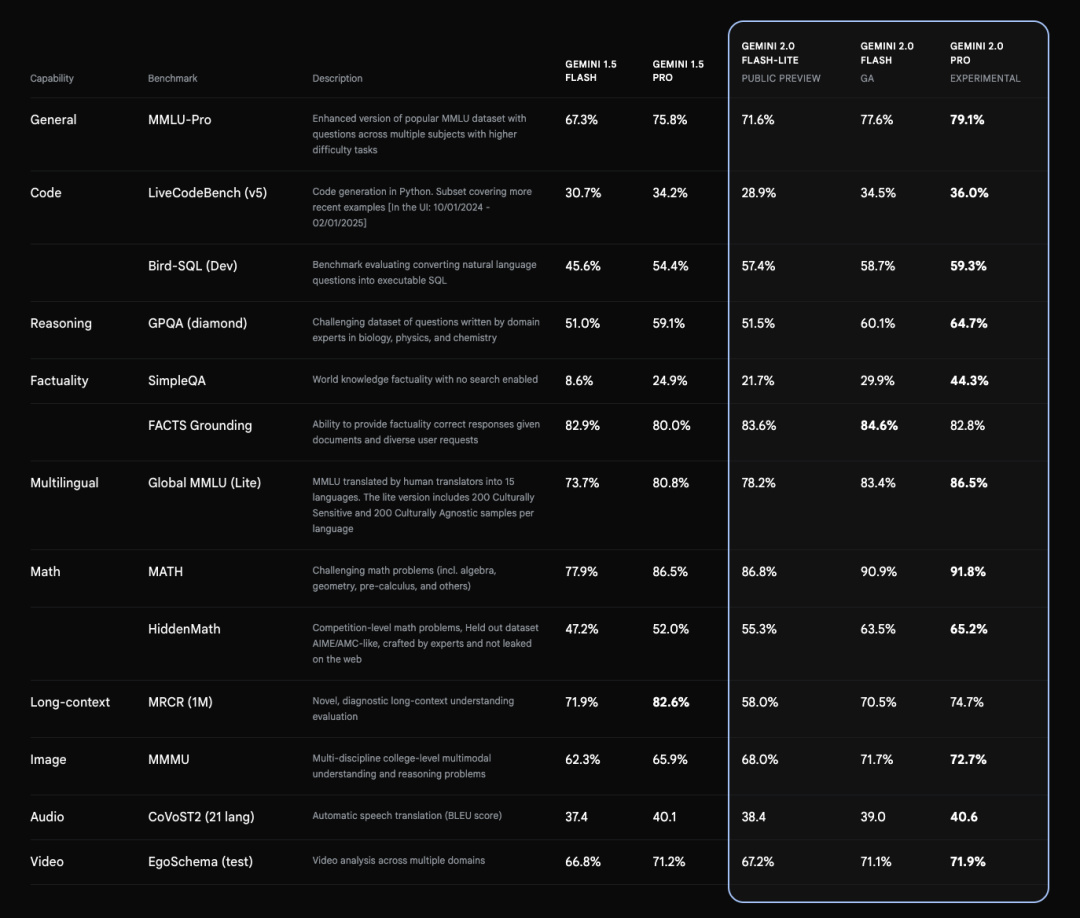
但相比 DeepSeek 和 OpenAI 的熱度,谷歌這邊多少就顯得有些無人在意了。
再來看國內的情況,阿里雲算是第一個對 DeepSeek 發起 “ 進攻 ” 的公司。
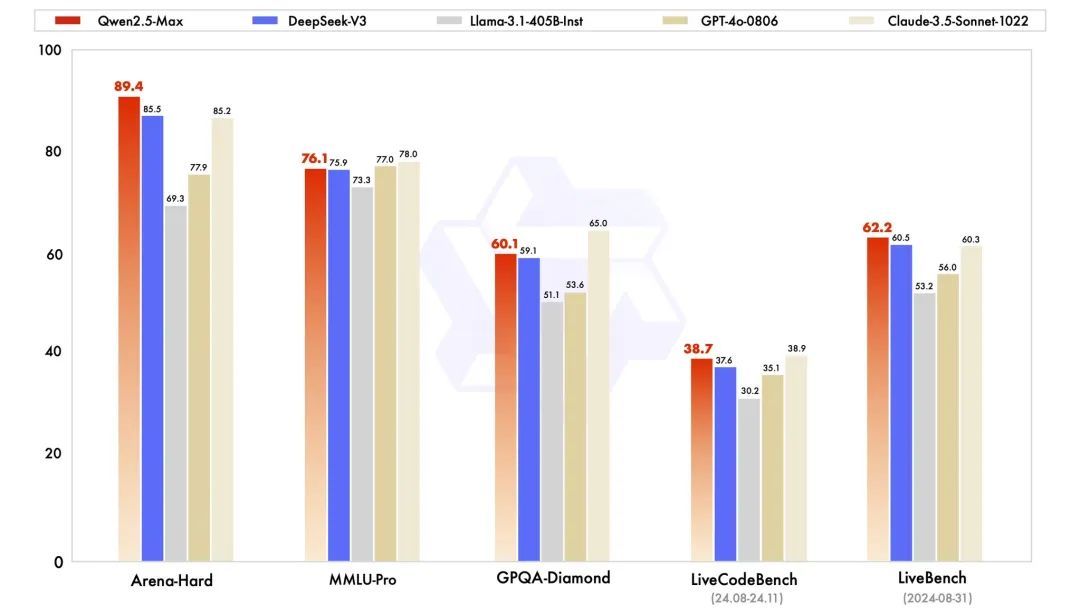
根據阿里雲官方的說法, Qwen2.5-Max 在多個基準測試中,超越 DeepSeek V3 、 o1-mini 等多個模型。
並且在 Chatbot Arena 的大模型盲測排行榜上, Qwen2.5-Max 衝到了第七的位置。
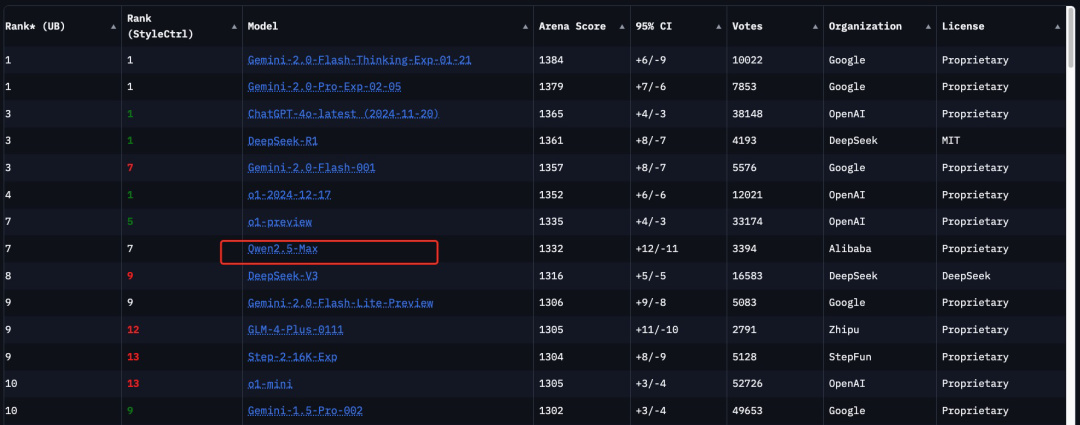
具體看模型的數學和編程能力,甚至還能拿第一。

所以 Qwen2.5-Max 在發佈後,國內有不少媒體都出來捧了一波。
反正世超看下來,這次由 DeepSeek 掀起的新一輪 AI 軍備競賽,領頭的這一批公司已經掏出了不少真傢伙。
不過說實在的, DeepSeek 這出後來者居上的戲碼,的確給咱上了一課。
咱們坐着等就成,今年的模型大戰肯定有的看了。
撰文:西西
編輯:江江&面線
美編:萱萱
圖片、資料來源:X、OpenAI官網
部分圖源網絡
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com














