EXO Labs最近發佈了一段令人驚歎的視頻,展示了他們在一臺擁有26年曆史的老舊Windows 98奔騰2PC上成功運行大規模語言模型(LLM)。這臺主頻爲350MHz的經典電腦不僅順利啓動了Windows 98操作系統,還成功啓動了基於Andrej Karpathy的Llama2.c定製推理引擎。在運行該引擎時,EXO請求AI生成關於“Sleepy Joe”的故事,生成速度令人驚訝,超出許多人的預期。

這一項目背後有着更深遠的背景。EXO Labs自成立以來,一直秉承“民主化AI”的理念,致力於通過開放的基礎設施讓AI技術不再被少數大型公司所壟斷。由牛津大學的研究人員和工程師組成的EXO團隊認爲,大型企業主導AI領域可能會對社會、文化和真相產生不利影響。因此,他們的目標是讓世界上任何地方的任何人都能在自己的設備上運行最先進的AI模型,這次在Windows 98上的演示正是這一理念的生動體現。
在文章中,EXO詳細描述了他們如何將Llama模型成功移植到Windows 98上的過程。首先,他們購買了一臺舊款Windows 98電腦作爲實驗基礎,但從一開始就面臨了不少挑戰。例如,將數據從現代設備傳輸到這臺老機器就成了一大難題,最終他們只能使用“老式FTP”協議,通過這臺老PC的以太網端口進行文件傳輸。
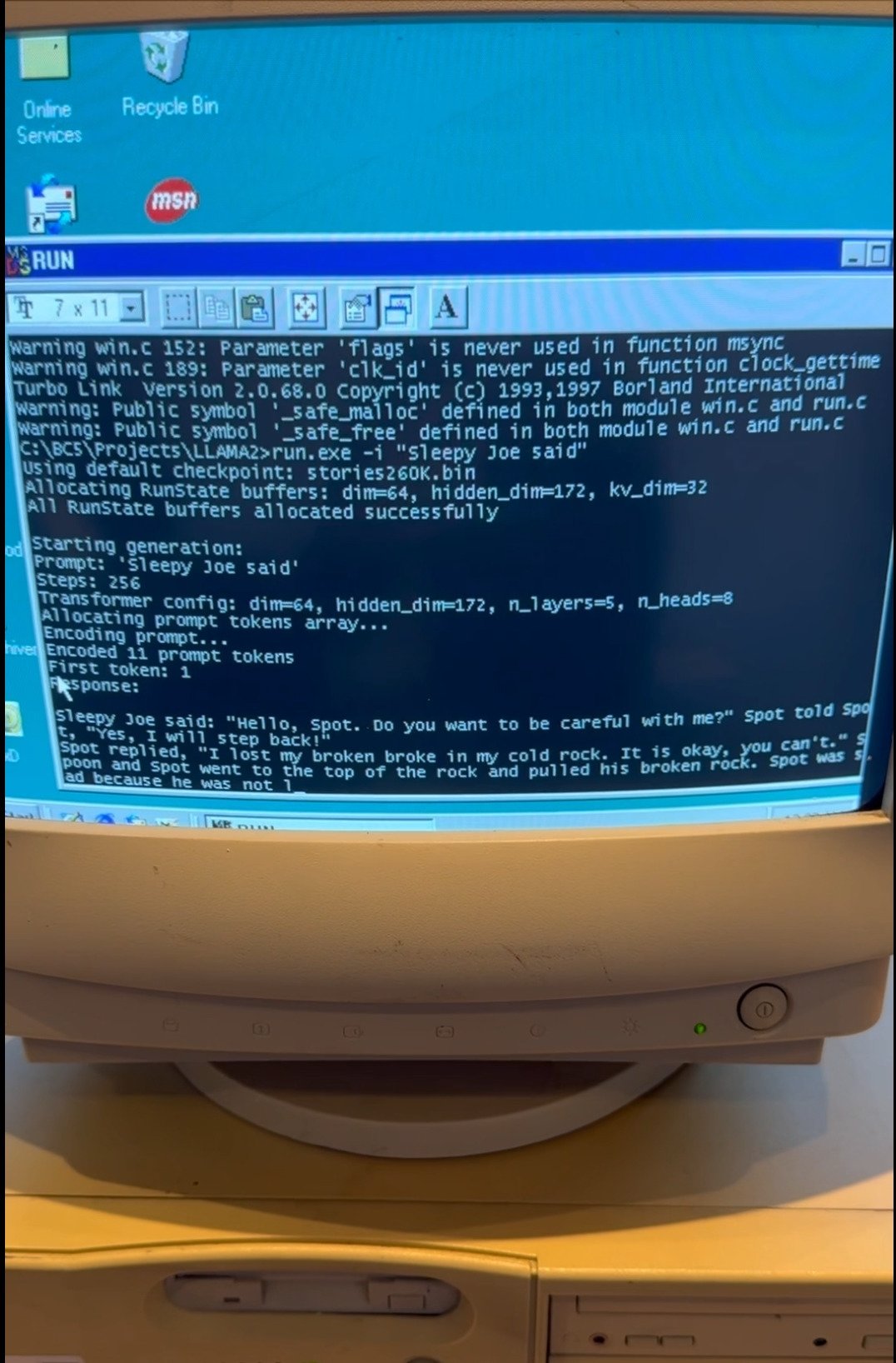
更具挑戰性的是如何將現代化的代碼移植到Windows 98環境中。爲了實現這一目標,EXO團隊找到了Andrej Karpathy開源的Llama2.c推理代碼,這是一個僅包含700行純C代碼的項目,可以運行Llama 2架構的推理任務。Karpathy,曾是特斯拉AI負責人,也是OpenAI創始團隊成員,提供了這一重要資源。藉助舊版Borland C++ 5.02 IDE和編譯器,經過一些調整後,EXO將代碼編譯成了可以在Windows 98系統上運行的可執行文件,併成功實現了推理任務。
根據EXO的博客,在使用260K LLM和Llama架構時,生成速度達到了“35.9 tok/s”。當模型規模升級至15M LLM時,生成速度提升至略高於1 tok/s。儘管如此,當使用Llama 3.2 1B模型時,生成速度則顯著下降,僅爲0.0093 tok/s。這一實驗展示了即使在資源極其有限的環境下,AI技術依然能夠取得令人驚豔的成績。
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















