樓主有個微信羣,裏面都是一些從小玩到大的好朋友,且裏面沒有一對情侶,就在樓主以爲大家要朋友一生一世的時候,樓主在某一個飯局發現有個女生揹着羣友在和另一個好兄弟激情私聊
在樓主的狂熱追問下,兄弟也承認了對那個女生的好感。這消息對於樓主這位八卦魔王來說簡直是驚天地泣鬼神
於是,爲了避免錯過更多八卦。也爲了使得有情人終成眷屬,樓主用Python+微信羣的聊天記錄做了簡要的分析~~~旨在找出潛在的暗戀關係

願天下有情人終成眷屬
首先需要的是那個微信羣的聊天記錄,樓主是根據WeChatMsg這個開源項目去做的,大家可以去Github搜,或者直接在google搜,Github那個頁面上有很詳細的教程,所以在樓主這裏從略~大家有不明白的也可以評論區找樓主~~

導出來大概是這個樣子~
樓主這個羣半年就產生髮了一萬多條消息吧~
於是就可以開始打Code啦,最後結果會以熱力圖體現~~~

樓主的想法是先根據時間信息對時間進行一個聚類,聚類得到很多個不同的話題(比如說按照一段時間沒人說話就分成另一個話題)樓主這裏用的是密度聚類(按一個小時),盒友也可以嘗試下別的聚類方法~,然後再對每個話題進行相關分析~
一、對時間進行聚類形成話題
首先引用一些庫
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score
from scipy.stats import pearsonr
然後導入你的數據
mydf = pd.read_csv('你的那個羣哈.csv')
Strtime = mydf.StrTime.tolist()
Createtime = mydf.CreateTime.tolist()
dic_time = dict(zip(Createtime,Strtime))
nicknamelst = mydf.NickName.tolist()
dict_name = dict(zip(Createtime,nicknamelst))
nickname= list(dict.fromkeys(nicknamelst))
dic_nameint = dict(zip(nickname,range(len(nickname))))
dic_intname = dict(zip(range(len(nickname)),nickname))
然後聚類
# 示例一維數據點
data = Createtime
# 設定距離閾值δ
delta = 3600
# 初始化一個空列表,用於存儲聚類結果
clusters = []
current_cluster = []
# 遍歷數據點
for i in range(len(data)):
# 如果current_cluster爲空,或者當前點與上一個聚類點的距離小於等於delta
if current_cluster == [] or (len(current_cluster) > 0 and abs(data[i] - current_cluster[-1] <= delta)):
# 添加到當前聚類
current_cluster.append(data[i])
else:
# 否則,保存當前聚類並開始新的聚類
clusters.append(current_cluster)
current_cluster = [data[i]]
# 保存最後一個聚類(如果有的話)
if current_cluster:
clusters.append(current_cluster)
注意此處若你想把聚類閾值設爲兩個小時(兩個小時沒人說話就分新一類)可以把delta設置爲7200
Createtime是time的連續版本(兩個時間相差的秒數就等於兩個Createtime的差值),可以通過字典實現Createtime與Strtime之間的一一對應
timemap = []
for i in clusters:
if len(i)>=2:
timemap.append(i)
此處是拋棄那些只有一個人說了話的話題,把話題對應createtime記錄在timemap裏
二、實現每個人的話題參與向量
描述很多個人在很多個話題中的發言情況時,如果一個人對某個話題說了話則標記爲1,沒說話則標記爲0
,如此可得n個人的話題參與向量(m個話題的話爲m*1的向量)
data = [[0 for i in range(len(timemap))] for z in range(len(nickname))]
for k,i in enumerate(timemap):
namelst = [dict_name[q] for q in i]
for p,z in enumerate(nickname):
if z in namelst:
data[p][k]=1
三、描述兩個人聊天的相關性(方法一)
此處提供了兩個個分析方法,data1,2都是n×n的矩陣,data1的第i行第j列意味着n個人裏面第i個人的話題參與向量預測第j個人的話題參與向量得到的auc值
data2的第i行第j列意味着n個人裏面第第i個人參與了的話題,第j個人參與了多少(百分比佔比多少)
data1=[[0 for i in range(len(nickname))] for j in range(len(nickname))]
data2=[[0 for i in range(len(nickname))] for j in range(len(nickname))]
for i,j in enumerate(nickname):
for p,q in enumerate(nickname):
data1[i][p] = roc_auc_score(data[i], data[p])
count1 = 0
count2 = 0
for k in range(len(timemap)):
if data[i][k]==1:
count2+=1
if data[i][k]==1 and data[p][k]==1:
count1+=1
data3[i][p] = count1/count2
四、描述兩個人聊天的相關性(方法二)
也可以用接話程度去描述一個人是不是喜歡另一個人,我把每個話題,誰接這個人話接最多,那統計出來的矩陣人A和人B對應的值就會+1,最後總體來看誰接這個人話最多~
data3 = [[0 for i in range(len(nickname))] for z in range(len(nickname))]
for i in timemap:
namelst = [dict_name[p] for p in i]
for k in range(len(nickname)):
q_lst = [0 for i in range(len(nickname))]
for z,j in enumerate(namelst):
if z == len(i)-1:
break
if j == dic_intname[k]:
q_lst[dic_nameint[namelst[z+1]]]+=1
# print(q_lst)
q_lst[k]=0
for i1,i2 in enumerate(q_lst):
if i2 == max(q_lst) and max(q_lst) != 0:
data3[k][i1]+=1
五、繪製熱力圖
(想畫data幾的就第一行輸入data幾)
for i in range(len(nickname)):
data1[i][i]=0
map = pd.DataFrame(data1)
plt.figure(figsize=(10, 10))
plt.rcParams['font.sans-serif'] = ['SimHei']
realname = [dict_realname[i] for i in nickname]
sns.heatmap(map, annot=True, cmap="YlGnBu")
plt.title('丘比特的箭靶子')
plt.xticks(ticks=range(len(nickname)), labels=nickname, rotation=90) # 旋轉90度以便豎着顯示
plt.yticks(ticks=range(len(nickname)), labels=nickname, rotation=360)
plt.xlabel('羣友')
plt.ylabel('羣友')
plt.show()
六、看圖
然後就好啦,展示一下羣主畫的熱力圖吧~
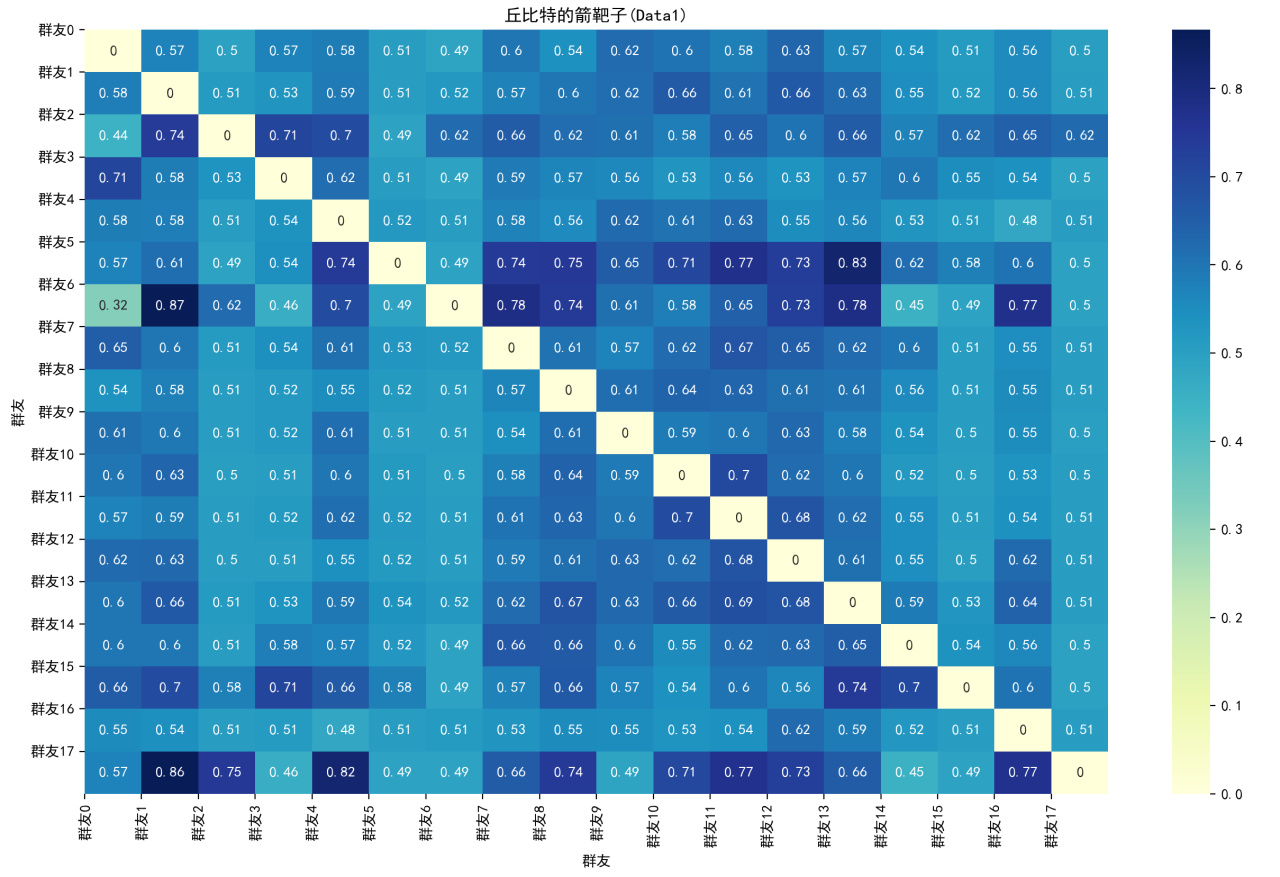
Data1的,這裏的值爲0.5意味着平常,相對而言大意味着顯著
此處i(行數),j(列數)點代表着羣友i的發言頻率可以推測出羣友j的發言頻率的概率,如果高,意味着j的發言有可能是受到i影響,如果某個男人的發言只會被很多男生和一個女生影響,那意味着上面不必多說吧~
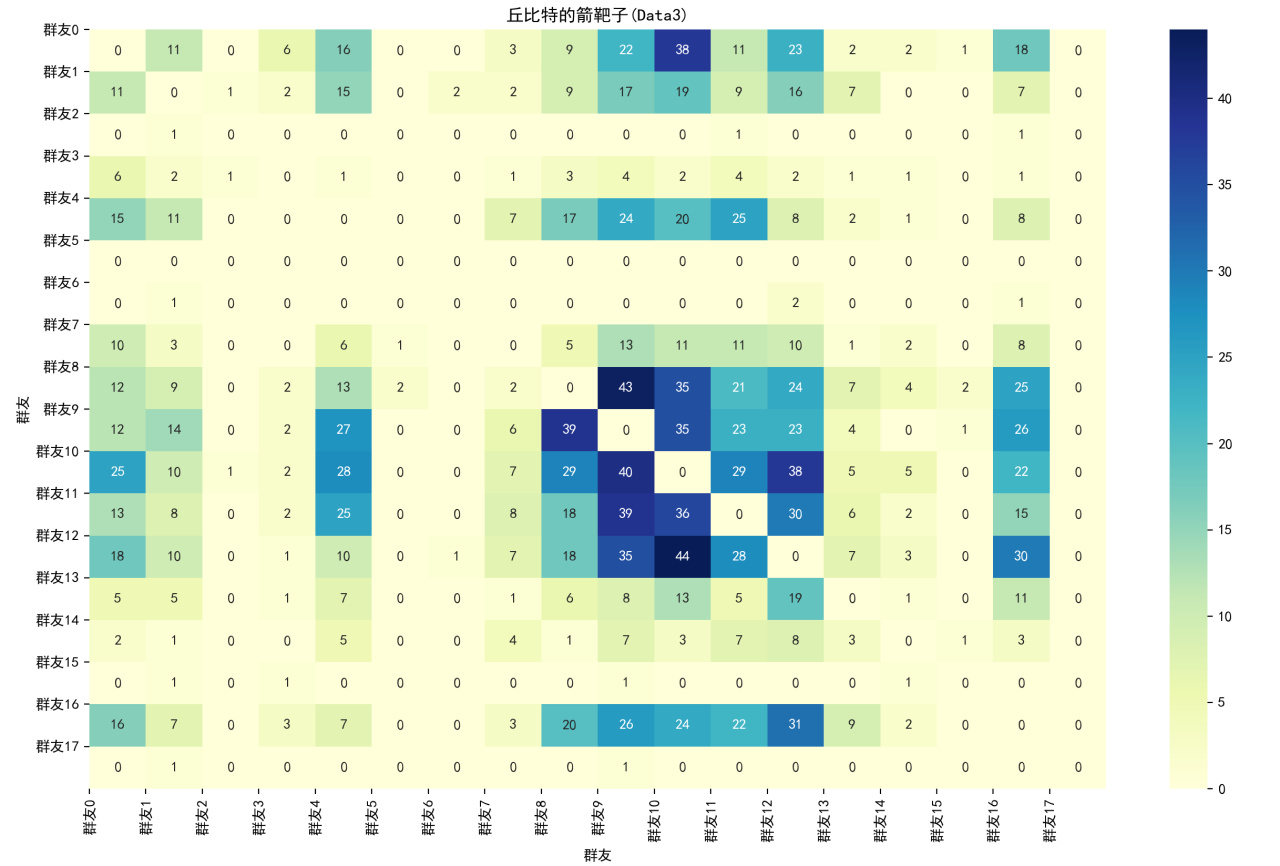
Data3的,數值越大意味着橫軸作爲縱軸話題接話最多者的次數
此處,樓主剛開始說到的男女生分別爲羣友4和7,實踐發現他們是接對方話接的話題最多的異性,而且是斷檔領先,由此得知~~
此外,也可以由data2看第二個人因第一個人出現而出現的頻率是多少~圖就先不放了哈~~
七、尾聲
大概就是這樣~~其實這篇文章的還未找到明確的文章依據(微信羣聊天怎麼樣纔是一個人喜歡另一個人哈)本文的依據是一個人對另一個人有意思,那麼兩個人共同參與話題的可能性就會更大以及第二個人接第一個人話的可能性會更大。如果有優秀的心理學社會學盒友能幫忙把這一塊依據補上那真是萬分感激~~~

如果有其他八卦頭子有其他八卦方法也歡迎在評論區一起討論呀
文中哪裏有問題的也歡迎隨時評論區批判我
最後還是聲明一下,如果羣裏有朋友介意這種分析 那最好就不要做啦
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com
















