最近看到一位国外coder的观点,觉得有点意思,分享给大家。
对人类开发者而言最优的,或者至少是我们认为理想的,并不一定是对 AI 助手而言最优的。随着 AI 逐步融入我们的开发流程,我们也需要做出相应的调整。你的代码不应该只适合给人看,更应该适合给AI看。

他举的例子主要是ts的,不过其他语言也是类似思想。
1.代码即文档(Documentation as Code)
传统做法: 详细的文档通常存放在 Wiki、Notion 或团队知识库中,与代码库分离。
AI 友好的做法: 在项目根目录和每个子模块中放置详尽的 README.md 文件。创建 CONTRIBUTING.md,说明编码规范、PR 预期和测试覆盖要求。如有必要,可以在源码附近添加额外的文档,或者在代码中直接注释,解释代码的目标和技术实现,以便 AI 更好地理解。AI 可以直接读取这些文档,并据此执行任务,无需额外的自定义提示或专门的 AI 指南 —— 你的项目文档本身就变成了 AI 的操作手册。

2.减少包的碎片化(Minimize Package Explosion)
传统做法: 为每个独立功能创建一个新的包,以强化关注点分离(Separation of Concerns)。
AI 友好的做法: 采用尽可能少的包,并确保每个包的边界清晰。只有当代码需要在多个应用之间共享时,才创建独立的包。
AI 代理在处理大量包时会遇到困难,就像新加入的开发者一样。每增加一个包,AI 需要理解的不仅是代码本身,还有它与其他包之间的关系,从而增加了认知负担。

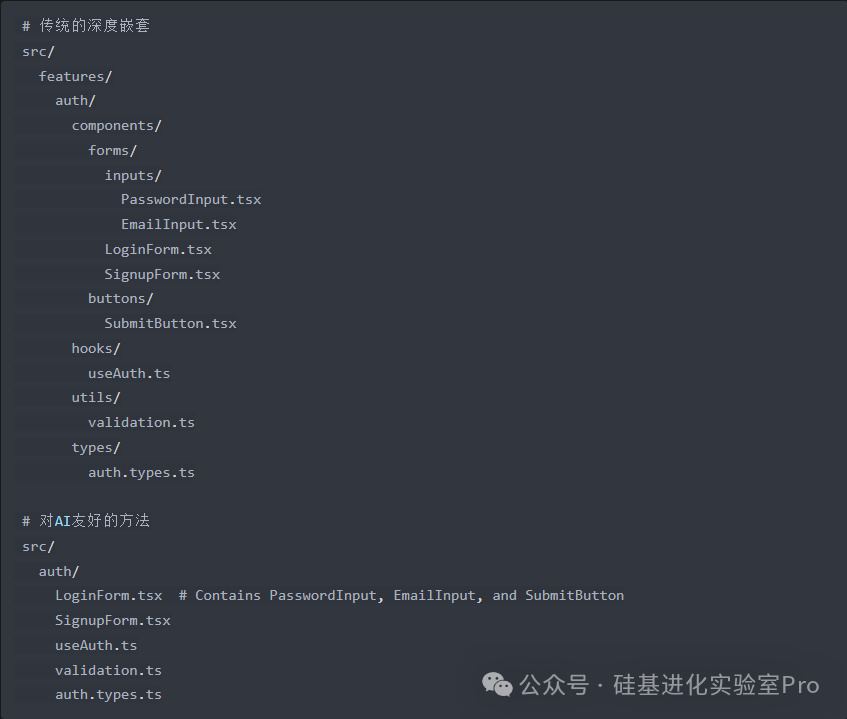
3.简化项目结构(Simplify Project Structure)
传统做法:采用深层嵌套的目录结构,并拆分成许多小文件,以实现最大程度的模块化。
AI 友好的做法: 采用更扁平的目录结构,并使用语义清晰的命名。将相关功能放在一起,而不是分散在众多文件和文件夹中。
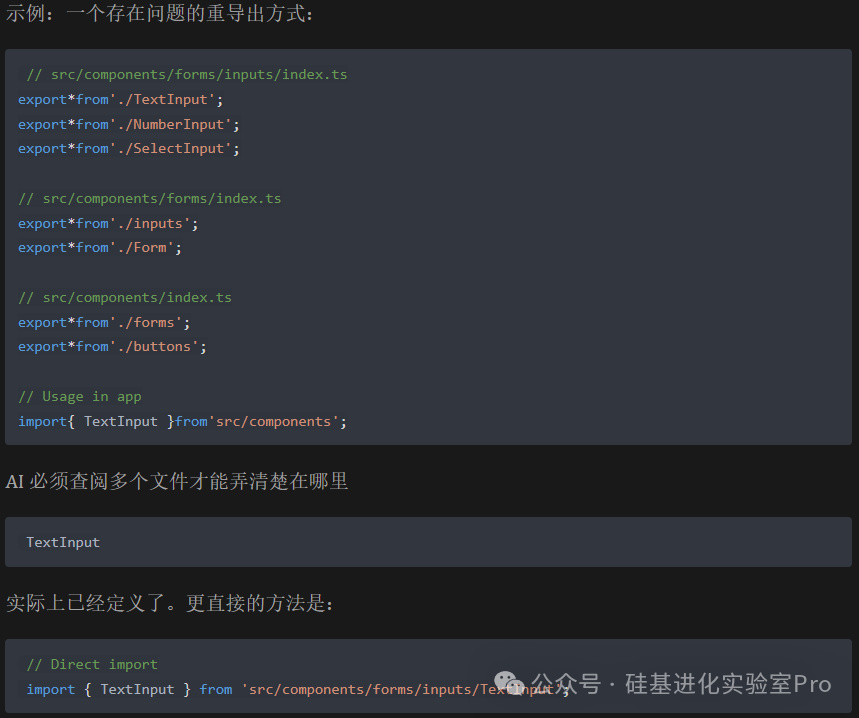
4.避免重导出和过多的间接引用(Avoid Re-exports and Indirection)
传统做法:在每个目录层级使用 index.ts 进行重导出,以创建整洁的公共 API。
AI 友好的做法:限制重导出仅用于包级别。内部的重导出会增加代码的间接性,使 AI 更难追踪依赖关系。
5.优先编译时验证而非运行时检查
传统方法:依赖运行时验证和测试来捕捉错误。
AI 友好方法:尽可能将验证推到编译时,使用强类型和静态分析。
6.将 Lint 规则和代码格式化配置统一到根目录(Consolidate Linting and Formatting at the Root Level)
传统做法: 在 Monorepo(多包代码仓库)中,每个包都有自己的 ESLint 和 Prettier 配置,导致风格不一致,维护成本增加。
AI 友好的做法: 将所有 Lint 规则和代码格式化配置集中到 项目根目录,确保所有包的风格保持一致,同时降低维护难度。
这种方法遵循 DRY(Don’t Repeat Yourself,不要重复自己) 原则,减少了单个包的复杂度。AI 只需要理解一个统一的 Lint 配置,而不是处理多个不同的规则集。
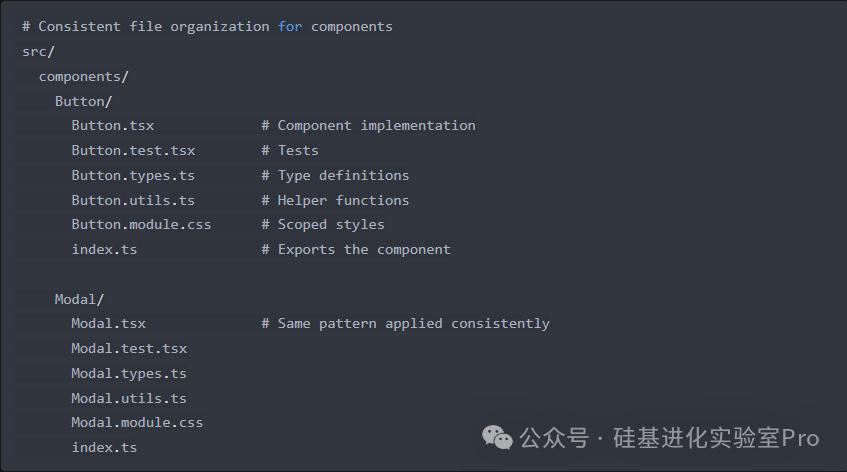
7.一致的文件组织模式
传统方法:根据不同开发人员的偏好或不断发展的标准,在代码库的不同部分以不同方式组织文件。
AI 友好方法:在组件或模块内使用一致、可预测的文件组织模式。
AI 模型在一致的模式下工作得更好,因为它们可以更轻松地预测在哪里可以找到相关代码以及组件应该如何结构化。这种一致性减少了 AI 和人类开发人员的认知负担。
这种共同定位有助于 AI 理解组件的所有方面,而无需在多个目录中搜索。一致的命名模式也使 AI 更容易预测特定功能的位置。
8.测试用例驱动的文档
传统方法:分别编写文档和测试,通常导致文档随着代码库的发展而变得过时。
AI 友好方法:使用编写良好的测试作为活的文档,清楚地展示函数和组件的预期行为。

更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com













