Intro——完全随机的游戏belike
让我们构想一个情景:你正在玩一款类Dota游戏,渡劫局,赢了这把就能升到最高段位。
这局游戏中你是远程大哥位,依仗暴击的那种射手。经过线上的唯唯诺诺,蒙头苦刷,你通过装备将自己的暴击率提升到50%。
接下来是重要的资源团战,你精致走位,疯狂平A,但是你逐渐发现不对,明明有50%的暴击率,但是你就是A不出几下暴击,只能看着对面的战士疯狂打乱你们的团战阵型。然后你输掉团战,节奏一塌糊涂,输掉对局,渡劫失败,被队友没收双亲,你愤而删游。
结束。
这就是没有概率补偿的类Dota游戏中极大可能出现的情况,在某些关键的节点,随机性并没有那么可靠,因为随机性真的太过随机了。

面板数据随机性的数学解读
一枚完全质地均匀,六面质量相同的理想骰子,投掷一次得到每一面的几率都是1/6,数学上称之为古典概型。试验中所有可能出现的基本事件只有有限个,且试验中每个基本事件出现的可能性相等。
那么假设玩家此时暴击率为50%,作为古典概型是否适合在游戏中表达呢?
还是回到骰子,此时骰子就在你的手上,连续投出六次,奇了怪了,居然全是六点。你又投了六次,这次居然又全是三点。你感到疑惑。
不是说好的1/6吗?
那么这里就要提到样本容量。样本容量是指一个样本中所包含的单位数,你一共投了六次骰子,那么样本容量为六次。样本容量的大小与推断估计的准确性有着直接的联系,在总体既定的情况下,样本容量越大其统计估计量的代表性误差就越小,反之,样本容量越小其估计误差也就越大。
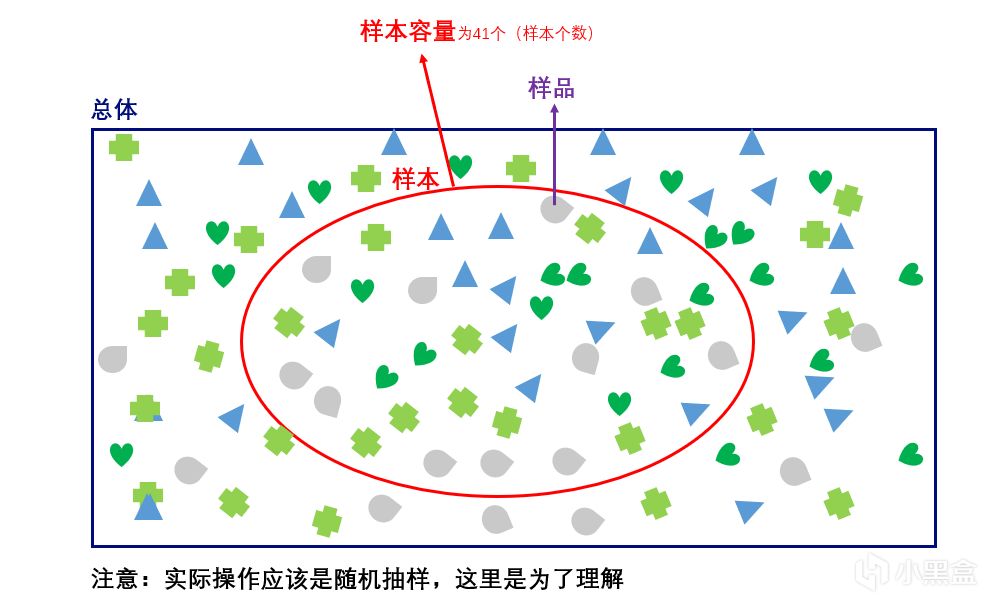
图源:https://www.cnblogs.com/yanFlyBlog/articles/14752635.html
六次是一个很小的样本容量,所以你有很大的可能并不能得到1/6这个值。而当你连续投上一万次,十万次,更多次,那么最终得到的数据将无限逼近1/6。
回到游戏上,人们对于概率的第一感知是片面的,因为样本容量难以直观感受。人们会自然地将视线关注到极端现象以及关键数据:比如连续没有达成其中某一结果,或者关键团战的概率结果。
举个例子,假设你保持50%的暴击率,在整局游戏中平A了一万次,最后统计,从总体来看,你暴击的次数在五千次左右,没有问题。可是你就是在关键团战中,一次暴击也没A出来。就这样,一段“合理“的极端情况毁掉了你一整局的游戏体验。
那有没有办法避免这样的极端情况,同时尽可能保持暴击率呢?
游戏设计师:“有的兄弟,有的!”

☝️🤓
概率补偿——为了游戏体验的巧妙设计
《魔兽争霸3》的设计师给出了“概率补偿”这一天才设计:
还是面板50%的暴击,这次我们这样设定——实际上,你第一次的暴击几率并没有50%,而是25.7%,如果这一次攻击没有暴击,那么下一次攻击的暴击几率提升到51.4%,以此类推,在第四次攻击时提升至100%。当产生暴击,下一次攻击的暴击几率再次回到25.7%。
我们来简单通过马尔可夫链的稳态概率计算一下,按照这样设计的实际暴击率是多少?
状态0:初始状态,暴击概率为25.7%(0.257)。
状态1:前一次未暴击,当前暴击概率为51.4%(0.514)。
状态2:前两次未暴击,当前暴击概率为77.1%(0.771)。
状态3:前三次未暴击,第四次必定暴击(100%)。
状态0:暴击后仍为状态0(概率0.257),未暴击转移到状态1(概率0.743)。
状态1:暴击返回状态0(概率0.514),未暴击转移到状态2(概率0.486)。
状态2:暴击返回状态0(概率0.771),未暴击转移到状态3(概率0.229)。
状态3:必定暴击,返回状态0(概率1)。
设稳态概率为π₀(状态0)、π₁(状态1)、π₂(状态2)、π₃(状态3),满足:
π₀ = 0.257π₀ + 0.514π₁ + 0.771π₂ + π₃
π₁ = 0.743π₀
π₂ = 0.486π₁
π₃ = 0.229π₂
π₀ + π₁ + π₂ + π₃ = 1
得到:
π₀ ≈ 0.4572, π₁ ≈ 0.3397, π₂ ≈ 0.1651, π₃ ≈ 0.0378
平均暴击率为各状态暴击概率的加权和:
{平均暴击率} = 0.257π₀ + 0.514π₁ + 0.771π₂ + 1.0π₃ ≈ 45.74%
按照该机制,实际平均暴击率约为 45.7%。

概率补偿的数学表达
与面板上的暴击率存在一定的差距,但是通过概率补偿,我们可以明显看到它避免了极端数据的出现:降低第一次暴击的概率,一定情况下避免了“刀刀烈火”的出现(所以S8的JackeyLove向前闪现的四下暴击真是难得);而同时增大后面攻击的暴击概率,避免了死活打不出暴击的情况。
尽管实际的暴击率低于面板上的,但是你的游戏体验得到了保障。
“叽里咕噜说啥呢,我玩百爆的😋😋”
概率补偿的应用不止于游戏中的数值计算:抽卡,装备强化,掉落机制等等机制中都能见其身影。
同时针对不同机制需求,概率补偿得具体形式也有不同侧重的分化:递增型概率补偿(刚才已经提过),保底机制(Hard Pity,设置绝对上限,失败次数达到阈值后强制成功),衰减型补偿(反向调控,连续成功后降低概率,防止过度收益),动态平滑算法(如PRD伪随机,通过数学公式(如马尔可夫链)动态调整概率,使结果分布更接近“人类直觉”),有机会我们再单独讨论。
从体验上来说,玩家对“公平性”的感知比数学真实更重要(至理),人的感知有限,10%暴击率若连续10次未暴击,会被认为“虚假”。“概率补偿”通过巧妙的算法,实现了一定程度的“数学真实”与“玩家体验”的平衡。让随机性更好地服务于游戏。
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com














