2月18日,今天大模型领域又迎来新动向,马斯克在今天中午发布了Grok-3大模型,跟上DeepSeek和OpenAI的步伐,引入了“思维链”推理机制,同时在数学、科学和代码生成等领域表现出色,消耗了大约20万块英伟达GPU训练而成,测试数据显示Grok-3性能已经媲美甚至超越DeepSeek等竞争对手!与此同时,DeepSeek也在今天发布了一篇全新的技术论文NSA!

马斯克旗下人工智能公司xAI在去年8月份,发布了 Grok-2 大模型早期预览版,随后在12月向X平台上的所有用户免费推出新版 Grok-2 模型;在短短半年时间过后,马斯克再推出了Grok 3的早期预览版,Grok 3被视作对OpenAI o3-mini和DeepSeek-R1的回应。
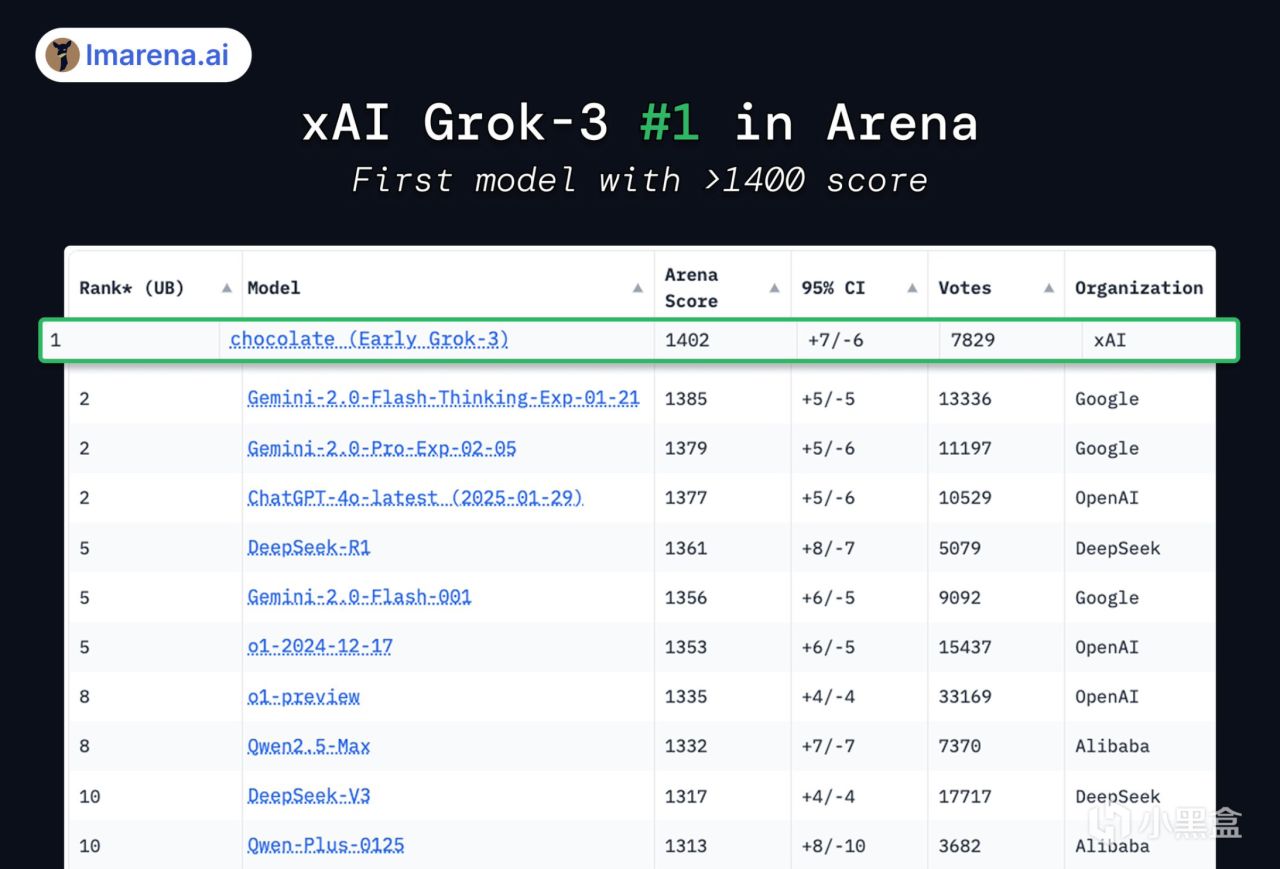
从AI基准测试开放平台lmarena.ai的数据显示,Grok-3(代号chocolate)在Arena排行榜上拿下了第一,成为有史以来第一个获得超过1400分的模型!
马斯克声称,Grok-3在AIME和GPQA等基准测试中,击败了市面上包括OpenAI o3-mini、o1、DeepSeek-R1和Germini-2等在内的所有模型。

OpenAI联合创始人Andrej Karpathy在体验后表示,Grok-3 + Thinking的感觉与ChatGPT的o1-pro差不多,略好于DeepSeek-R1和谷歌的Gemini 2.0 Flash Thinking。

不过在发布会之后,有用户发现Grok-3在特定领域的表现存在问题,比如有直播主(爱迪生玩游戏)测试《流放之路2》游戏时,相关问题错误频出,另有用户测试发现Grok-3在经典的多边形小球编程问题上也出现了错误。

马斯克在直播时透露,Grok 3训练过程累计消耗20万块英伟达GPU,训练在xAI公司的数据中心完成。马斯克同时还介绍Grok之后会陆续上线语音交互多模态功能,并且xAI还将成立AI游戏工作室。

这次直播过程中,马斯克旁边站在C位的是两位华人科学家,分别是多伦多大学助教Jimmy Ba和xAI联合创始人吴宇怀,其中Jimmy Ba是诺奖、图灵奖得主辛顿的学生,吴宇怀初中在杭州建兰中学就读,后来转到加拿大读高中,在多伦多大学、斯坦福大学完成学业,先后在DeepMind和OpenAI实习,后来与马斯克一起成立了xAI。
今天DeepSeek之后也发布了一篇关于NSA的纯技术论文报告,NSA通过针对现代硬件的优化设计,在提升推理速度的同时降低预训练成本且不牺牲性能。在通用基准测试、长上下文任务以及基于指令的推理中,NSA的表现可媲美甚至超越全注意力模型。

比如在8卡A100计算集群上,NSA的前向传播和反向传播速度分别比全注意力快9倍和6倍,在处理64k长度的序列时,NSA在解码、前向传播和反向传播等各个阶段都实现了显著的速度提升,最高可达11.6倍,NSA的推出为AI模型的长上下文训练带来了新的可能性,这篇论文署名还有DeepSeek的创始人梁文锋!随着DS的入场,今年的AI大模型领域竞争也格外激烈,开源仍然是当下的趋势,马斯克也宣布当Grok 3成熟稳定后,将会开源Grok 2,算是半开源(如开)。

更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com














