上週五,稚暉君不是在微博淺淺預告了一波 “ 好東西 ” 嘛。
這不剛週一,智元機器人馬上就把熱乎的抬上來了。
機器人給你端茶倒水、煮咖啡。

把麪包放進麪包機、給烤好的麪包塗抹果醬,再把麪包端到你面前,整套動作一氣呵成。

還能在公司當前臺,充當一把迎賓。

就是吧,見多了各種人形機器人的視頻之後,世超對這種程度的展示,已經見怪不怪了。
這麼說吧,這個基座大模型,讓困擾了人形機器人許久的數據匱乏、泛化能力差的問題,又有了更高效的解法。
大夥兒可能也知道,現階段的人形機器人之所以看起來很拉胯,很重要的原因之一,就是缺乏高質量的數據。
而獲得這些數據的成本,同樣也非常高。
爲了解決這個行業難題,去年底,智元機器人就已經開源了百萬真機數據集 AgiBot World 。

AgiBot World 的數據都來自於智元的數據採集工廠,裏面搭了不少模擬真實場景,數據採集師每天的任務,就是教機器人怎麼執行某項任務。
根據官方的說法, AgiBot World 涵蓋了超過 100 萬條軌跡、 217 個任務和 106 個場景。但即便是這個量級的數據,對於機器人來說仍然是杯水車薪,而且,也沒辦法解決機器人泛化能力差的問題。
世超去翻了翻智元機器人發佈的論文,簡單用大白話給大夥兒介紹一下,這 ViLLA 到底牛在哪。

首先在數據上, ViLLA 架構就沒那麼挑。
根據官方的介紹, ViLLA 架構是由 VLM ( 多模態大模型 ) 和 MoE ( 混合專家 ) 組成。
傳統的 VLA 架構,結合了 VLM 和端到端的特點,所以這種架構需要大量標註過的真機數據來訓練,又費錢又費力,而且數據量還少。
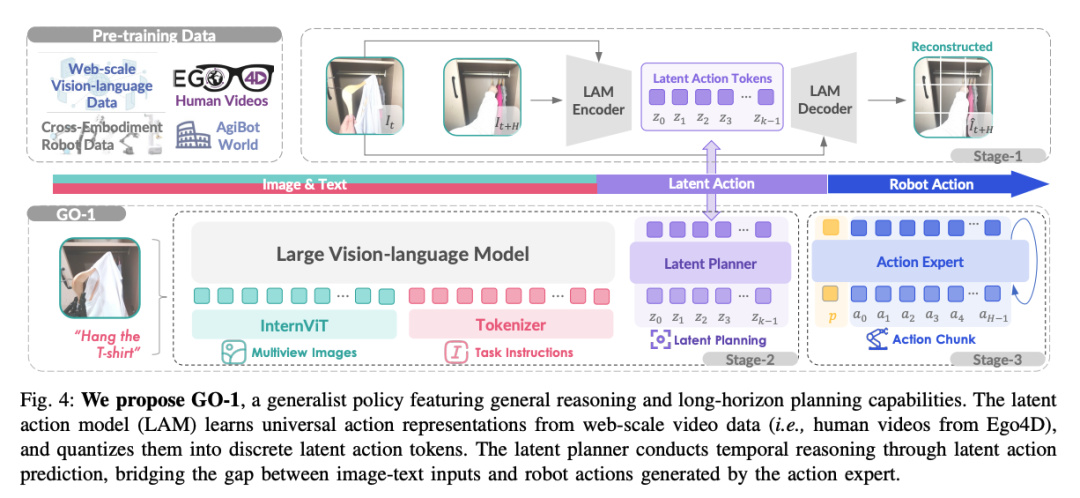
也就是說,基於 GO-1 大模型的機器人,理論上只要 “ 看過 ” 視頻,就能學會相對應的動作。

至於其中的原因,世超覺着很大概率要歸功於 “ 潛在動作 ” ( Latent Actions )。
咱還是拿 VLA 作爲對比, VLA ( Vision Language Action )架構,在執行任務的時候是這麼個流程:輸入圖像和語言指令,機器人再根據這些信息,生成並執行指定動作。
舉個例子,咱們讓機器人( VLA 架構 )做一杯咖啡,機器人能看到咖啡機在哪,也能聽得懂我要它做咖啡。
但是, VLA 架構下的機器人要直接從 “看到了咖啡機 ” “ 聽懂了要做咖啡 ” ,一下子想清楚所有步驟,然後馬上動手,中間沒有思考的過程。
DeepMind 的 VLA 模型 RT-2
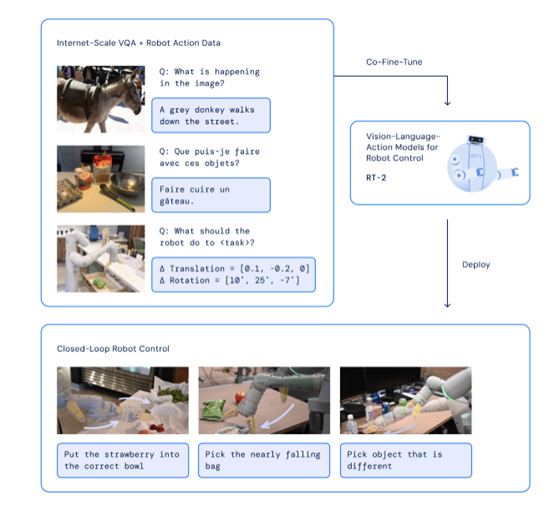
問題就在於,泡咖啡其實中間有很多小步驟,比如找到咖啡豆,打開咖啡機,按下開關,就算是人來了,都得想一下要先幹嘛再幹嘛。
但 ViLLA 架構,引入了兩位 “ 專家 ” :隱式規劃器( Latent Planner )和動作專家( Action Expert )。
這兩位專家不僅能讓機器人想得更多,而且能做的事情也變多了。

專有名詞看不懂沒關係,咱繼續舉例子。
假設現在輸入一段視頻,是一個人拿起杯子喝水。
VLM 多模態大模型會先把視頻處理了,接着潛在動作模型( Latent Action Model ),會把那些複雜的視頻動作,拆解成幾個關鍵步驟,比如 “ 抓取 ” 、 “ 移動 ” 和 “ 喝水 ” 。
但光到這一步還不夠,隱式規劃器( Latent Planner )要繼續把關鍵步驟進行加工,生成更詳細的步驟: “ 抓取(杯子),移動(杯子到嘴邊),飲用 ” 。
所以 ViLLA 架構在執行復雜任務時的表現,要比 VLA 更出色,也更能適應當下人形機器人的訓練需求。
而且世超還注意到, ViLLA 架構並不依賴具體的硬件。
換句話說, VLA 架構是根據特定的機器人本體、特定場景,來生成動作信號,而 ViLLA 架構生成的是 “ 抓取 ” “ 移動 ” 這種通用動作標記,任務泛化能力更好,也更容易遷移到其他機器人平臺。
給大夥兒一句話總結就是,GO-1 讓機器人能從互聯網的人類視頻數據中學習,並且多了拆解任務的能力,提高複雜任務成功率的同時,泛化能力也變強了。
數據不愁,還不挑平臺,這機器人訓練起來可就順手多了。就是不知道這個 GO-1 ,智元會不會選擇繼續開源。
聽說,智元機器人明天還要放出個驚喜,咱們等一手好吧。
撰文:西西
編輯:江江&面線
美編:萱萱
圖片、資料來源:
智元機器人(B站、微博)
智元機器人, VLA 進化到 ViLLA ,智元發佈首個通用具身基座大模型 GO-1
AgiBot World Colosseo : Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems

更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















