2024年的諾貝爾物理學獎,歷史上首次頒給了AI領域的兩位學者,分別是霍普菲爾德和辛頓教授,諾獎致辭表彰兩人爲利用人工神經網絡進行機器學習做出的基礎性發現和發明,近年來機器學習、深度學習、神經網絡、大模型、多模態、智能體、通用人工智能等等成爲AI人工智能領域時髦熱詞,本文從兩位諾獎AI教父的成長史和學術史開始講起,聊聊機器學習是如何發展成今天這個樣子的。

1.最早的AI
提起人工智能,很多人會追溯到計算機科學家艾倫·圖靈,他在50年代提出了著名的圖靈測試,探討機器能否表現出類似人類智能,第一波“學習型機器”研究熱潮開啓,1957年,弗蘭克·羅森布拉特首次提出了感知機(Perceptron)概念,感知機是一種二元分類算法,能夠根據輸入的特徵將數據點分爲兩類,可以視作是模擬生物神經網絡的一種早期嘗試,如今大多數的機器學習/統計學習方法教材都會以感知機作爲初始章節。

感知機模型核心思想完全來源於數學領域,與物理學聯繫倒是不大,核心是通過線性組合輸入特徵,利用一個簡單的激活函數來決定分類結果,感知機可以調整權重來學習,根據誤差不斷更新權重,使模型能夠逐步改進分類精度,但是由於於感知機只能處理線性可分的數據,無法解決異或(XOR)問題。
這次獲得諾獎的約翰·霍普菲爾德生於1933年,感知機提出的這一年,霍普菲爾德剛剛從康奈爾大學獲得物理學博士學位,當時感知機研究熱潮很快擴張到物理領域,霍普菲爾德很敏銳地發現了感知機的缺點,決心從物理學和神經科學等跨學科領域找找靈感。

2.神經網絡
1982年,霍普菲爾德發表了自己第一篇關於計神經網絡相關的論文,題爲Neural networks and physical systems with emergent collective computational abilities,即利用神經網絡模型來模擬物理系統,多個相互作用的神經元(計算節點)在一起工作,產生了超越單個單元能力的計算特性,似乎越多的神經元參與效果就會更好,AI領域潘多拉的魔盒也由此打開。

約翰·霍普菲爾德在論文中首次提出了一種新型的遞歸神經網絡結構,後來被稱爲霍普菲爾德網絡,網絡由多個神經元組成,神經元之間通過加權連接相互作用,論文強調霍普菲爾德網絡有很強的“預測尋址潛力”,即給定輸入數據,即可恢復預測出完整的模式,當時霍普菲爾德預見這種網絡不止適用於物理學,反而在模式識別和數據處理方面的用途更大。
霍普菲爾德網絡確實與物理學有一定的相關性,霍普菲爾德引入了一種能量函數,即通過定義一個能量函數來描述判斷網絡的當前狀態,如今我們將這種函數稱爲激活函數,霍普菲爾德發現引入了這種函數後,網絡會通過降低能量來更新狀態,最終收斂到某個穩定的模式或記憶。
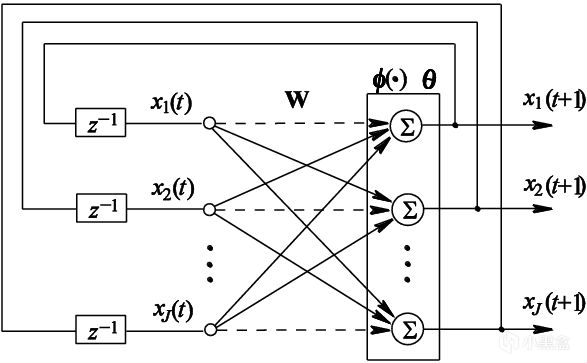
此外,霍普菲爾德網絡還很擅長一些不完整或者是噪聲較大的數據,這意味着霍普菲爾德網絡處理複雜問題時更具魯棒性。因爲霍普菲爾德是物理學出身,論文還有很大篇幅是與物理系統進行類比,討論如果通過物理學中的現象(如相變和臨界現象)來理解和設計神經網絡。
1985年,霍普菲爾德看中了霍普菲爾德網絡的動態特性,繼續模擬神經網絡去解決連續時間動力學的離散優化問題,霍普菲爾德找到了一種隨機優化算法,讓系統即使是初始階段接受噪聲較大的數據,也能探索到更廣泛的解空間,有點像模擬退火,通過降低溫度讓系統趨向於更穩定的狀態,最終收斂到全局優化解,霍普菲爾德網絡在旅行商問題、圖着色問題上表現很好,展現出神經網絡在解決實際應用中的潛力。

3.神經網絡 VS 專家系統
霍普菲爾德網絡裏神經網絡結構的潛力,很快被我們的第二位主角傑弗裏·辛頓發現,辛頓出生於1947年,本科畢業於劍橋大學,拿的是實驗心理學學位,霍普菲爾德網絡推出的時候,辛頓剛剛獲得愛丁堡大學人工智能學博士學位,他發現霍普菲爾德網絡還有很多侷限,比如容易陷入局部極小值,而無法找到全局最優解,解決一些複雜優化問題時,網絡可能會停留在一個次優解上。
另一點是霍普菲爾德網絡的規模和存儲問題,網絡大小受限,過多的模式會導致網絡的計算節點相互干擾,同時網絡的權重依賴於經驗法則,缺乏系統化的訓練過程,雖然可以通過對稱權重來設置網絡,但在實際應用中,確定最佳權重值依然很難做到;第三點,儘管霍普菲爾德網絡具有一定的容錯性,但是對於高噪聲或者模糊輸入時,性能會顯著下降;第四點就是計算資源問題,隨着神經元計算節點變多,連接數量增加,計算資源的需求也會顯著增加。
當然,在最後計算資源這一點上,老黃最後提出了終極解決方案,但是在80年代計算資源仍是大問題,所以還需要從網絡結構方向着手改變。但是辛頓還面臨另一項麻煩,感知機熱度下滑後,按照我們的認知,學術界應該推進到神經網絡方向,但是在實際發展的過程中,道路還是曲折的,70年代還盛行一種名叫“專家系統”的研究方向,即基於手工編碼的知識和邏輯規則來做出推斷,在很多僵硬的領域表現確實很好,但是擴展性和靈活性極差。
一種是刻板刻眼的專家系統,另一種是接近於黑箱、決策過程不太具有解釋性的神經網絡,對於需要高可解釋性的領域,比如醫療等等,看起來專家系統是更好的方向,但辛頓在博士畢業後投入到更小衆的神經網絡,誰也沒想到,辛頓的選擇促成了一個時代的出現,雖然大家很喜歡說沒有牛頓也有馬頓豬頓,但是辛頓的某些靈光一閃,很有可能直接加速了AI時代的到來,換句話說,如果不是辛頓等一代人的堅持,AI發展之路完全有可能偏向專家系統,最終進入死衚衕陷入停滯,直到若干年後再有辛頓這樣的人出現......
4.BP算法-神經網絡的訓練
回到那個年代,感知機道路走到盡頭,號稱人工智能寒冬的時代開啓,學者們不太願意在一個已經被證明沒有前途的領域做研究,繼續來看辛頓到底做了什麼。1985年,霍普菲爾德教授對他的神經網絡做了進一步優化;1986年,辛頓與大衛·魯梅爾哈特、羅納德·威廉姆斯一起提出了著名的BP反向傳播算法,這個算法的提出可以說是神經網絡研究中一個極度重要的里程碑,如今聊AI熱詞的自媒體有一大堆,但是願意認認真真從BP開始講起的很少。
BP算法的基礎可以追溯到70年代,前面說到1957年的感知機引發了一段感知機研究熱,但由於感知機只能解決線性可分問題,方向遇到阻力,一些學者不願意放棄感知機,開始嘗試通過增加隱藏層來擴展能力,也就是我們常常說的hidden layer,學者們開始關注探討多層感知機。
70年代末期,大衛·魯梅爾哈特開始搭建輸入層-隱藏層-輸出層結構,探索如何減少輸出層向輸入層傳播的誤差,從而優化多層網絡的權重,但是他們始終無法找到好方法,辛頓聯想到了微積分的鏈式法則(Chain Rule),鏈式法則主要是用於計算複合函數的導數,詳見我在20年寫的微積分篇。

神經網絡已經發展到了多層結構,輸入層-隱藏層-輸出層,輸出層的輸出依賴於前一層的輸出,前一層的輸出又依賴於更前一層的輸出,使用鏈式法則,辛頓可以從輸出層向輸入層反向傳播誤差,並逐層計算每個權重的梯度,如此一來,神經網絡有了具體方法來高效計算每個權重的梯度,避免逐一計算每個輸入對損失的影響,大大提高計算效率。
可以說,在反向傳播算法提出來以前,神經網絡只能說空有結構,無法推廣到多層模型,計算資源和算法都是限制,BP反向傳播首次使得訓練深度神經網絡成爲可能,不過一開始,辛頓還沒辦法擴展很多層的神經網絡,所以先以單隱層神經網絡爲例,再逐漸擴展到多層。
有了BP算法,機器學習的深度被大大擴展,神經網絡逐漸開始成爲顯學,一些傳統的機器學習方法逐漸沒落,接下來大家主要是兩個思路去研究神經網絡,一種是從結構入手,如何讓更多層的神經網絡成爲可能,另一種是從應用入手,看看拿神經網絡做預測還是做生成模型,而辛頓恰好在兩個方面都有基石級的成果。
5.受限制玻爾茲曼機-無監督學習
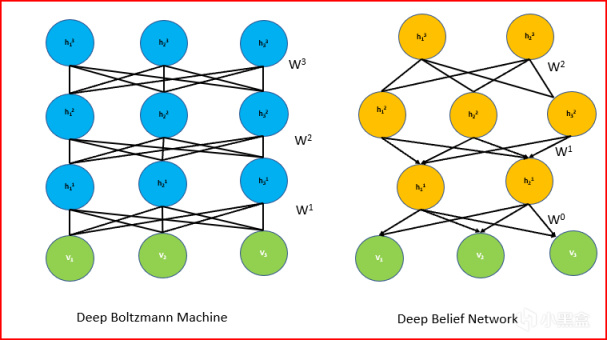
先聊大家最感興趣的生成模型,如今的GPT確實也是基於Transfomer的生成模型,上世紀的80年代,辛頓提出玻爾茲曼機,也是一種神經網絡包含可見層和隱藏層,屬於無監督學習的框架,可見層是輸入數據的節點,每個節點對應輸入數據的一個特徵,隱藏層負責捕捉輸入數據的潛在特徵,每個節點之間的連接都有一個權重,玻爾茲曼機旨在學習數據的概率分佈。
隨後,辛頓也對玻爾茲曼機繼續改進,提出了受限制玻爾茲曼機(Restricted Boltzmann Machine,RBM),與玻爾茲曼機相似,也是由可見層和隱藏層組成,但結構上使得訓練和應用更加高效,RBM特點在於連接方式,可見層和隱藏層之間存在對稱連接,但是可見層的節點之間以及隱藏層的節點之間沒有直接連接,使用梯度下降法來對反向傳播過程中的權重進行更新。

6.人工智能寒冬-辛頓最後的堅持
其實RBM剛推出的時候獲得關注還沒這麼大,畢竟上世紀八十年代九十年代正是人工智能寒冬,僅有辛頓等少數幾人堅持研究,當時多倫多大學的學生很少有人願意跟着辛頓做研究。到了隨着深度學習的興起,辛頓的RBM又被大家重新審視,廣泛應用於特徵學習和數據降維。2006年,辛頓再提出深度信念網絡DBN,DBN也被視作是深度學習的重要前身,由多個受限制玻爾茲曼機(RBM)堆疊而成,每一層的隱藏層都是上一層的可見層,辛頓證明了深層模型可以通過無監督學習有效地進行訓練,大家開始撿起RBM重新研究深度學習。
7.機器學習到深度學習元年-AlexNet
機器學習曾經經歷了非常輝煌的時期,邁克爾·喬丹和學生吳恩達都是機器學習出色學者,但新的時代很快到來。下一個歷史節點是2012年,李飛飛的ImageNet大賽爆火,辛頓教授帶着自己的兩位博士生徒弟,一起參加了李飛飛的比賽,這一年辛頓教授的AlexNet成爲全世界的焦點,以斷崖式優勢贏得ImageNet大賽冠軍,無數學者開始轉向研究層數更深、參數更多的神經網絡。
這一年也讓老黃大受震撼,CUDA轉正成爲英偉達大力發展的王牌,AI專業卡在不久的未來將把英偉達推向人類市值第一公司的寶座。AlexNet得名於辛頓的博士生Alex Krizhevsky,他主要負責神經網絡的架構,而無人在意的角落,辛頓另一位得意門生Ilya Sutskever,主要負責網絡的代碼,經過大量的實踐對比,Ilya選擇了CUDA,命運的齒輪再次轉動。
8.OpenAI的誕生
改變命運的還有Ilya Sutskever,他的名字將被刻在人類歷史。
2012年,Ilya從老師辛頓那裏博士畢業後到谷歌工作,這同樣得益於辛頓的“騷操作”,2013年辛頓將自己和Alex和Ilya兩位博士生一起,以數千萬美元的高價賣身給谷歌,這也是頭一回有深度學習的大牛主動這麼幹,谷歌也樂得千金買馬骨,關於這次拍賣還有很多有趣的故事,以後有機會再補充。
重點倒不在谷歌這段經歷,Ilya幹了三年就跳槽到了一家初創公司,與其他三人一起成爲公司的聯合創始人,另外三個人我們也很熟悉,分別是伊隆·馬斯克、山姆·奧特曼和格雷格·布羅克曼,這家公司的名字就是OpenAI。當時也沒啥人看好這家公司,馬斯克往往是大嘴巴不怎麼不懂AI的形象,奧特曼只寫了幾年代碼就全職做孵化,布羅克曼是支付平臺stripe的CTO,僅有Ilya是真業內大佬,再加上是辛頓學生名師光環,所以Ilya成爲OpenAI聯合創始人兼唯一的首席科學家。

9.質疑OpenAI
Ilya的故事還遠未結束,辛頓雖然貴爲AI教父,但是對OpenAI保持高度警惕,就在GPT4剛發佈不久,辛頓還非常樂觀認爲GPT4對人類社會有益,但很快他的樂觀逐漸變成擔憂,“我對自己畢生的工作,感到非常後悔。我找了一個藉口來安慰自己,即便我沒有做這些工作,依然有其他人會做。”
但是我們再回歸辛頓所做的成果,不僅很多,而且基本上都是開創性成果,步步踩在AI發展最早、最關鍵的歷史節點,並且還是那個年代僅有的幾個堅持做神經網絡的學者,雖然AI發展到今天是很多人研究的成果集合,但辛頓無疑是其中最傑出最關鍵的一個,目前辛頓也是整個計算機領域引用量最多的,高達85萬,而且辛頓還不是那種喜歡掛通訊水引用量的人,每年發表的文章也就十篇左右。

10.離開谷歌,AI的未來?
2023年,辛頓從谷歌離開,對自己爲人工智能技術發展帶來的負面影響進行深刻反思,一方面他的成果確實大大推動了深度學習的發展,給人類社會帶來了許多便利,但辛頓依然非常自責,因爲沒有早一點重視AI帶來的負面影響。
如今,辛頓正在全球範圍內呼籲有限度地發展AI,超級AI非常危險未來可能會失控,同時AI的廣泛應用可能會導致越來越多的工作被自動化替代,加劇失業問題和社會不平等問題,辛頓更加擔心的還有AI的濫用,比如用於監控和軍事用途,辛頓提到AI技術可能會被濫用來實現更精密的武器系統、信息操縱和全球監控,危害到人類的基本權利和自由。

作爲大家口中的AI教父,辛頓不僅有深厚的學術功底和技術背景,同樣展現出極強的人文關懷和理性思考,不愧爲一代大師,辛頓的家族同樣很有故事,辛頓的曾祖父是數學家和最早的科幻作家,曾祖母是布爾的女兒(布爾代數的那個布爾),辛頓父親霍華德·辛頓是劍橋大學教授、英國著名的昆蟲學家,霍華德·辛頓有一個弟弟和一個妹妹,分別是威廉·辛頓和瓊·辛頓,妹妹瓊·辛頓是核物理學家,曾參與曼哈頓計劃,在洛斯阿拉莫斯擔任費米的助手,威廉·辛頓和瓊·辛頓兩人均在上世紀40年代來到中國,並且拿到綠卡長期定居......
機器學習基礎:
深度學習入門——圖靈獎AI三巨頭
AI編年史——深度學習的發展史(收藏向)
AI編年史2——GPT是如何誕生的?
AI學術巨佬——何愷明,從遊戲中獲得論文靈感
AI領軍人物——孫劍,重劍無鋒的經典之作
AI傳奇巨佬——湯曉鷗,中國人工智能領袖人物!
AI女神李飛飛——從成都七中,到頂級AI科學家!
山姆·奧特曼——從遊戲編程,到OpenAI之父!
張益唐——黎曼猜想,華人數學家再創重大突破!
B站大學——線代不掛科,MIT傳奇教授的最後一課!
微軟免費AI課程——18節課,初學者入門大模型!
機器學習——科學家周志華,成爲中國首位AI頂會掌門人!
機器學習入門——數學基礎(積分篇)
機器學習入門——數學基礎(代數篇)
機器學習入門——數學基礎(貝葉斯篇)
更多遊戲資訊請關註:電玩幫遊戲資訊專區
電玩幫圖文攻略 www.vgover.com















