2024年的诺贝尔物理学奖,历史上首次颁给了AI领域的两位学者,分别是霍普菲尔德和辛顿教授,诺奖致辞表彰两人为利用人工神经网络进行机器学习做出的基础性发现和发明,近年来机器学习、深度学习、神经网络、大模型、多模态、智能体、通用人工智能等等成为AI人工智能领域时髦热词,本文从两位诺奖AI教父的成长史和学术史开始讲起,聊聊机器学习是如何发展成今天这个样子的。

1.最早的AI
提起人工智能,很多人会追溯到计算机科学家艾伦·图灵,他在50年代提出了著名的图灵测试,探讨机器能否表现出类似人类智能,第一波“学习型机器”研究热潮开启,1957年,弗兰克·罗森布拉特首次提出了感知机(Perceptron)概念,感知机是一种二元分类算法,能够根据输入的特征将数据点分为两类,可以视作是模拟生物神经网络的一种早期尝试,如今大多数的机器学习/统计学习方法教材都会以感知机作为初始章节。

感知机模型核心思想完全来源于数学领域,与物理学联系倒是不大,核心是通过线性组合输入特征,利用一个简单的激活函数来决定分类结果,感知机可以调整权重来学习,根据误差不断更新权重,使模型能够逐步改进分类精度,但是由于于感知机只能处理线性可分的数据,无法解决异或(XOR)问题。
这次获得诺奖的约翰·霍普菲尔德生于1933年,感知机提出的这一年,霍普菲尔德刚刚从康奈尔大学获得物理学博士学位,当时感知机研究热潮很快扩张到物理领域,霍普菲尔德很敏锐地发现了感知机的缺点,决心从物理学和神经科学等跨学科领域找找灵感。

2.神经网络
1982年,霍普菲尔德发表了自己第一篇关于计神经网络相关的论文,题为Neural networks and physical systems with emergent collective computational abilities,即利用神经网络模型来模拟物理系统,多个相互作用的神经元(计算节点)在一起工作,产生了超越单个单元能力的计算特性,似乎越多的神经元参与效果就会更好,AI领域潘多拉的魔盒也由此打开。

约翰·霍普菲尔德在论文中首次提出了一种新型的递归神经网络结构,后来被称为霍普菲尔德网络,网络由多个神经元组成,神经元之间通过加权连接相互作用,论文强调霍普菲尔德网络有很强的“预测寻址潜力”,即给定输入数据,即可恢复预测出完整的模式,当时霍普菲尔德预见这种网络不止适用于物理学,反而在模式识别和数据处理方面的用途更大。
霍普菲尔德网络确实与物理学有一定的相关性,霍普菲尔德引入了一种能量函数,即通过定义一个能量函数来描述判断网络的当前状态,如今我们将这种函数称为激活函数,霍普菲尔德发现引入了这种函数后,网络会通过降低能量来更新状态,最终收敛到某个稳定的模式或记忆。
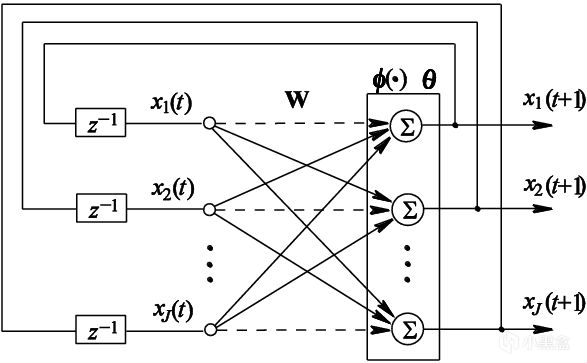
此外,霍普菲尔德网络还很擅长一些不完整或者是噪声较大的数据,这意味着霍普菲尔德网络处理复杂问题时更具鲁棒性。因为霍普菲尔德是物理学出身,论文还有很大篇幅是与物理系统进行类比,讨论如果通过物理学中的现象(如相变和临界现象)来理解和设计神经网络。
1985年,霍普菲尔德看中了霍普菲尔德网络的动态特性,继续模拟神经网络去解决连续时间动力学的离散优化问题,霍普菲尔德找到了一种随机优化算法,让系统即使是初始阶段接受噪声较大的数据,也能探索到更广泛的解空间,有点像模拟退火,通过降低温度让系统趋向于更稳定的状态,最终收敛到全局优化解,霍普菲尔德网络在旅行商问题、图着色问题上表现很好,展现出神经网络在解决实际应用中的潜力。

3.神经网络 VS 专家系统
霍普菲尔德网络里神经网络结构的潜力,很快被我们的第二位主角杰弗里·辛顿发现,辛顿出生于1947年,本科毕业于剑桥大学,拿的是实验心理学学位,霍普菲尔德网络推出的时候,辛顿刚刚获得爱丁堡大学人工智能学博士学位,他发现霍普菲尔德网络还有很多局限,比如容易陷入局部极小值,而无法找到全局最优解,解决一些复杂优化问题时,网络可能会停留在一个次优解上。
另一点是霍普菲尔德网络的规模和存储问题,网络大小受限,过多的模式会导致网络的计算节点相互干扰,同时网络的权重依赖于经验法则,缺乏系统化的训练过程,虽然可以通过对称权重来设置网络,但在实际应用中,确定最佳权重值依然很难做到;第三点,尽管霍普菲尔德网络具有一定的容错性,但是对于高噪声或者模糊输入时,性能会显著下降;第四点就是计算资源问题,随着神经元计算节点变多,连接数量增加,计算资源的需求也会显著增加。
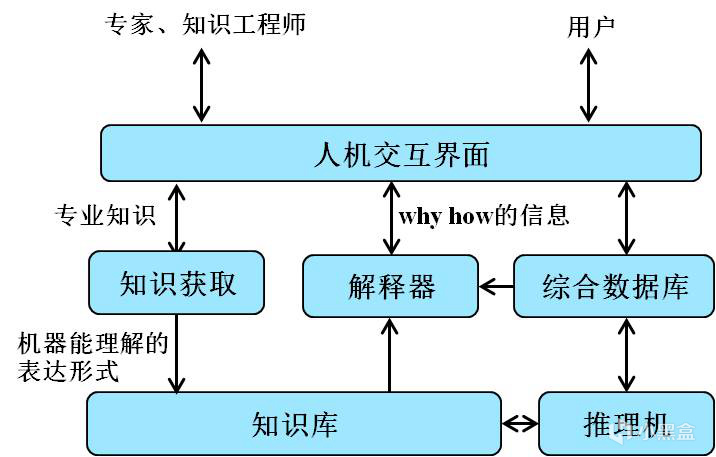
当然,在最后计算资源这一点上,老黄最后提出了终极解决方案,但是在80年代计算资源仍是大问题,所以还需要从网络结构方向着手改变。但是辛顿还面临另一项麻烦,感知机热度下滑后,按照我们的认知,学术界应该推进到神经网络方向,但是在实际发展的过程中,道路还是曲折的,70年代还盛行一种名叫“专家系统”的研究方向,即基于手工编码的知识和逻辑规则来做出推断,在很多僵硬的领域表现确实很好,但是扩展性和灵活性极差。
一种是刻板刻眼的专家系统,另一种是接近于黑箱、决策过程不太具有解释性的神经网络,对于需要高可解释性的领域,比如医疗等等,看起来专家系统是更好的方向,但辛顿在博士毕业后投入到更小众的神经网络,谁也没想到,辛顿的选择促成了一个时代的出现,虽然大家很喜欢说没有牛顿也有马顿猪顿,但是辛顿的某些灵光一闪,很有可能直接加速了AI时代的到来,换句话说,如果不是辛顿等一代人的坚持,AI发展之路完全有可能偏向专家系统,最终进入死胡同陷入停滞,直到若干年后再有辛顿这样的人出现......
4.BP算法-神经网络的训练
回到那个年代,感知机道路走到尽头,号称人工智能寒冬的时代开启,学者们不太愿意在一个已经被证明没有前途的领域做研究,继续来看辛顿到底做了什么。1985年,霍普菲尔德教授对他的神经网络做了进一步优化;1986年,辛顿与大卫·鲁梅尔哈特、罗纳德·威廉姆斯一起提出了著名的BP反向传播算法,这个算法的提出可以说是神经网络研究中一个极度重要的里程碑,如今聊AI热词的自媒体有一大堆,但是愿意认认真真从BP开始讲起的很少。
BP算法的基础可以追溯到70年代,前面说到1957年的感知机引发了一段感知机研究热,但由于感知机只能解决线性可分问题,方向遇到阻力,一些学者不愿意放弃感知机,开始尝试通过增加隐藏层来扩展能力,也就是我们常常说的hidden layer,学者们开始关注探讨多层感知机。
70年代末期,大卫·鲁梅尔哈特开始搭建输入层-隐藏层-输出层结构,探索如何减少输出层向输入层传播的误差,从而优化多层网络的权重,但是他们始终无法找到好方法,辛顿联想到了微积分的链式法则(Chain Rule),链式法则主要是用于计算复合函数的导数,详见我在20年写的微积分篇。

神经网络已经发展到了多层结构,输入层-隐藏层-输出层,输出层的输出依赖于前一层的输出,前一层的输出又依赖于更前一层的输出,使用链式法则,辛顿可以从输出层向输入层反向传播误差,并逐层计算每个权重的梯度,如此一来,神经网络有了具体方法来高效计算每个权重的梯度,避免逐一计算每个输入对损失的影响,大大提高计算效率。
可以说,在反向传播算法提出来以前,神经网络只能说空有结构,无法推广到多层模型,计算资源和算法都是限制,BP反向传播首次使得训练深度神经网络成为可能,不过一开始,辛顿还没办法扩展很多层的神经网络,所以先以单隐层神经网络为例,再逐渐扩展到多层。
有了BP算法,机器学习的深度被大大扩展,神经网络逐渐开始成为显学,一些传统的机器学习方法逐渐没落,接下来大家主要是两个思路去研究神经网络,一种是从结构入手,如何让更多层的神经网络成为可能,另一种是从应用入手,看看拿神经网络做预测还是做生成模型,而辛顿恰好在两个方面都有基石级的成果。
5.受限制玻尔兹曼机-无监督学习
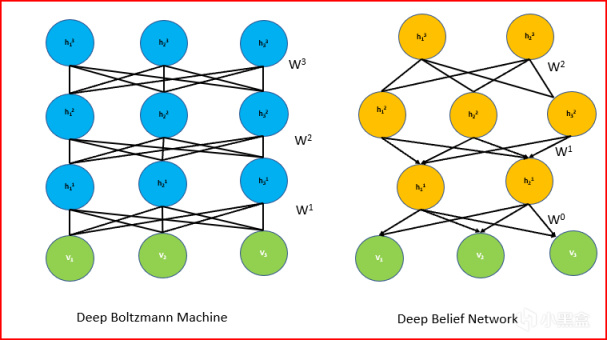
先聊大家最感兴趣的生成模型,如今的GPT确实也是基于Transfomer的生成模型,上世纪的80年代,辛顿提出玻尔兹曼机,也是一种神经网络包含可见层和隐藏层,属于无监督学习的框架,可见层是输入数据的节点,每个节点对应输入数据的一个特征,隐藏层负责捕捉输入数据的潜在特征,每个节点之间的连接都有一个权重,玻尔兹曼机旨在学习数据的概率分布。
随后,辛顿也对玻尔兹曼机继续改进,提出了受限制玻尔兹曼机(Restricted Boltzmann Machine,RBM),与玻尔兹曼机相似,也是由可见层和隐藏层组成,但结构上使得训练和应用更加高效,RBM特点在于连接方式,可见层和隐藏层之间存在对称连接,但是可见层的节点之间以及隐藏层的节点之间没有直接连接,使用梯度下降法来对反向传播过程中的权重进行更新。

6.人工智能寒冬-辛顿最后的坚持
其实RBM刚推出的时候获得关注还没这么大,毕竟上世纪八十年代九十年代正是人工智能寒冬,仅有辛顿等少数几人坚持研究,当时多伦多大学的学生很少有人愿意跟着辛顿做研究。到了随着深度学习的兴起,辛顿的RBM又被大家重新审视,广泛应用于特征学习和数据降维。2006年,辛顿再提出深度信念网络DBN,DBN也被视作是深度学习的重要前身,由多个受限制玻尔兹曼机(RBM)堆叠而成,每一层的隐藏层都是上一层的可见层,辛顿证明了深层模型可以通过无监督学习有效地进行训练,大家开始捡起RBM重新研究深度学习。
7.机器学习到深度学习元年-AlexNet
机器学习曾经经历了非常辉煌的时期,迈克尔·乔丹和学生吴恩达都是机器学习出色学者,但新的时代很快到来。下一个历史节点是2012年,李飞飞的ImageNet大赛爆火,辛顿教授带着自己的两位博士生徒弟,一起参加了李飞飞的比赛,这一年辛顿教授的AlexNet成为全世界的焦点,以断崖式优势赢得ImageNet大赛冠军,无数学者开始转向研究层数更深、参数更多的神经网络。
这一年也让老黄大受震撼,CUDA转正成为英伟达大力发展的王牌,AI专业卡在不久的未来将把英伟达推向人类市值第一公司的宝座。AlexNet得名于辛顿的博士生Alex Krizhevsky,他主要负责神经网络的架构,而无人在意的角落,辛顿另一位得意门生Ilya Sutskever,主要负责网络的代码,经过大量的实践对比,Ilya选择了CUDA,命运的齿轮再次转动。
8.OpenAI的诞生
改变命运的还有Ilya Sutskever,他的名字将被刻在人类历史。
2012年,Ilya从老师辛顿那里博士毕业后到谷歌工作,这同样得益于辛顿的“骚操作”,2013年辛顿将自己和Alex和Ilya两位博士生一起,以数千万美元的高价卖身给谷歌,这也是头一回有深度学习的大牛主动这么干,谷歌也乐得千金买马骨,关于这次拍卖还有很多有趣的故事,以后有机会再补充。
重点倒不在谷歌这段经历,Ilya干了三年就跳槽到了一家初创公司,与其他三人一起成为公司的联合创始人,另外三个人我们也很熟悉,分别是伊隆·马斯克、山姆·奥特曼和格雷格·布罗克曼,这家公司的名字就是OpenAI。当时也没啥人看好这家公司,马斯克往往是大嘴巴不怎么不懂AI的形象,奥特曼只写了几年代码就全职做孵化,布罗克曼是支付平台stripe的CTO,仅有Ilya是真业内大佬,再加上是辛顿学生名师光环,所以Ilya成为OpenAI联合创始人兼唯一的首席科学家。

9.质疑OpenAI
Ilya的故事还远未结束,辛顿虽然贵为AI教父,但是对OpenAI保持高度警惕,就在GPT4刚发布不久,辛顿还非常乐观认为GPT4对人类社会有益,但很快他的乐观逐渐变成担忧,“我对自己毕生的工作,感到非常后悔。我找了一个借口来安慰自己,即便我没有做这些工作,依然有其他人会做。”
但是我们再回归辛顿所做的成果,不仅很多,而且基本上都是开创性成果,步步踩在AI发展最早、最关键的历史节点,并且还是那个年代仅有的几个坚持做神经网络的学者,虽然AI发展到今天是很多人研究的成果集合,但辛顿无疑是其中最杰出最关键的一个,目前辛顿也是整个计算机领域引用量最多的,高达85万,而且辛顿还不是那种喜欢挂通讯水引用量的人,每年发表的文章也就十篇左右。

10.离开谷歌,AI的未来?
2023年,辛顿从谷歌离开,对自己为人工智能技术发展带来的负面影响进行深刻反思,一方面他的成果确实大大推动了深度学习的发展,给人类社会带来了许多便利,但辛顿依然非常自责,因为没有早一点重视AI带来的负面影响。
如今,辛顿正在全球范围内呼吁有限度地发展AI,超级AI非常危险未来可能会失控,同时AI的广泛应用可能会导致越来越多的工作被自动化替代,加剧失业问题和社会不平等问题,辛顿更加担心的还有AI的滥用,比如用于监控和军事用途,辛顿提到AI技术可能会被滥用来实现更精密的武器系统、信息操纵和全球监控,危害到人类的基本权利和自由。

作为大家口中的AI教父,辛顿不仅有深厚的学术功底和技术背景,同样展现出极强的人文关怀和理性思考,不愧为一代大师,辛顿的家族同样很有故事,辛顿的曾祖父是数学家和最早的科幻作家,曾祖母是布尔的女儿(布尔代数的那个布尔),辛顿父亲霍华德·辛顿是剑桥大学教授、英国著名的昆虫学家,霍华德·辛顿有一个弟弟和一个妹妹,分别是威廉·辛顿和琼·辛顿,妹妹琼·辛顿是核物理学家,曾参与曼哈顿计划,在洛斯阿拉莫斯担任费米的助手,威廉·辛顿和琼·辛顿两人均在上世纪40年代来到中国,并且拿到绿卡长期定居......
机器学习基础:
深度学习入门——图灵奖AI三巨头
AI编年史——深度学习的发展史(收藏向)
AI编年史2——GPT是如何诞生的?
AI学术巨佬——何恺明,从游戏中获得论文灵感
AI领军人物——孙剑,重剑无锋的经典之作
AI传奇巨佬——汤晓鸥,中国人工智能领袖人物!
AI女神李飞飞——从成都七中,到顶级AI科学家!
山姆·奥特曼——从游戏编程,到OpenAI之父!
张益唐——黎曼猜想,华人数学家再创重大突破!
B站大学——线代不挂科,MIT传奇教授的最后一课!
微软免费AI课程——18节课,初学者入门大模型!
机器学习——科学家周志华,成为中国首位AI顶会掌门人!
机器学习入门——数学基础(积分篇)
机器学习入门——数学基础(代数篇)
机器学习入门——数学基础(贝叶斯篇)
更多游戏资讯请关注:电玩帮游戏资讯专区
电玩帮图文攻略 www.vgover.com














